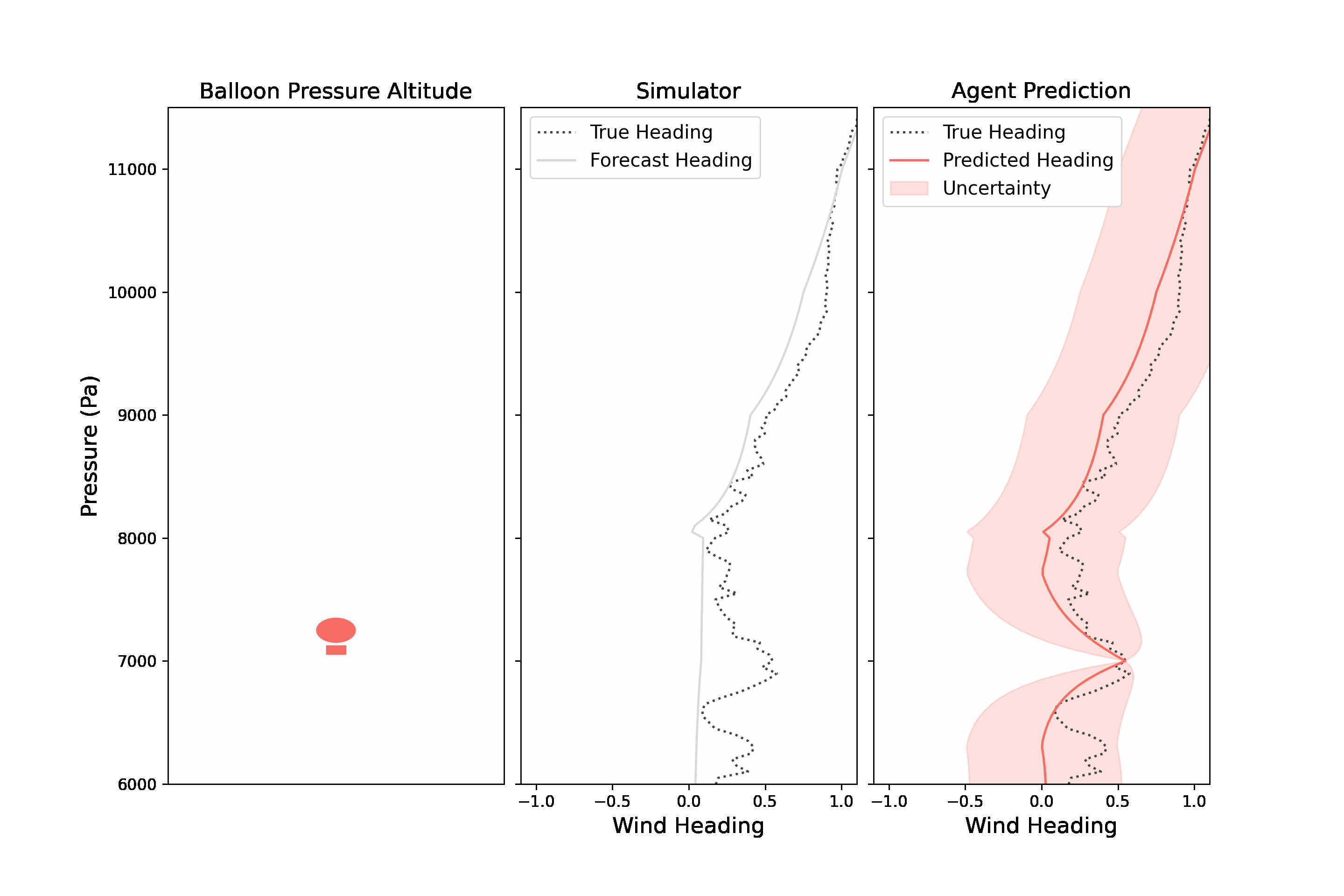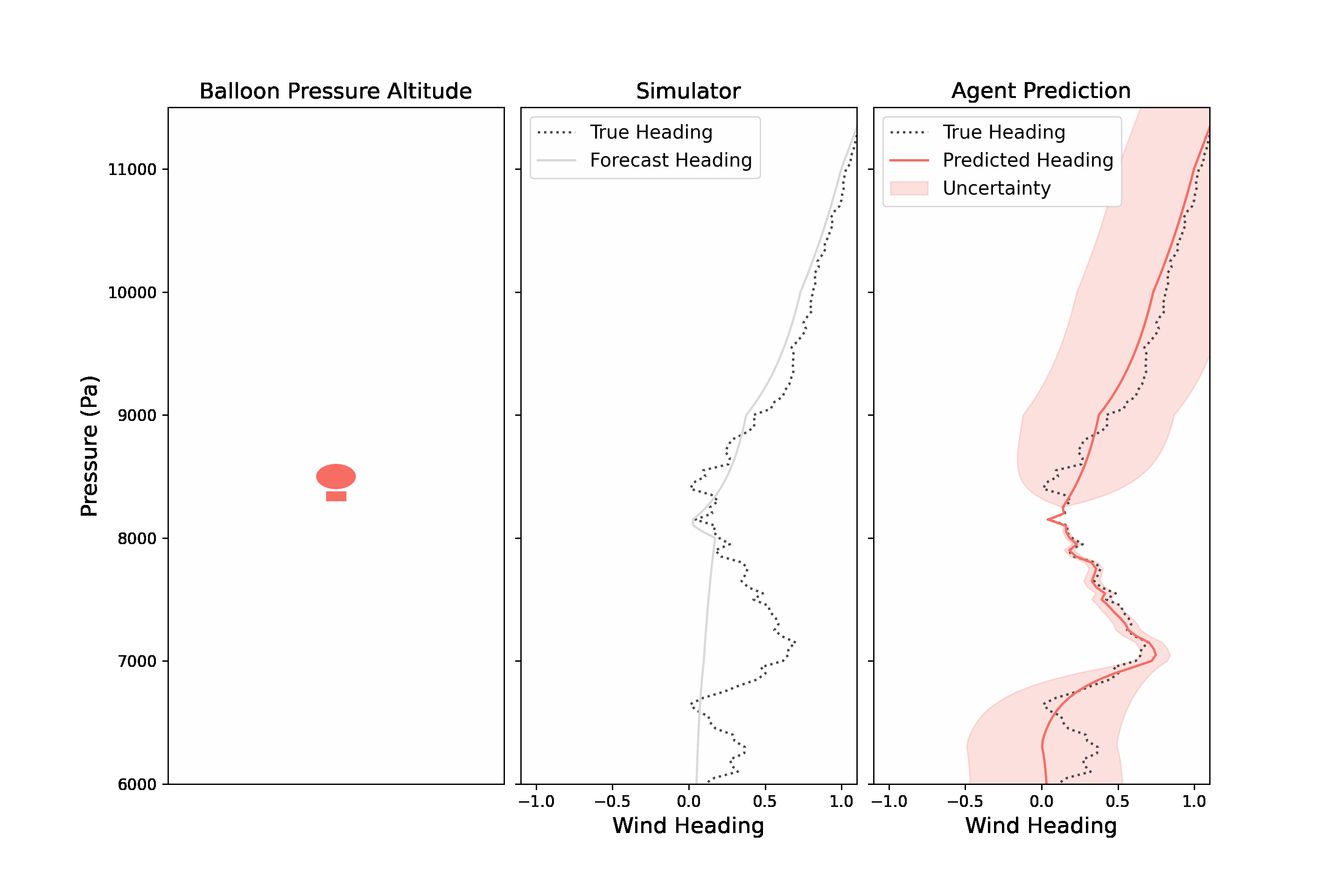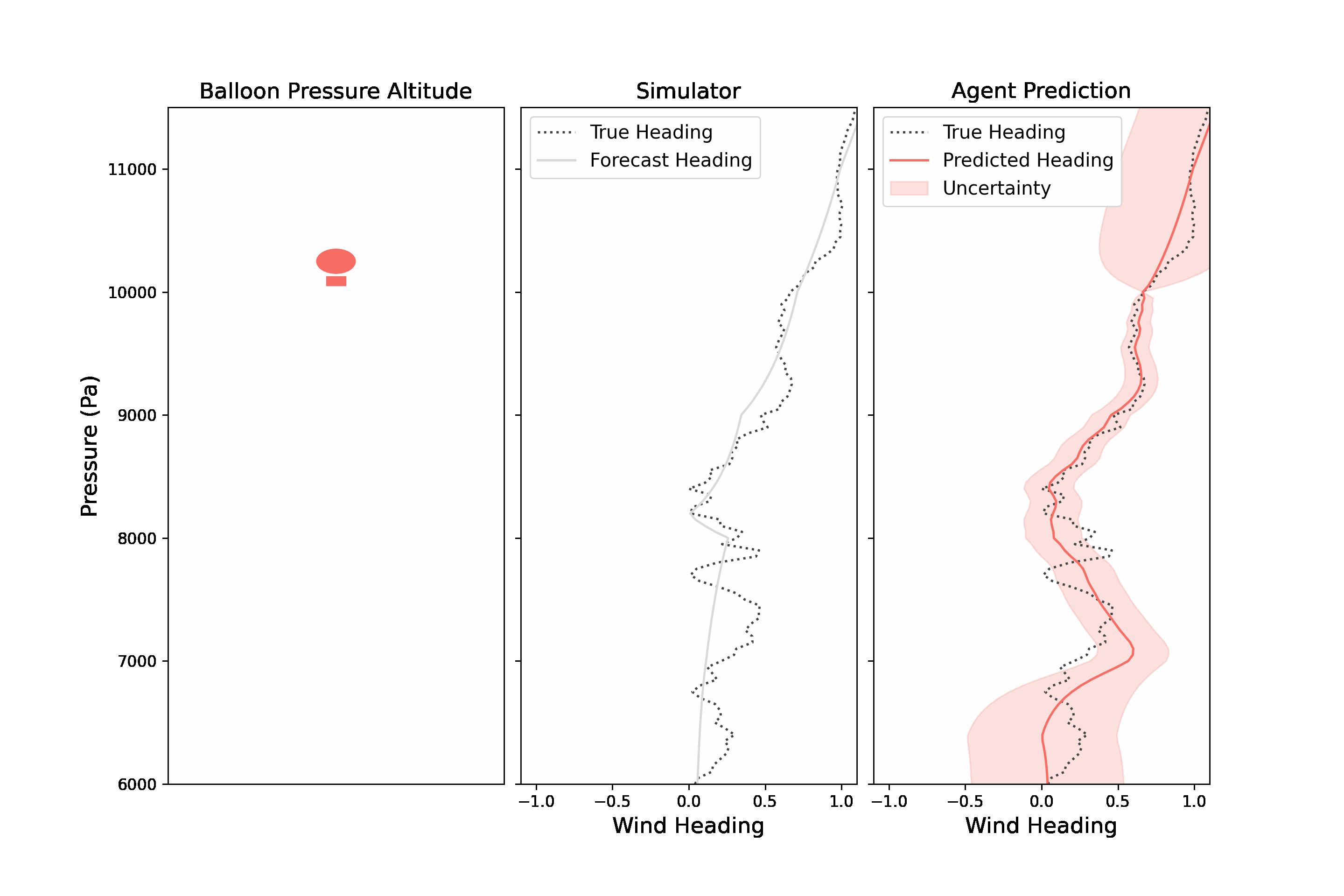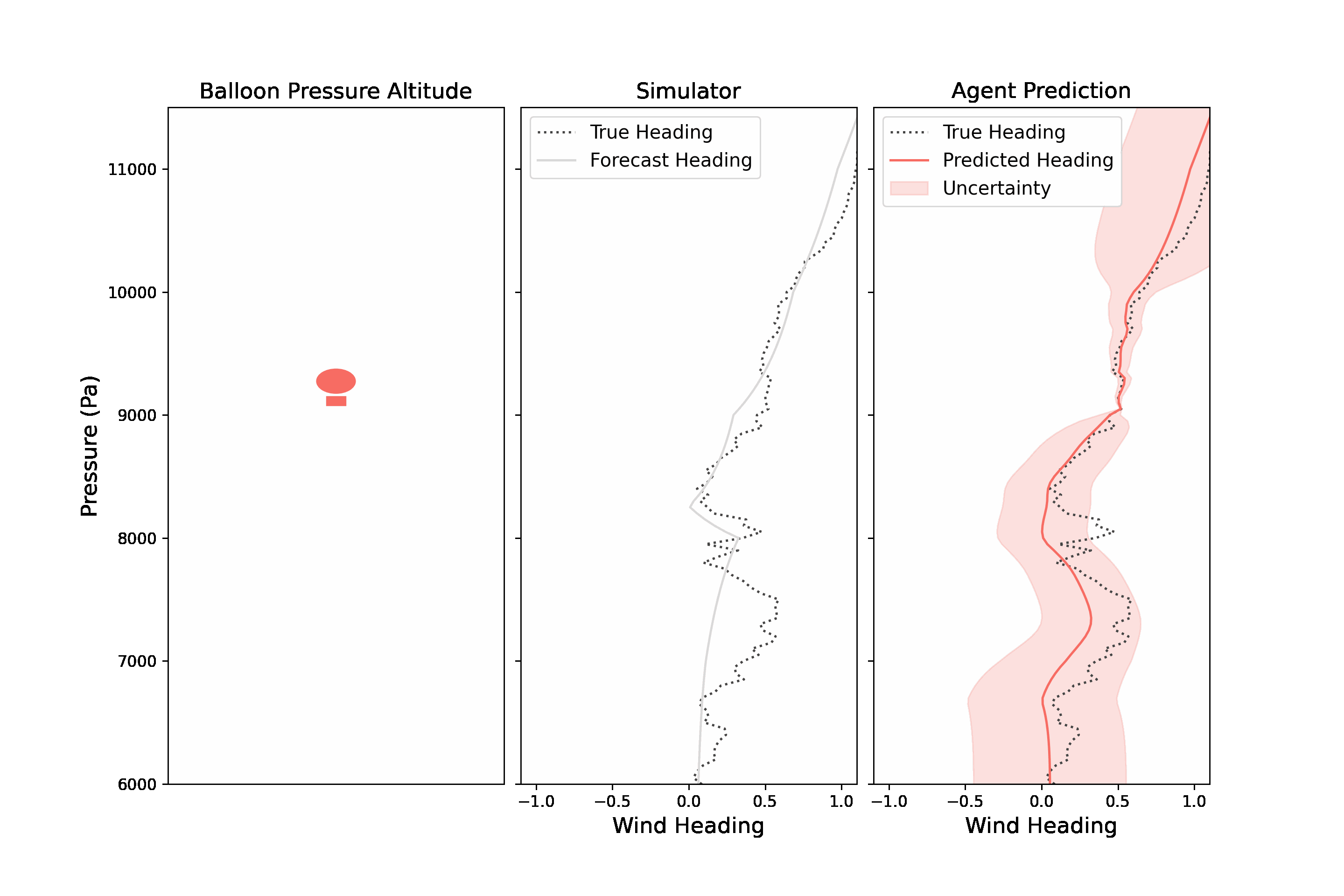
Evolution strategy (ES) is a family of optimization techniques inspired by the ideas of natural selection: a population of candidate solutions are usually evolved over generations to better adapt to an optimization objective. ES has been applied to a variety of challenging decision making problems, such as legged locomotion, quadcopter control, and even power system control.
Compared to gradient-based reinforcement learning (RL) methods like proximal policy optimization (PPO) and soft actor-critic (SAC), ES has several advantages. First, ES directly explores in the space of controller parameters, while gradient-based methods often explore within a limited action space, which indirectly influences the controller parameters. More direct exploration has been shown to boost learning performance and enable large scale data collection with parallel computation. Second, a major challenge in RL is long-horizon credit assignment, e.g., when a robot accomplishes a task in the end, determining which actions it performed in the past were the most critical and should be assigned a greater reward. Since ES directly considers the total reward, it relieves researchers from needing to explicitly handle credit assignment. In addition, because ES does not rely on gradient information, it can naturally handle highly non-smooth objectives or controller architectures where gradient computation is non-trivial, such as meta–reinforcement learning. However, a major weakness of ES-based algorithms is their difficulty in scaling to problems that require high-dimensional sensory inputs to encode the environment dynamics, such as training robots with complex vision inputs.
In this work, we propose “PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations”, a learning algorithm that combines representation learning and ES to effectively solve high dimensional problems in a scalable way. The core idea is to leverage predictive information, a representation learning objective, to obtain a compact representation of the high-dimensional environment dynamics, and then apply Augmented Random Search (ARS), a popular ES algorithm, to transform the learned compact representation into robot actions. We tested PI-ARS on the challenging problem of visual-locomotion for legged robots. PI-ARS enables fast training of performant vision-based locomotion controllers that can traverse a variety of difficult environments. Furthermore, the controllers trained in simulated environments successfully transfer to a real quadruped robot.
 |
| PI-ARS trains reliable visual-locomotion policies that are transferable to the real world. |
Predictive Information
A good representation for policy learning should be both compressive, so that ES can focus on solving a much lower dimensional problem than learning from raw observations would entail, and task-critical, so the learned controller has all the necessary information needed to learn the optimal behavior. For robotic control problems with high-dimensional input space, it is critical for the policy to understand the environment, including the dynamic information of both the robot itself and its surrounding objects.
As such, we propose an observation encoder that preserves information from the raw input observations that allows the policy to predict the future states of the environment, thus the name predictive information (PI). More specifically, we optimize the encoder such that the encoded version of what the robot has seen and planned in the past can accurately predict what the robot might see and be rewarded in the future. One mathematical tool to describe such a property is that of mutual information, which measures the amount of information we obtain about one random variable X by observing another random variable Y. In our case, X and Y would be what the robot saw and planned in the past, and what the robot sees and is rewarded in the future. Directly optimizing the mutual information objective is a challenging problem because we usually only have access to samples of the random variables, but not their underlying distributions. In this work we follow a previous approach that uses InfoNCE, a contrastive variational bound on mutual information to optimize the objective.
 |
| Left: We use representation learning to encode PI of the environment. Right: We train the representation by replaying trajectories from the replay buffer and maximize the predictability between the observation and motion plan in the past and the observation and reward in the future of the trajectory. |
Predictive Information with Augmented Random Search
Next, we combine PI with Augmented Random Search (ARS), an algorithm that has shown excellent optimization performance for challenging decision-making tasks. At each iteration of ARS, it samples a population of perturbed controller parameters, evaluates their performance in the testing environment, and then computes a gradient that moves the controller towards the ones that performed better.
We use the learned compact representation from PI to connect PI and ARS, which we call PI-ARS. More specifically, ARS optimizes a controller that takes as input the learned compact representation PI and predicts appropriate robot commands to achieve the task. By optimizing a controller with smaller input space, it allows ARS to find the optimal solution more efficiently. Meanwhile, we use the data collected during ARS optimization to further improve the learned representation, which is then fed into the ARS controller in the next iteration.
 |
| An overview of the PI-ARS data flow. Our algorithm interleaves between two steps: 1) optimizing the PI objective that updates the policy, which is the weights for the neural network that extracts the learned representation; and 2) sampling new trajectories and updating the controller parameters using ARS. |
Visual-Locomotion for Legged Robots
We evaluate PI-ARS on the problem of visual-locomotion for legged robots. We chose this problem for two reasons: visual-locomotion is a key bottleneck for legged robots to be applied in real-world applications, and the high-dimensional vision-input to the policy and the complex dynamics in legged robots make it an ideal test-case to demonstrate the effectiveness of the PI-ARS algorithm. A demonstration of our task setup in simulation can be seen below. Policies are first trained in simulated environments, and then transferred to hardware.
 |
| An illustration of the visual-locomotion task setup. The robot is equipped with two cameras to observe the environment (illustrated by the transparent pyramids). The observations and robot state are sent to the policy to generate a high-level motion plan, such as feet landing location and desired moving speed. The high-level motion plan is then achieved by a low-level Motion Predictive Control (MPC) controller. |
Experiment Results
We first evaluate the PI-ARS algorithm on four challenging simulated tasks:
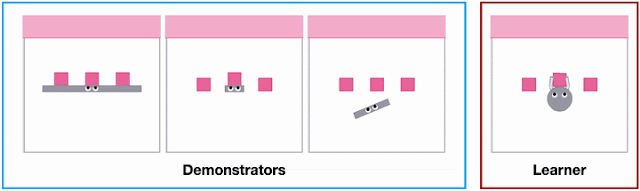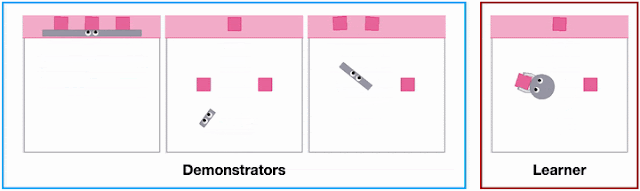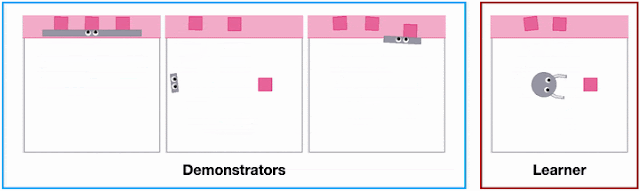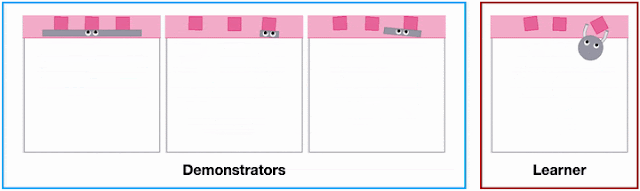
- Uneven stepping stones: The robot needs to walk over uneven terrain while avoiding gaps.
- Quincuncial piles: The robot needs to avoid gaps both in front and sideways.
- Moving platforms: The robot needs to walk over stepping stones that are randomly moving horizontally or vertically. This task illustrates the flexibility of learning a vision-based policy in comparison to explicitly reconstructing the environment.
- Indoor navigation: The robot needs to navigate to a random location while avoiding obstacles in an indoor environment.
As shown below, PI-ARS is able to significantly outperform ARS in all four tasks in terms of the total task reward it can obtain (by 30-50%).
 |
| Left: Visualization of PI-ARS policy performance in simulation. Right: Total task reward (i.e., episode return) for PI-ARS (green line) and ARS (red line). The PI-ARS algorithm significantly outperforms ARS on four challenging visual-locomotion tasks. |
We further deploy the trained policies to a real Laikago robot on two tasks: random stepping stone and indoor navigation. We demonstrate that our trained policies can successfully handle real-world tasks. Notably, the success rate of the random stepping stone task improved from 40% in the prior work to 100%.
 |
| PI-ARS trained policy enables a real Laikago robot to navigate around obstacles. |
Conclusion
In this work, we present a new learning algorithm, PI-ARS, that combines gradient-based representation learning with gradient-free evolutionary strategy algorithms to leverage the advantages of both. PI-ARS enjoys the effectiveness, simplicity, and parallelizability of gradient-free algorithms, while relieving a key bottleneck of ES algorithms on handling high-dimensional problems by optimizing a low-dimensional representation. We apply PI-ARS to a set of challenging visual-locomotion tasks, among which PI-ARS significantly outperforms the state of the art. Furthermore, we validate the policy learned by PI-ARS on a real quadruped robot. It enables the robot to walk over randomly-placed stepping stones and navigate in an indoor space with obstacles. Our method opens the possibility of incorporating modern large neural network models and large-scale data into the field of evolutionary strategy for robotics control.
Acknowledgements
We would like to thank our paper co-authors: Ofir Nachum, Tingnan Zhang, Sergio Guadarrama, and Jie Tan. We would also like to thank Ian Fischer and John Canny for valuable feedback.