If you are participating in CVPR this year, please visit our virtual booth to learn about what Google is actively pursuing for the next generation of intelligent systems that utilize the latest machine learning techniques applied to various areas of machine perception.
You can also learn more about our research being presented at CVPR 2020 in the list below (Google affiliations are bolded).
Organizing Committee General Chairs: Terry Boult, Gerard Medioni, Ramin Zabih Program Chairs: Ce Liu, Greg Mori, Kate Saenko, Silvio Savarese Workshop Chairs: Tal Hassner, Tali Dekel Website Chairs: Tianfan Xue, Tian Lan Technical Chair: Daniel Vlasic Area Chairs include: Alexander Toshev, Alexey Dosovitskiy, Boqing Gong, Caroline Pantofaru, Chen Sun, Deqing Sun, Dilip Krishnan, Feng Yang, Liang-Chieh Chen, Michael Rubinstein, Rodrigo Benenson, Timnit Gebru, Thomas Funkhouser, Varun Jampani, Vittorio Ferrari, William Freeman
Scalability in Perception for Autonomous Driving: Waymo Open Dataset Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurélien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Sheng Zhao, Shuyang Chen, Yu Zhang, Jon Shlens, Zhifeng Chen,Dragomir Anguelov
Deep Implicit Volume Compression Saurabh Singh, Danhang Tang, Cem Keskin, Philip Chou, Christian Haene, Mingsong Dou, Sean Fanello, Jonathan Taylor, Andrea Tagliasacchi, Philip Davidson, Yinda Zhang, Onur Guleryuz, Shahram Izadi, Sofien Bouaziz
This week marks the beginning of the 8th International Conference on Learning Representations (ICLR 2020), a fully virtual conference focused on how one can learn meaningful and useful representations of data for machine learning. ICLR offers conference and workshop tracks, both of which include invited talks along with oral and poster presentations of some of the latest research on deep learning, metric learning, kernel learning, compositional models, non-linear structured prediction and issues regarding non-convex optimization.
As a Diamond Sponsor of ICLR 2020, Google will have a strong virtual presence with over 80 publications accepted, in addition to participating on organizing committees and in workshops. If you have registered for ICLR 20202, we hope you'll watch our talks and learn about the projects and opportunities at Google that go into solving interesting problems for billions of people. You can also learn more about our research being presented at ICLR 2020 in the list below (Googlers highlighted in blue).
Officers and Board Members Includes: Hugo LaRochelle, Samy Bengio, Tara Sainath
Organizing Committee Includes: Kevin Swersky, Timnit Gebru
Area Chairs Includes:Balaji Lakshminarayanan, Been Kim, Chelsea Finn, Dale Schuurmans, George Tucker, Honglak Lee, Hossein Mobahi, Jasper Snoek, Justin Gilmer, Katherine Heller, Manaal Faruqui, Michael Ryoo, Nicolas Le Roux, Sanmi Koyejo, Sergey Levine, Tara Sainath, Yann Dauphin, Anders Søgaard, David Duvenaud, Jamie Morgenstern, Qiang Liu
Model Based Reinforcement Learning for Atari(see the blog post) Łukasz Kaiser, Mohammad Babaeizadeh, Piotr Miłos, Błazej Osinski, Roy H. Campbell, Konrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, Afroz Mohiuddin, Ryan Sepassi, George Tucker, Henryk Michalewski
Tackling Climate Change with Machine Learning Organizing Committee: Moustapha Cisse Co-Organizer: Natasha Jaques Program Committee: John C. Platt, Kevin McCloskey, Natasha Jaques Advisor and Panel: John C. Platt
Posted by Jeff Dean, Senior Fellow and SVP of Google Research and Health, on behalf of the entire Google Research community The goal of Google Research is to work on long-term, ambitious problems, with an emphasis on solving ones that will dramatically help people throughout their daily lives. In pursuit of that goal in 2019, we made advances in a broad set of fundamental research areas, applied our research to new and emerging areas such as healthcare and robotics, open sourced a wide variety of code and continued collaborations with Google product teams to build tools and services that are dramatically more helpful for our users.
As we start 2020, it’s useful to take a step back and assess the research work we’ve done over the past year, and also to look forward to what sorts of problems we want to tackle in the upcoming years. In that spirit, this blog post is a survey of some of the research-focused work done by Google researchers and engineers during 2019 (in the spirit of similar reviews for 2018, and more narrowly focused reviews of some work in 2017 and 2016). For a more comprehensive look, please see our research publications in 2019.
Ethical Use of AI In 2018, we published a set of AI Principles that provide a framework by which we evaluate our own research and applications of technologies such as machine learning in our products. In June 2019, we published a one-year update about how these principles are being put into practice in many different aspects of our research and product development life cycles. Since many of the areas touched on by the principles are active areas of research in the broader AI and machine learning research community (such as bias, safety, fairness, accountability, transparency and privacy in machine learning systems), our goals are to apply the best currently-known techniques in these areas to our work, and also to do research to continue to advance the state of the art in these important areas.
Released a beta version of Fairness Indicators, to help ML practitioners identify unjust or unintended impacts of machine learning models.
Clicking on a slice in Fairness Indicators will load all the data points in that slice inside the What-If Tool widget. In this case, all data points with the “female” label are shown.
Published a KDD'19 paper on how pairwise comparisons and regularization is incorporated into a large-scale production recommender system to improve ML Fairness.
Published an AIES'19 paper about a case study on the application of fairness in machine learning research to a production classification system, and described our fairness metric, conditional equality, that takes into account distributional differences in implementing equality of opportunity.
Published an AIES'19 paper about counterfactual fairness in text classification problems that asks the question: "How would the prediction change if the sensitive attribute referenced in the example were different?" and used this approach to improve our production systems that assess the toxicity of online content.
A sample of videos from Google’s contribution to the FaceForensics benchmark. To generate these, pairs of actors were selected randomly, and deep neural networks swapped the face of one actor onto the head of another.
In 2019 we updated Google Earth Timelapse, enabling people to effectively and intuitively visualize how the planet has changed over the past 35 years. Further, we’ve been collaborating with academic researchers on new privacy-preserving ways to aggregate data on human mobility, to give urban planners better information about how to design efficient environments with lower levels of carbon emissions. We’ve also applied machine learning to support childhood learning. According to the United Nations, 617 million children do not have basic literacy, a critical determinant of their quality of life. To help more children learn to read, our Bolo app uses speech-recognition technology that tutors students in real-time. And to increase access, the app works completely offline on low-cost phones. In India, Bolo has already helped 800,000 children read stories and speak half a billion words. Early results are encouraging; a three-month pilot among 200 villages in India showed an improvement in reading proficiency among 64% of pilot participants.
For older students, the Socratic app can help high schoolers with complex problems in math, physics and over 1,000 higher education topics. Based on a photo or verbal question, the app automatically identifies the question’s underlying concepts and links to the most helpful online resources. Like the Socratic method, the app doesn’t directly answer questions, but instead leads students to discover the answer themselves. We’re excited about the broad possibilities of improving educational outcomes around the world through things like Bolo and Socratic.
To expand the reach of our AI for Social Good efforts, in May we announced the grantees of our AI Impact Challenge with $25 million in grants from Google.org. The response was huge: we received over 2,600 thoughtful proposals from 119 countries. Twenty impressive organizations stood out for their potential to solve big social and environmental problems and were our initial set of grantees. A few examples of the work of these organizations:
Over a billion people live in smallholder farm households. A single pest attack can devastate their crop yields and livelihoods. Wadhwani AI uses image classification models that can identify pests and provide timely advice on what pesticides to spray and when—ultimately improving crop yield.
And deep in tropical rainforests, where illegal deforestation is a major driver of climate change, Rainforest Connection uses deep learning for bioacoustic monitoring and old cell phones to track rainforest health and detect threats.
Our 20 AI Impact Challenge winners. You can learn more about the work of all the grantees here.
Applications of AI to Other Fields The application of computer science and machine learning to other scientific fields is an area that we are especially excited about and have published a number of papers in, often in multi-organization collaborations. Some highlights from this year include:
In An Interactive, Automated 3D Reconstruction of a Fly Brain, we reported on a collaborative effort that achieved a milestone of mapping the structure of an entire fly brain, using machine learning models that were able to painstakingly trace each individual neuron.
In Learning Better Simulation Methods for Partial Differential Equations (PDEs), we showed how machine learning can be used to accelerate PDE computations, which are at the heart of many fundamental computational problems in climate science, fluid dynamics, electromagnetism, heat conduction and general relativity.
Simulations of Burgers’ equation, a model for shock waves in fluids, solved with either a standard finite volume method (left) or our neural network based method (right). The orange squares represent simulations with each method on low resolution grids. These points are fed back into the model at each time step, which then predicts how they should change. Blue lines show the exact simulations used for training. The neural network solution is much better, even on a 4x coarser grid, as indicated by the orange squares smoothly tracing the blue line.
2D snapshot of our embedding space with some example odors highlighted. Left: Each odor is clustered in its own space. Right: The hierarchical nature of the odor descriptor. Shaded and contoured areas are computed with a kernel-density estimate of the embeddings.
Machine learning can also help us in our artistic and creative endeavors. Artists have found ways to collaborate with AI and AR and create interesting new forms, from dancing with a machine to reimagine choreography, to creating new melodies with machine learning tools. ML can be used by novices, too. To honor the birthday of J.S. Bach, we featured a ML-powered Doodle: just create your melody, and the ML tool can create accompanying harmonizations in Bach’s style.
Assistive Technology On a more personal scale, ML can help us in our daily lives. It’s easy to take for granted our ability to see a beautiful image, to hear a favorite song, or to speak with a loved one. Yet over one billion people aren’t able to access the world in these ways. ML technology can help by turning these signals—vision, hearing, speech—into other signals that can be well-managed by people with accessibility needs, enabling better access to the world around them. A few examples of our assistive technology:
Lookout helps people who are blind or have low vision identify information about their surroundings. It draws upon similar underlying technology as Google Lens, which lets you search and take action on the objects around you, simply by pointing your phone.
Live Transcribe has the potential to give people who are deaf or hard of hearing greater independence in their everyday interactions. You can get real-time transcriptions of conversations that the user is engaged in, even if the speech is in another language.
Project Euphonia performs personalized speech-to-text transcription. For people with ALS and other conditions that produce slurred or non-standard speech, this research improves automatic speech recognition (ASR) over other state-of-the-art ASR models.
Like Project Euphonia, Parrotron uses end-to-end neural networks to help improve communication, but the research focuses on automatic speech-to-speech conversion rather than transcription, presenting a speech interface that may be easier for some to access.
Millions of images online don’t have any text description. Get Image Descriptions from Google helps blind or low vision users understand unlabelled images. When a screen reader encounters an image or graphic without a description, Chrome can now create one automatically.
We developed tools that can read visual text in audio form in Lens for Google Go, greatly helping users who are not fully literate navigate the word-rich world around them.
Making Your Phone More Intelligent Much of our work serves to enable intelligent, personal devices by giving mobile phones new capabilities through the use of on-device machine learning. By making powerful models that can run on-device, we can ensure that these phone features are highly responsive and always available even in airplane mode or otherwise off the network. We’ve made progress in getting highly accurate speech recognition models, vision models and handwriting recognition models all running on-device, paving the way for powerful new features. Some of this year’s highlights include:
The creation of a powerful new transcribing Recorder app, which can help index audio information and make it easily retrievable.
Improvements to Google Translate’s camera translation, so that you can point at text in an unfamiliar language and get it instantly translated in context.
Federated learning (check out the online comic description!) is a powerful machine learning approach invented by Google researchers in 2015, whereby many clients (such as mobile devices or whole organizations) collaboratively train a model, while keeping the training data decentralized. This enables approaches that have superior privacy properties in large-scale learning systems. We are using federated learning in more and more of our products and features, while also working to advance the state of the art in many research problems in this space. In 2019, Google researchers collaborated with authors from 24 (!) academic institutions to produce a survey article on Federated Learning, highlighting advances over the past few years as well describing a number of open research problems in the field.
Health In late 2018, we combined the Google Research health team, Deepmind Health and a team from Google’s Hardware division focused on health-related applications to form Google Health. In 2019 we continued the research we’ve been pursuing in this space, publishing research papers and building tools in collaboration with a variety of healthcare partners. Here are a few of the highlights from 2019:
We showed that a deep learning model for mammography can assist physicians in spotting breast cancer, a condition that affects 1 in 8 women in the US during their lifetimes, with greater accuracy than experts, reducing both false positives and false negatives. The model trained on de-identified data from a UK hospital had similar gains in accuracy when used to evaluate patients in a completely different healthcare system in the U.S.
Example of a difficult-to-detect cancer case correctly identified by machine learning.
Working alongside experts from the US Department of Veterans Affairs (VA), DeepMind Health colleagues who are now part of Google Health showed that a machine learning model can predict the onset of acute kidney injury (AKI), one of the leading causes of avoidable patient harm, up to two days before it happens. In the future, this could give doctors a 48-hour head start in treating this serious condition.
We showed a promising step forward for predicting lung cancer, where a deep learning model for examining the results of a single CT scan study performed on par or better than trained radiologists at early detection of lung cancer. Early detection of lung cancer dramatically improves survival rates.
We published a research paper on an augmented reality microscope for cancer diagnosis, whereby a pathologist can get real-time feedback about what parts of a slide are most interesting while examining tissue through a microscope. You can also read more about it in our 2018 blog post here.
Quantum Computing In 2019, our quantum computing team demonstrated for the first time a computational task that can be executed exponentially faster on a quantum processor than on the world’s fastest classical computer — just 200 seconds compared to 10,000 years.
Left: Artist's rendition of the Sycamore processor mounted in the cryostat. (Full Res Version; Forest Stearns, Google AI Quantum Artist in Residence) Right: Photograph of the Sycamore processor. (Full Res Version; Erik Lucero, Research Scientist and Lead Production Quantum Hardware)
Using quantum computers may make important problems in domains like materials science, quantum chemistry (early example) and large-scale optimization tractable, but in order to make this a reality, we’ll have to continue to push the field forward. We are now focusing on implementing quantum error correction so that we will be able to run computations for longer. We are also working on making quantum algorithms easier to express, the hardware easier to control and we have found ways to use classical machine learning techniques like deep reinforcement learning to build more reliable quantum processors. The achievements this year are encouraging and are early steps along the way to making practical quantum computing a reality for a wider variety of problems.
We published a paper at VLDB’19 titled "Cache-aware load balancing of data center applications," although an alternative title could be "Increase the serving capacity of your data center by 40% with this one cool trick!". The paper describes how we used balanced partitioning of graphs to specialize the caches in our web search backend serving system, thereby increasing the query throughput of our flash drives by 48%, and helping to enable a 40% increase in the throughput of the entire search backend.
Heatmap of flash IO requests (resulting from cache misses) across web search serving leaves. The three humps represent random leaf selection, load balancing, and cache-aware load balancing (left to right). Lines indicate the 50th, 90th, 95th and 99.9th percentiles. From VLDB’19 paper, "Cache-aware load balancing of data center applications."
In an ICLR’2019 paper titled "A new dog learns old tricks: RL finds classic optimization algorithms," we discovered a new connection between algorithms and machine learning, showing how Reinforcement Learning can effectively find optimal (worst-case, uniform) algorithms for several classic online optimization combinatorial problems such as online matching and allocation.
Our work in scalable algorithms spans both parallel, online and distributed algorithms for big data sets. In a recent FOCS’19 paper, we provided a near-optimal massively parallel computation algorithm for connected components. Another set of our papers improved parallel algorithms for matching (in theory and practice) and for density clustering. And a third line of work concerned adaptively optimizing submodular functions in the black-box model, which has several applications in feature selection and vocabulary compression. In a SODA’19 paper, we presented a submodular maximization algorithm that is nearly optimal in three aspects: approximation factor, round complexity, and query complexity. Also, in another FOCS 2019 paper, we provide the first online multiplicative approximation algorithm for PCA and Column Subset selection.
In other work, we introduce the semi-online model of computation that postulates that the unknown future has a predictable part and an adversarial part. For classical combinatorial problems such as bipartite matching (ITCS’19) and caching (SODA’20), we obtained semi-online algorithms to provide guarantees that smoothly interpolate between the best possible online and offline algorithms.
Our recent research in the area of market algorithms includes new understanding of the interaction between learning and markets, and innovations in experimental design. For example, this NeurIPS’19 oral paper reveals the surprising competitive advantage that a strategic agent has when competing with a learning agent in a general repeated 2-player game. Recent focus on advertising automation has produced increased interest in automated bidding and understanding response behavior of advertisers. In a pair of WINE2019 papers, we study optimal strategy to maximize conversions on behalf of advertisers and further learn advertiser response behavior for any changes in the auction. Finally, we studied experimental design in the presence of interference where the treatment of one group may affect the outcomes of others. In a KDD'19 paper and a NeurIPS'19 paper, we show how to define units or clusters of units to limit interference while maintaining experimental power.
The clustering algorithm from the KDD’19 paper “Randomized Experimental Design via Geographic Clustering“ applied to user queries from the United States. The algorithm automatically identifies metropolitan areas, correctly predicting, for example, that the Bay Area includes San Francisco, Berkeley, and Palo Alto, but not Sacramento.
Machine Learning Algorithms In 2019, we conducted research in many different areas of machine learning algorithms and approaches. One major focus was in understanding the properties of training dynamics in neural networks. In the blog post Measuring the Limits of Data Parallel Training for Neural Networks highlighting this paper, Google researchers presented a careful set of experimental results showing when scaling the amount of data parallelism (by making larger batches) is effective for allowing the model to converge faster (using data parallelism).
For all workloads we tested, we observed a universal relationship between batch size and training speed with three distinct regimes: perfect scaling with small batch sizes (following the dashed line), eventually seeing diminishing returns as batch sizes grow (diverging from the dashed line), and maximal data parallelism at the largest batch sizes (where the trend plateaus). The transition points between the regimes vary dramatically between different workloads.
Model parallelism, in contrast to data parallelism, where a model is spread out across multiple computational devices, can be an effective way of scaling models. GPipe is a library that enables model parallelism to be more effective, in an approach similar to that used by pipelined CPU processors: when one part of the whole model is working on some of the data, other parts can be working on their part of the computation on different data. The results of this pipeline approach can be combined together to simulate a larger effective batch size.
Machine learning models are effective when they’re able to take raw input data and learn “disentangled” higher-level representations that separate different kinds of examples by properties that we want the model to be able to distinguish (cat vs. truck vs. wildebeest, cancerous tissue vs. normal tissue, etc.). Much of the focus on advancing machine learning algorithms is to encourage the learning of better representations that generalize better to new examples, problems or domains. This year, we looked at this problem in a number of different contexts:
In Predicting the Generalization Gap in Deep Neural Networks, we showed that it is possible to predict the generalization gap (the gap between a model’s performance on data from the training distribution versus data drawn from a different distribution) using statistics of the margin distribution, helping us better understand which models generalize most effectively. We also did some research on Improving Out-of-Distribution Detection in Machine Learning Models, to better understand when a model is starting to encounter kinds of data it has never seen before. We also looked at Off-Policy Classification in the context of reinforcement learning, to better understand which models are likely to generalize the best.
In Learning to Generalize from Sparse and Underspecified Rewards, we also examined ways of specifying reward functions for reinforcement learning that enable learning systems to more directly learn from true objectives and be less distracted with longer, less-desirable sequences of actions that happen to achieve desired goals by accident.
In this instruction-following task, the action trajectories a1, a2 and a3 reach the goal, but the sequences a2 and a3 do not follow the instructions. This illustrates the issue of underspecified rewards.
AutoML We continued our work on AutoML this year, an approach whereby algorithms that learn how to learn can automate many aspects of machine learning and often can achieve substantially better results than the best human machine learning experts for certain kinds of machine learning meta-decisions. In particular:
In EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling, we showed how to use neural architecture search techniques to achieve substantially better results on computer vision problems, including a new state-of-the-art result of 84.4% top-1 accuracy on ImageNet while having 8X fewer parameters than the previous best model.
Model Size vs. Accuracy Comparison. EfficientNet-B0 is the baseline network developed by AutoML MNAS, while Efficient-B1 to B7 are obtained by scaling up the baseline network. In particular, our EfficientNet-B7 achieves new state-of-the-art 84.4% top-1 / 97.1% top-5 accuracy, while being 8.4x smaller than the best existing CNN.
In Video Architecture Search, we describe how we extended our AutoML work to the domain of video models, finding architectures that achieve state-of-the-art results, and also lightweight architectures that match the performance of hand-crafted models while using 50x less computation.
TinyVideoNet (TVN) architectures evolved to maximize the recognition performance while keeping its computation time within the desired limit. For instance, TVN-1 (top) runs at 37 ms on a CPU and 10ms on a GPU. TVN-2 (bottom) runs at 65ms on a CPU and 13ms on a GPU.
We developed AutoML techniques for tabular data, unlocking an important domain where many companies and organizations have interesting data in relational databases, and often want to develop machine learning models on this data. We collaborated to release this technology as a new Google Cloud AutoML Tables product, and also discussed how well this system did in a new Kaggle competition in An End-to-End AutoML Solution for Tabular Data at KaggleDays (spoiler: AutoML Tables finished second out of 74 teams of expert data scientists).
InExploring Weight Agnostic Neural Networks, we showed how it is possible to find interesting neural network architectures without any training steps to update the weights of the evaluated models. This can make architecture search much more computationally efficient.
A weight-agnostic neural network performing a Cartpole Swing-up task at various different weight parameters, and also using fine-tuned weight parameters.
Applying AutoML to Transformer Architectures explored finding architectures for natural language processing tasks that significantly outperform vanilla Transformer models at substantially reduced computational costs.
Comparison between the Evolved Transformer and the original Transformer on WMT’14 En-De at varying sizes. The biggest gains in performance occur at smaller sizes, while ET also shows strength at larger sizes, outperforming the largest Transformer with 37.6% less parameters (models to compare are circled in green). See Table 3 in our paper for the exact numbers.
In SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition, we showed that the approach of automatically learning data augmentation methods can be extended to speech recognition models, with the learned augmentation approaches achieving significantly higher accuracy with less data than existing human ML-expert driven data augmentation approaches.
We launched our first speech application for keyword spotting and spoken language identification using AutoML. In our experiments we found better models (both more efficient and better performance) than the human designed models that have been in this setting for some time.
Natural Language Understanding The past few years have seen remarkable advances in models for natural language understanding, translation, natural dialog, speech recognition and related tasks. This year, one theme in our work was advancing the state of the art by combining modalities or tasks, to train more powerful and capable models. A few examples:
Left: Language pairs with larger amounts of training data generally have higher translation quality. Right: Multilingual training, where we train a single model for all language pairs rather than separate models for each language pair, results in substantial improvements in BLEU score (a measure of translation quality) for language pairs without much data.
Left: A traditional monolingual speech recognizer comprised of Acoustic, Pronunciation and Language Models for each language. Middle: A traditional multilingual speech recognizer where the Acoustic and Pronunciation model is multilingual, while the Language model is language-specific. Right: An E2E multilingual speech recognizer where the Acoustic, Pronunciation and Language Model is combined into a single multilingual model.
In Translatotron: An End-to-End Speech-to-Speech Translation Model, we showed that it is possible to train a joint model to accomplish the (normally separate) tasks of speech recognition, translation and text-to-speech generation with nice benefits, like preserving the sound of the speaker’s voice in the generated translated audio, as well as a simpler overall learning system.
In Robust Neural Machine Translation, we showed how to use an adversarial training procedure to significantly improve the quality and robustness of language translations.
Left: The Transformer model is applied to an input sentence (lower left) and, in conjunction with the target output sentence (above right) and target input sentence (middle right; beginning with the placeholder “<sos>”), the translation loss is calculated. The AdvGen function then takes the source sentence, word selection distribution, word candidates and the translation loss as inputs to construct an adversarial source example. Right: In the defense stage, the adversarial source example serves as input to the Transformer model and the translation loss is calculated. AdvGen then uses the same method as above to generate an adversarial target example from the target input.
As our language understanding capabilities have improved, based on fundamental research advances like seq2seq, Transformer, BERT, Transformer-XL and ALBERT models, we have seen increased use of these sorts of models in many of our core products and features like Google Translate, Gmail’s Smart Compose, and Google Search. This year, the launch of BERT in our core search and ranking algorithms led to the biggest improvement in search quality in the last five years (and one of the biggest ever), through better understanding of the subtle meanings of query and document words and phrases.
Machine Perception Models for better understanding of still images have made remarkable progress in the last decade. Among the next major frontiers are models and approaches for understanding the dynamic world in fine-grained detail. This includes deeper and more nuanced understanding of images and video, as well as live and situated perception: understanding the audiovisual world at interactive rates and with a shared spatial grounding with the user. This year, we explored many aspects of advances in this area, including:
Finer-grained visual understanding in Lens, enabling even more powerful visual search.
Helpful smart camera features such as Quick Gestures, Face Match and smart video call framing on the Nest Hub Max.
Technology for live and spatially-aware perception for helpfully augmenting the world around us through Lens.
Right: Input videos of people performing a squat exercise. The video on the top left is the reference. The other videos show nearest neighbor frames (in the TCC embedding space) from other videos of people doing squats. Left: The corresponding frame embeddings move as the action is performed.
Qualitative results from VideoBERT, pretrained on cooking videos. Top: Given some recipe text, we generate a sequence of visual tokens. Bottom: Given a visual token, we show the top three future tokens forecast by VideoBERT at different time scales. In this case, the model predicts that a bowl of flour and cocoa powder may be baked in an oven and may become a brownie or cupcake. We visualize the visual tokens using the images from the training set closest to the tokens in feature space.
We’re quite excited about the prospects of continued improvements in the understanding of the sensory world around us.
Robotics The application of machine learning to robotic control is a significant research area for us. We believe this is a vital tool for enabling robots to operate effectively in complex, real-world environments like everyday homes and businesses. Some of the work we did this year includes:
In PlaNet: A Deep Planning Network for Reinforcement Learning, we showed how to effectively learn a world model purely from the pixels of images, and how to leverage this model of how the world behaves in order to accomplish tasks with many fewer learning episodes.
In Unifying Physics and Deep Learning with TossingBot, we showed how robots can learn “intuitive” physics from experimentation in an environment, rather than being pre-programmed with physics models about the environment in which they are operating.
In Soft Actor-Critic: Deep Reinforcement Learning for Robotics, we showed that training a reinforcement learning algorithm to both maximize the expected reward (which is the standard RL objective) and to maximize the policy's entropy (so that learning favors policies that are more random), can help robots learn faster and be more robust to changes in their environment.
We introduced ROBEL: Robotics Benchmarks for Learning with Low-Cost Robots, an open-source platform of cost-effective robots and curated benchmarks designed to facilitate research and development on physical robotics hardware in the real world.
Helping Advance the Broader Developer and Researcher Community Open source is about more than code: it's about the community of contributors. It’s been an exciting year to be part of the open source community. We launched TensorFlow 2.0—the biggest TensorFlow release to date—which makes building ML systems and applications easier than ever. We added support for fast mobile GPU inference to TensorFlow Lite. We also launched Teachable Machine 2.0, a fast, easy web-based tool which can train a machine learning model with the click of a button, no coding required. We announced MLIR, open source machine learning compiler infrastructure that addresses the complexity of growing software and hardware fragmentation and makes it easier to build AI applications.
We open-sourced MediaPipe, a framework for building perceptual and multimodal applied ML pipelines, and XNNPACK, a library of efficient floating-point neural network inference operators. As of the end of 2019, we had enabled more than 1,500 researchers around the world to access Cloud TPUs for free via the TensorFlow Research Cloud. Our Intro To TensorFlow at Coursera crossed 100,000 students. And we engaged with thousands of users while taking TensorFlow on the road to 11 different countries, hosted our first ever TensorFlow World and more.
Open Datasets Open datasets with clear and measurable goals are often very helpful in driving forward the field of machine learning. To help the research community find interesting datasets, we continue to index a wide variety of open datasets sourced from many different organizations with Google Dataset Search. We also think it's important to create new datasets for the community to explore and to develop new techniques, and to ensure we share open data responsibly. This year, we additionally released a number of open datasets across many different areas:
Open Images V5: An update to the popular Open Images dataset that includes segmentation masks for 2.8 million objects in 350 categories (so that it now has ~9M images annotated with image-level labels, object bounding boxes, object segmentation masks, and visual relationships).
Natural questions: the first dataset to use naturally occurring queries and find answers by reading an entire page, rather than extracting answers from a short paragraph.
Google Research Football: a novel reinforcement learning environment where agents aim to master the world’s most popular sport—football (or, if you’re American, soccer). It’s important for reinforcement learning agents to have GOOOAAALLLSS!
Google-Landmarks-v2: over 5 million images (2x that of the first release) of more than 200 thousand different landmarks.
YouTube-8M Segments: A large-scale classification and temporal localization dataset that includes human-verified labels at the 5-second segment level of YouTube-8M videos.
PAWS and PAWS-X: To help with paraphrase identification, both datasets contain well-formed sentence pairs with high lexical overlap, in which around half of pairs are paraphrase and half are not.
Natural language dialog datasets: CCPE and Taskmaster-1 both use a Wizard-of-Oz platform that pairs two people who engage in spoken conversations, to mimic a human-level conversation with a digital assistant.
The Visual Task Adaptation Benchmark: VTAB follows similar guidelines to ImageNet and GLUE but is based on one principle—a better representation is one that yields better performance on unseen tasks, with limited in-domain data.
Schema-Guided Dialogue Dataset: the largest publicly available corpus of task-oriented dialogues, with over 18,000 dialogues spanning 17 domains.
Research Community Interaction Finally, we’ve been busy within the broader academic and research community. In 2019 Google researchers presented hundreds of papers, participated in numerous conferences and received many awards and other accolades. We had a strong presence at:
CVPR: ~250 Googlers presented 40+ papers, talks, posters, workshops and more.
ICML: ~200 Googlers presented 100+ papers, talks, posters, workshops and more.
ICLR: ~200 Googlers presented 60+ papers, talks, posters, workshops and more.
ACL: ~100 Googlers presented 40+ papers, workshops and tutorials.
Interspeech: Over 100 Googlers presented 30+ papers.
ICCV: ~200 Googlers presented 40+ papers, and several Googlers also won three prestigious ICCV awards.
NeurIPS: ~500 Googlers co-authored more than 120 accepted papers and engaged in various workshops and more.
We also brought together hundreds of Google researchers and faculty from across the globe to 15 separate research workshops hosted at Google locations. These workshops were on topics ranging from improving flood forecasting globally, to how to use machine learning to build systems that can better serve people with disabilities, to accelerating the development of algorithms, applications and tools for noisy-intermediate scale quantum (NISQ) processors.
New Places, New Faces We’ve made lots of headway in 2019, but there’s so much more we can do. To continue growing our impact around the world, we opened a Research office in Bangalore, and we’re expanding in other offices. If you’re excited about working on these sorts of problems, we’re hiring!
Looking Forward to 2020 and Beyond The past decade has seen remarkable advances in the fields of machine learning and computer science, where we now have given computers the ability to see, hear and understand language better than ever before (see a nice overview of important advances of the last decade). In our pockets, we now have sophisticated computing devices that can use these capabilities to better help us accomplish a multitude of tasks in our daily lives. We have substantially redesigned our computing platforms around these machine learning approaches by developing specialized hardware, giving us the ability to tackle ever larger problems. This has changed how we think about computing devices both in data centers (such as the inference-focused TPUv1 and the training-and-inference focused TPUv2 and TPUv3), as well as in low-power mobile environments (such as Edge TPUs). The deep learning revolution will continue to reshape how we think about computing and computers.
At the same time, there are a huge number of unanswered questions and unsolved problems. Some directions and questions that we are excited about tackling in 2020 and beyond are:
How can we build machine learning systems that can handle millions of tasks, and that can learn to successfully accomplish new tasks automatically? Currently, we’re mostly training separate machine models for each new task, starting from scratch, or at best, from a model trained on one or a few highly related tasks. As such, the models we train are really good at one or a few things, but not good at anything else. However, what we truly want are models that are good at leveraging their expertise at doing many things, so that they are able to learn to do a new thing with relatively little training data and computation. This is a true grand challenge which will require expertise and advances in many areas spanning solid-state circuit design, computer architecture, ML-focused compilers, distributed systems, machine learning algorithms and domain experts across many other fields in order to build systems that can generalize to solve new tasks independently across a full range of application areas.
How can we advance the state-of-the-art in important areas of artificial intelligence research like avoiding bias, increasing interpretability & understandability, improving privacy and ensuring safety? Advances in these areas are going to be critical as we use machine learning in more and more ways in society.
How can we apply computation and machine learning to make advances in important new areas of science? There are important advances to be had by collaborating with experts in other fields in areas like climate science, healthcare, bioinformatics and many other areas.
How can we ensure that the ideas and directions pursued by the machine learning and computer science research communities are put forth and explored by a diverse group of researchers? The work that the computer science and machine learning research communities are pursuing has broad implications for billions of people, and we want the set of researchers doing this work to represent the experiences, perspectives, concerns and creative enthusiasm of all the people of the world. How can we best support new researchers from diverse backgrounds entering the field?
Overall, 2019 was a very exciting year for research at Google and in the broader research community. We’re excited about tackling the research challenges ahead of us in 2020 and beyond, and we look forward to sharing our progress with you!
Posted by Jeff Dean, Senior Fellow and SVP of Google Research and Health, on behalf of the entire Google Research community The goal of Google Research is to work on long-term, ambitious problems, with an emphasis on solving ones that will dramatically help people throughout their daily lives. In pursuit of that goal in 2019, we made advances in a broad set of fundamental research areas, applied our research to new and emerging areas such as healthcare and robotics, open sourced a wide variety of code and continued collaborations with Google product teams to build tools and services that are dramatically more helpful for our users.
As we start 2020, it’s useful to take a step back and assess the research work we’ve done over the past year, and also to look forward to what sorts of problems we want to tackle in the upcoming years. In that spirit, this blog post is a survey of some of the research-focused work done by Google researchers and engineers during 2019 (in the spirit of similar reviews for 2018, and more narrowly focused reviews of some work in 2017 and 2016). For a more comprehensive look, please see our research publications in 2019.
Ethical Use of AI In 2018, we published a set of AI Principles that provide a framework by which we evaluate our own research and applications of technologies such as machine learning in our products. In June 2019, we published a one-year update about how these principles are being put into practice in many different aspects of our research and product development life cycles. Since many of the areas touched on by the principles are active areas of research in the broader AI and machine learning research community (such as bias, safety, fairness, accountability, transparency and privacy in machine learning systems), our goals are to apply the best currently-known techniques in these areas to our work, and also to do research to continue to advance the state of the art in these important areas.
Released a beta version of Fairness Indicators, to help ML practitioners identify unjust or unintended impacts of machine learning models.
Clicking on a slice in Fairness Indicators will load all the data points in that slice inside the What-If Tool widget. In this case, all data points with the “female” label are shown.
Published a KDD'19 paper on how pairwise comparisons and regularization is incorporated into a large-scale production recommender system to improve ML Fairness.
Published an AIES'19 paper about a case study on the application of fairness in machine learning research to a production classification system, and described our fairness metric, conditional equality, that takes into account distributional differences in implementing equality of opportunity.
Published an AIES'19 paper about counterfactual fairness in text classification problems that asks the question: "How would the prediction change if the sensitive attribute referenced in the example were different?" and used this approach to improve our production systems that assess the toxicity of online content.
A sample of videos from Google’s contribution to the FaceForensics benchmark. To generate these, pairs of actors were selected randomly, and deep neural networks swapped the face of one actor onto the head of another.
In 2019 we updated Google Earth Timelapse, enabling people to effectively and intuitively visualize how the planet has changed over the past 35 years. Further, we’ve been collaborating with academic researchers on new privacy-preserving ways to aggregate data on human mobility, to give urban planners better information about how to design efficient environments with lower levels of carbon emissions. We’ve also applied machine learning to support childhood learning. According to the United Nations, 617 million children do not have basic literacy, a critical determinant of their quality of life. To help more children learn to read, our Bolo app uses speech-recognition technology that tutors students in real-time. And to increase access, the app works completely offline on low-cost phones. In India, Bolo has already helped 800,000 children read stories and speak half a billion words. Early results are encouraging; a three-month pilot among 200 villages in India showed an improvement in reading proficiency among 64% of pilot participants.
For older students, the Socratic app can help high schoolers with complex problems in math, physics and over 1,000 higher education topics. Based on a photo or verbal question, the app automatically identifies the question’s underlying concepts and links to the most helpful online resources. Like the Socratic method, the app doesn’t directly answer questions, but instead leads students to discover the answer themselves. We’re excited about the broad possibilities of improving educational outcomes around the world through things like Bolo and Socratic.
To expand the reach of our AI for Social Good efforts, in May we announced the grantees of our AI Impact Challenge with $25 million in grants from Google.org. The response was huge: we received over 2,600 thoughtful proposals from 119 countries. Twenty impressive organizations stood out for their potential to solve big social and environmental problems and were our initial set of grantees. A few examples of the work of these organizations:
Over a billion people live in smallholder farm households. A single pest attack can devastate their crop yields and livelihoods. Wadhwani AI uses image classification models that can identify pests and provide timely advice on what pesticides to spray and when—ultimately improving crop yield.
And deep in tropical rainforests, where illegal deforestation is a major driver of climate change, Rainforest Connection uses deep learning for bioacoustic monitoring and old cell phones to track rainforest health and detect threats.
Our 20 AI Impact Challenge winners. You can learn more about the work of all the grantees here.
Applications of AI to Other Fields The application of computer science and machine learning to other scientific fields is an area that we are especially excited about and have published a number of papers in, often in multi-organization collaborations. Some highlights from this year include:
In An Interactive, Automated 3D Reconstruction of a Fly Brain, we reported on a collaborative effort that achieved a milestone of mapping the structure of an entire fly brain, using machine learning models that were able to painstakingly trace each individual neuron.
In Learning Better Simulation Methods for Partial Differential Equations (PDEs), we showed how machine learning can be used to accelerate PDE computations, which are at the heart of many fundamental computational problems in climate science, fluid dynamics, electromagnetism, heat conduction and general relativity.
Simulations of Burgers’ equation, a model for shock waves in fluids, solved with either a standard finite volume method (left) or our neural network based method (right). The orange squares represent simulations with each method on low resolution grids. These points are fed back into the model at each time step, which then predicts how they should change. Blue lines show the exact simulations used for training. The neural network solution is much better, even on a 4x coarser grid, as indicated by the orange squares smoothly tracing the blue line.
2D snapshot of our embedding space with some example odors highlighted. Left: Each odor is clustered in its own space. Right: The hierarchical nature of the odor descriptor. Shaded and contoured areas are computed with a kernel-density estimate of the embeddings.
Machine learning can also help us in our artistic and creative endeavors. Artists have found ways to collaborate with AI and AR and create interesting new forms, from dancing with a machine to reimagine choreography, to creating new melodies with machine learning tools. ML can be used by novices, too. To honor the birthday of J.S. Bach, we featured a ML-powered Doodle: just create your melody, and the ML tool can create accompanying harmonizations in Bach’s style.
Assistive Technology On a more personal scale, ML can help us in our daily lives. It’s easy to take for granted our ability to see a beautiful image, to hear a favorite song, or to speak with a loved one. Yet over one billion people aren’t able to access the world in these ways. ML technology can help by turning these signals—vision, hearing, speech—into other signals that can be well-managed by people with accessibility needs, enabling better access to the world around them. A few examples of our assistive technology:
Lookout helps people who are blind or have low vision identify information about their surroundings. It draws upon similar underlying technology as Google Lens, which lets you search and take action on the objects around you, simply by pointing your phone.
Live Transcribe has the potential to give people who are deaf or hard of hearing greater independence in their everyday interactions. You can get real-time transcriptions of conversations that the user is engaged in, even if the speech is in another language.
Project Euphonia performs personalized speech-to-text transcription. For people with ALS and other conditions that produce slurred or non-standard speech, this research improves automatic speech recognition (ASR) over other state-of-the-art ASR models.
Like Project Euphonia, Parrotron uses end-to-end neural networks to help improve communication, but the research focuses on automatic speech-to-speech conversion rather than transcription, presenting a speech interface that may be easier for some to access.
Millions of images online don’t have any text description. Get Image Descriptions from Google helps blind or low vision users understand unlabelled images. When a screen reader encounters an image or graphic without a description, Chrome can now create one automatically.
We developed tools that can read visual text in audio form in Lens for Google Go, greatly helping users who are not fully literate navigate the word-rich world around them.
Making Your Phone More Intelligent Much of our work serves to enable intelligent, personal devices by giving mobile phones new capabilities through the use of on-device machine learning. By making powerful models that can run on-device, we can ensure that these phone features are highly responsive and always available even in airplane mode or otherwise off the network. We’ve made progress in getting highly accurate speech recognition models, vision models and handwriting recognition models all running on-device, paving the way for powerful new features. Some of this year’s highlights include:
The creation of a powerful new transcribing Recorder app, which can help index audio information and make it easily retrievable.
Improvements to Google Translate’s camera translation, so that you can point at text in an unfamiliar language and get it instantly translated in context.
Federated learning (check out the online comic description!) is a powerful machine learning approach invented by Google researchers in 2015, whereby many clients (such as mobile devices or whole organizations) collaboratively train a model, while keeping the training data decentralized. This enables approaches that have superior privacy properties in large-scale learning systems. We are using federated learning in more and more of our products and features, while also working to advance the state of the art in many research problems in this space. In 2019, Google researchers collaborated with authors from 24 (!) academic institutions to produce a survey article on Federated Learning, highlighting advances over the past few years as well describing a number of open research problems in the field.
Health In late 2018, we combined the Google Research health team, Deepmind Health and a team from Google’s Hardware division focused on health-related applications to form Google Health. In 2019 we continued the research we’ve been pursuing in this space, publishing research papers and building tools in collaboration with a variety of healthcare partners. Here are a few of the highlights from 2019:
We showed that a deep learning model for mammography can assist physicians in spotting breast cancer, a condition that affects 1 in 8 women in the US during their lifetimes, with greater accuracy than experts, reducing both false positives and false negatives. The model trained on de-identified data from a UK hospital had similar gains in accuracy when used to evaluate patients in a completely different healthcare system in the U.S.
Example of a difficult-to-detect cancer case correctly identified by machine learning.
Working alongside experts from the US Department of Veterans Affairs (VA), DeepMind Health colleagues who are now part of Google Health showed that a machine learning model can predict the onset of acute kidney injury (AKI), one of the leading causes of avoidable patient harm, up to two days before it happens. In the future, this could give doctors a 48-hour head start in treating this serious condition.
We showed a promising step forward for predicting lung cancer, where a deep learning model for examining the results of a single CT scan study performed on par or better than trained radiologists at early detection of lung cancer. Early detection of lung cancer dramatically improves survival rates.
We published a research paper on an augmented reality microscope for cancer diagnosis, whereby a pathologist can get real-time feedback about what parts of a slide are most interesting while examining tissue through a microscope. You can also read more about it in our 2018 blog post here.
Quantum Computing In 2019, our quantum computing team demonstrated for the first time a computational task that can be executed exponentially faster on a quantum processor than on the world’s fastest classical computer — just 200 seconds compared to 10,000 years.
Left: Artist's rendition of the Sycamore processor mounted in the cryostat. (Full Res Version; Forest Stearns, Google AI Quantum Artist in Residence) Right: Photograph of the Sycamore processor. (Full Res Version; Erik Lucero, Research Scientist and Lead Production Quantum Hardware)
Using quantum computers may make important problems in domains like materials science, quantum chemistry (early example) and large-scale optimization tractable, but in order to make this a reality, we’ll have to continue to push the field forward. We are now focusing on implementing quantum error correction so that we will be able to run computations for longer. We are also working on making quantum algorithms easier to express, the hardware easier to control and we have found ways to use classical machine learning techniques like deep reinforcement learning to build more reliable quantum processors. The achievements this year are encouraging and are early steps along the way to making practical quantum computing a reality for a wider variety of problems.
We published a paper at VLDB’19 titled "Cache-aware load balancing of data center applications," although an alternative title could be "Increase the serving capacity of your data center by 40% with this one cool trick!". The paper describes how we used balanced partitioning of graphs to specialize the caches in our web search backend serving system, thereby increasing the query throughput of our flash drives by 48%, and helping to enable a 40% increase in the throughput of the entire search backend.
Heatmap of flash IO requests (resulting from cache misses) across web search serving leaves. The three humps represent random leaf selection, load balancing, and cache-aware load balancing (left to right). Lines indicate the 50th, 90th, 95th and 99.9th percentiles. From VLDB’19 paper, "Cache-aware load balancing of data center applications."
In an ICLR’2019 paper titled "A new dog learns old tricks: RL finds classic optimization algorithms," we discovered a new connection between algorithms and machine learning, showing how Reinforcement Learning can effectively find optimal (worst-case, uniform) algorithms for several classic online optimization combinatorial problems such as online matching and allocation.
Our work in scalable algorithms spans both parallel, online and distributed algorithms for big data sets. In a recent FOCS’19 paper, we provided a near-optimal massively parallel computation algorithm for connected components. Another set of our papers improved parallel algorithms for matching (in theory and practice) and for density clustering. And a third line of work concerned adaptively optimizing submodular functions in the black-box model, which has several applications in feature selection and vocabulary compression. In a SODA’19 paper, we presented a submodular maximization algorithm that is nearly optimal in three aspects: approximation factor, round complexity, and query complexity. Also, in another FOCS 2019 paper, we provide the first online multiplicative approximation algorithm for PCA and Column Subset selection.
In other work, we introduce the semi-online model of computation that postulates that the unknown future has a predictable part and an adversarial part. For classical combinatorial problems such as bipartite matching (ITCS’19) and caching (SODA’20), we obtained semi-online algorithms to provide guarantees that smoothly interpolate between the best possible online and offline algorithms.
Our recent research in the area of market algorithms includes new understanding of the interaction between learning and markets, and innovations in experimental design. For example, this NeurIPS’19 oral paper reveals the surprising competitive advantage that a strategic agent has when competing with a learning agent in a general repeated 2-player game. Recent focus on advertising automation has produced increased interest in automated bidding and understanding response behavior of advertisers. In a pair of WINE2019 papers, we study optimal strategy to maximize conversions on behalf of advertisers and further learn advertiser response behavior for any changes in the auction. Finally, we studied experimental design in the presence of interference where the treatment of one group may affect the outcomes of others. In a KDD'19 paper and a NeurIPS'19 paper, we show how to define units or clusters of units to limit interference while maintaining experimental power.
The clustering algorithm from the KDD’19 paper “Randomized Experimental Design via Geographic Clustering“ applied to user queries from the United States. The algorithm automatically identifies metropolitan areas, correctly predicting, for example, that the Bay Area includes San Francisco, Berkeley, and Palo Alto, but not Sacramento.
Machine Learning Algorithms In 2019, we conducted research in many different areas of machine learning algorithms and approaches. One major focus was in understanding the properties of training dynamics in neural networks. In the blog post Measuring the Limits of Data Parallel Training for Neural Networks highlighting this paper, Google researchers presented a careful set of experimental results showing when scaling the amount of data parallelism (by making larger batches) is effective for allowing the model to converge faster (using data parallelism).
For all workloads we tested, we observed a universal relationship between batch size and training speed with three distinct regimes: perfect scaling with small batch sizes (following the dashed line), eventually seeing diminishing returns as batch sizes grow (diverging from the dashed line), and maximal data parallelism at the largest batch sizes (where the trend plateaus). The transition points between the regimes vary dramatically between different workloads.
Model parallelism, in contrast to data parallelism, where a model is spread out across multiple computational devices, can be an effective way of scaling models. GPipe is a library that enables model parallelism to be more effective, in an approach similar to that used by pipelined CPU processors: when one part of the whole model is working on some of the data, other parts can be working on their part of the computation on different data. The results of this pipeline approach can be combined together to simulate a larger effective batch size.
Machine learning models are effective when they’re able to take raw input data and learn “disentangled” higher-level representations that separate different kinds of examples by properties that we want the model to be able to distinguish (cat vs. truck vs. wildebeest, cancerous tissue vs. normal tissue, etc.). Much of the focus on advancing machine learning algorithms is to encourage the learning of better representations that generalize better to new examples, problems or domains. This year, we looked at this problem in a number of different contexts:
In Predicting the Generalization Gap in Deep Neural Networks, we showed that it is possible to predict the generalization gap (the gap between a model’s performance on data from the training distribution versus data drawn from a different distribution) using statistics of the margin distribution, helping us better understand which models generalize most effectively. We also did some research on Improving Out-of-Distribution Detection in Machine Learning Models, to better understand when a model is starting to encounter kinds of data it has never seen before. We also looked at Off-Policy Classification in the context of reinforcement learning, to better understand which models are likely to generalize the best.
In Learning to Generalize from Sparse and Underspecified Rewards, we also examined ways of specifying reward functions for reinforcement learning that enable learning systems to more directly learn from true objectives and be less distracted with longer, less-desirable sequences of actions that happen to achieve desired goals by accident.
In this instruction-following task, the action trajectories a1, a2 and a3 reach the goal, but the sequences a2 and a3 do not follow the instructions. This illustrates the issue of underspecified rewards.
AutoML We continued our work on AutoML this year, an approach whereby algorithms that learn how to learn can automate many aspects of machine learning and often can achieve substantially better results than the best human machine learning experts for certain kinds of machine learning meta-decisions. In particular:
In EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling, we showed how to use neural architecture search techniques to achieve substantially better results on computer vision problems, including a new state-of-the-art result of 84.4% top-1 accuracy on ImageNet while having 8X fewer parameters than the previous best model.
Model Size vs. Accuracy Comparison. EfficientNet-B0 is the baseline network developed by AutoML MNAS, while Efficient-B1 to B7 are obtained by scaling up the baseline network. In particular, our EfficientNet-B7 achieves new state-of-the-art 84.4% top-1 / 97.1% top-5 accuracy, while being 8.4x smaller than the best existing CNN.
In Video Architecture Search, we describe how we extended our AutoML work to the domain of video models, finding architectures that achieve state-of-the-art results, and also lightweight architectures that match the performance of hand-crafted models while using 50x less computation.
TinyVideoNet (TVN) architectures evolved to maximize the recognition performance while keeping its computation time within the desired limit. For instance, TVN-1 (top) runs at 37 ms on a CPU and 10ms on a GPU. TVN-2 (bottom) runs at 65ms on a CPU and 13ms on a GPU.
We developed AutoML techniques for tabular data, unlocking an important domain where many companies and organizations have interesting data in relational databases, and often want to develop machine learning models on this data. We collaborated to release this technology as a new Google Cloud AutoML Tables product, and also discussed how well this system did in a new Kaggle competition in An End-to-End AutoML Solution for Tabular Data at KaggleDays (spoiler: AutoML Tables finished second out of 74 teams of expert data scientists).
InExploring Weight Agnostic Neural Networks, we showed how it is possible to find interesting neural network architectures without any training steps to update the weights of the evaluated models. This can make architecture search much more computationally efficient.
A weight-agnostic neural network performing a Cartpole Swing-up task at various different weight parameters, and also using fine-tuned weight parameters.
Applying AutoML to Transformer Architectures explored finding architectures for natural language processing tasks that significantly outperform vanilla Transformer models at substantially reduced computational costs.
Comparison between the Evolved Transformer and the original Transformer on WMT’14 En-De at varying sizes. The biggest gains in performance occur at smaller sizes, while ET also shows strength at larger sizes, outperforming the largest Transformer with 37.6% less parameters (models to compare are circled in green). See Table 3 in our paper for the exact numbers.
In SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition, we showed that the approach of automatically learning data augmentation methods can be extended to speech recognition models, with the learned augmentation approaches achieving significantly higher accuracy with less data than existing human ML-expert driven data augmentation approaches.
We launched our first speech application for keyword spotting and spoken language identification using AutoML. In our experiments we found better models (both more efficient and better performance) than the human designed models that have been in this setting for some time.
Natural Language Understanding The past few years have seen remarkable advances in models for natural language understanding, translation, natural dialog, speech recognition and related tasks. This year, one theme in our work was advancing the state of the art by combining modalities or tasks, to train more powerful and capable models. A few examples:
Left: Language pairs with larger amounts of training data generally have higher translation quality. Right: Multilingual training, where we train a single model for all language pairs rather than separate models for each language pair, results in substantial improvements in BLEU score (a measure of translation quality) for language pairs without much data.
Left: A traditional monolingual speech recognizer comprised of Acoustic, Pronunciation and Language Models for each language. Middle: A traditional multilingual speech recognizer where the Acoustic and Pronunciation model is multilingual, while the Language model is language-specific. Right: An E2E multilingual speech recognizer where the Acoustic, Pronunciation and Language Model is combined into a single multilingual model.
In Translatotron: An End-to-End Speech-to-Speech Translation Model, we showed that it is possible to train a joint model to accomplish the (normally separate) tasks of speech recognition, translation and text-to-speech generation with nice benefits, like preserving the sound of the speaker’s voice in the generated translated audio, as well as a simpler overall learning system.
In Robust Neural Machine Translation, we showed how to use an adversarial training procedure to significantly improve the quality and robustness of language translations.
Left: The Transformer model is applied to an input sentence (lower left) and, in conjunction with the target output sentence (above right) and target input sentence (middle right; beginning with the placeholder “<sos>”), the translation loss is calculated. The AdvGen function then takes the source sentence, word selection distribution, word candidates and the translation loss as inputs to construct an adversarial source example. Right: In the defense stage, the adversarial source example serves as input to the Transformer model and the translation loss is calculated. AdvGen then uses the same method as above to generate an adversarial target example from the target input.
As our language understanding capabilities have improved, based on fundamental research advances like seq2seq, Transformer, BERT, Transformer-XL and ALBERT models, we have seen increased use of these sorts of models in many of our core products and features like Google Translate, Gmail’s Smart Compose, and Google Search. This year, the launch of BERT in our core search and ranking algorithms led to the biggest improvement in search quality in the last five years (and one of the biggest ever), through better understanding of the subtle meanings of query and document words and phrases.
Machine Perception Models for better understanding of still images have made remarkable progress in the last decade. Among the next major frontiers are models and approaches for understanding the dynamic world in fine-grained detail. This includes deeper and more nuanced understanding of images and video, as well as live and situated perception: understanding the audiovisual world at interactive rates and with a shared spatial grounding with the user. This year, we explored many aspects of advances in this area, including:
Finer-grained visual understanding in Lens, enabling even more powerful visual search.
Helpful smart camera features such as Quick Gestures, Face Match and smart video call framing on the Nest Hub Max.
Technology for live and spatially-aware perception for helpfully augmenting the world around us through Lens.
Right: Input videos of people performing a squat exercise. The video on the top left is the reference. The other videos show nearest neighbor frames (in the TCC embedding space) from other videos of people doing squats. Left: The corresponding frame embeddings move as the action is performed.
Qualitative results from VideoBERT, pretrained on cooking videos. Top: Given some recipe text, we generate a sequence of visual tokens. Bottom: Given a visual token, we show the top three future tokens forecast by VideoBERT at different time scales. In this case, the model predicts that a bowl of flour and cocoa powder may be baked in an oven and may become a brownie or cupcake. We visualize the visual tokens using the images from the training set closest to the tokens in feature space.
We’re quite excited about the prospects of continued improvements in the understanding of the sensory world around us.
Robotics The application of machine learning to robotic control is a significant research area for us. We believe this is a vital tool for enabling robots to operate effectively in complex, real-world environments like everyday homes and businesses. Some of the work we did this year includes:
In PlaNet: A Deep Planning Network for Reinforcement Learning, we showed how to effectively learn a world model purely from the pixels of images, and how to leverage this model of how the world behaves in order to accomplish tasks with many fewer learning episodes.
In Unifying Physics and Deep Learning with TossingBot, we showed how robots can learn “intuitive” physics from experimentation in an environment, rather than being pre-programmed with physics models about the environment in which they are operating.
In Soft Actor-Critic: Deep Reinforcement Learning for Robotics, we showed that training a reinforcement learning algorithm to both maximize the expected reward (which is the standard RL objective) and to maximize the policy's entropy (so that learning favors policies that are more random), can help robots learn faster and be more robust to changes in their environment.
We introduced ROBEL: Robotics Benchmarks for Learning with Low-Cost Robots, an open-source platform of cost-effective robots and curated benchmarks designed to facilitate research and development on physical robotics hardware in the real world.
Helping Advance the Broader Developer and Researcher Community Open source is about more than code: it's about the community of contributors. It’s been an exciting year to be part of the open source community. We launched TensorFlow 2.0—the biggest TensorFlow release to date—which makes building ML systems and applications easier than ever. We added support for fast mobile GPU inference to TensorFlow Lite. We also launched Teachable Machine 2.0, a fast, easy web-based tool which can train a machine learning model with the click of a button, no coding required. We announced MLIR, open source machine learning compiler infrastructure that addresses the complexity of growing software and hardware fragmentation and makes it easier to build AI applications.
We open-sourced MediaPipe, a framework for building perceptual and multimodal applied ML pipelines, and XNNPACK, a library of efficient floating-point neural network inference operators. As of the end of 2019, we had enabled more than 1,500 researchers around the world to access Cloud TPUs for free via the TensorFlow Research Cloud. Our Intro To TensorFlow at Coursera crossed 100,000 students. And we engaged with thousands of users while taking TensorFlow on the road to 11 different countries, hosted our first ever TensorFlow World and more.
Open Datasets Open datasets with clear and measurable goals are often very helpful in driving forward the field of machine learning. To help the research community find interesting datasets, we continue to index a wide variety of open datasets sourced from many different organizations with Google Dataset Search. We also think it's important to create new datasets for the community to explore and to develop new techniques, and to ensure we share open data responsibly. This year, we additionally released a number of open datasets across many different areas:
Open Images V5: An update to the popular Open Images dataset that includes segmentation masks for 2.8 million objects in 350 categories (so that it now has ~9M images annotated with image-level labels, object bounding boxes, object segmentation masks, and visual relationships).
Natural questions: the first dataset to use naturally occurring queries and find answers by reading an entire page, rather than extracting answers from a short paragraph.
Google Research Football: a novel reinforcement learning environment where agents aim to master the world’s most popular sport—football (or, if you’re American, soccer). It’s important for reinforcement learning agents to have GOOOAAALLLSS!
Google-Landmarks-v2: over 5 million images (2x that of the first release) of more than 200 thousand different landmarks.
YouTube-8M Segments: A large-scale classification and temporal localization dataset that includes human-verified labels at the 5-second segment level of YouTube-8M videos.
PAWS and PAWS-X: To help with paraphrase identification, both datasets contain well-formed sentence pairs with high lexical overlap, in which around half of pairs are paraphrase and half are not.
Natural language dialog datasets: CCPE and Taskmaster-1 both use a Wizard-of-Oz platform that pairs two people who engage in spoken conversations, to mimic a human-level conversation with a digital assistant.
The Visual Task Adaptation Benchmark: VTAB follows similar guidelines to ImageNet and GLUE but is based on one principle—a better representation is one that yields better performance on unseen tasks, with limited in-domain data.
Schema-Guided Dialogue Dataset: the largest publicly available corpus of task-oriented dialogues, with over 18,000 dialogues spanning 17 domains.
Research Community Interaction Finally, we’ve been busy within the broader academic and research community. In 2019 Google researchers presented hundreds of papers, participated in numerous conferences and received many awards and other accolades. We had a strong presence at:
CVPR: ~250 Googlers presented 40+ papers, talks, posters, workshops and more.
ICML: ~200 Googlers presented 100+ papers, talks, posters, workshops and more.
ICLR: ~200 Googlers presented 60+ papers, talks, posters, workshops and more.
ACL: ~100 Googlers presented 40+ papers, workshops and tutorials.
Interspeech: Over 100 Googlers presented 30+ papers.
ICCV: ~200 Googlers presented 40+ papers, and several Googlers also won three prestigious ICCV awards.
NeurIPS: ~500 Googlers co-authored more than 120 accepted papers and engaged in various workshops and more.
We also brought together hundreds of Google researchers and faculty from across the globe to 15 separate research workshops hosted at Google locations. These workshops were on topics ranging from improving flood forecasting globally, to how to use machine learning to build systems that can better serve people with disabilities, to accelerating the development of algorithms, applications and tools for noisy-intermediate scale quantum (NISQ) processors.
New Places, New Faces We’ve made lots of headway in 2019, but there’s so much more we can do. To continue growing our impact around the world, we opened a Research office in Bangalore, and we’re expanding in other offices. If you’re excited about working on these sorts of problems, we’re hiring!
Looking Forward to 2020 and Beyond The past decade has seen remarkable advances in the fields of machine learning and computer science, where we now have given computers the ability to see, hear and understand language better than ever before (see a nice overview of important advances of the last decade). In our pockets, we now have sophisticated computing devices that can use these capabilities to better help us accomplish a multitude of tasks in our daily lives. We have substantially redesigned our computing platforms around these machine learning approaches by developing specialized hardware, giving us the ability to tackle ever larger problems. This has changed how we think about computing devices both in data centers (such as the inference-focused TPUv1 and the training-and-inference focused TPUv2 and TPUv3), as well as in low-power mobile environments (such as Edge TPUs). The deep learning revolution will continue to reshape how we think about computing and computers.
At the same time, there are a huge number of unanswered questions and unsolved problems. Some directions and questions that we are excited about tackling in 2020 and beyond are:
How can we build machine learning systems that can handle millions of tasks, and that can learn to successfully accomplish new tasks automatically? Currently, we’re mostly training separate machine models for each new task, starting from scratch, or at best, from a model trained on one or a few highly related tasks. As such, the models we train are really good at one or a few things, but not good at anything else. However, what we truly want are models that are good at leveraging their expertise at doing many things, so that they are able to learn to do a new thing with relatively little training data and computation. This is a true grand challenge which will require expertise and advances in many areas spanning solid-state circuit design, computer architecture, ML-focused compilers, distributed systems, machine learning algorithms and domain experts across many other fields in order to build systems that can generalize to solve new tasks independently across a full range of application areas.
How can we advance the state-of-the-art in important areas of artificial intelligence research like avoiding bias, increasing interpretability & understandability, improving privacy and ensuring safety? Advances in these areas are going to be critical as we use machine learning in more and more ways in society.
How can we apply computation and machine learning to make advances in important new areas of science? There are important advances to be had by collaborating with experts in other fields in areas like climate science, healthcare, bioinformatics and many other areas.
How can we ensure that the ideas and directions pursued by the machine learning and computer science research communities are put forth and explored by a diverse group of researchers? The work that the computer science and machine learning research communities are pursuing has broad implications for billions of people, and we want the set of researchers doing this work to represent the experiences, perspectives, concerns and creative enthusiasm of all the people of the world. How can we best support new researchers from diverse backgrounds entering the field?
Overall, 2019 was a very exciting year for research at Google and in the broader research community. We’re excited about tackling the research challenges ahead of us in 2020 and beyond, and we look forward to sharing our progress with you!
Andrew Helton, Editor, Google Research Communications
This week, Seoul, South Korea hosts the International Conference on Computer Vision 2019 (ICCV 2019), one of the world's premier conferences on computer vision. As a leader in computer vision research and a Gold Sponsor, Google will have a strong presence at ICCV 2019 with over 200 Googlers in attendance, more than 40 research presentations, and involvement in the organization of a number of workshops and tutorials.
If you are attending ICCV this year, please stop by our booth. There you can chat with researchers who are actively pursuing the latest innovations in computer vision and demo some of their latest research, including the technology behind MediaPipe, the new Open Images dataset, new developments for Google Lens and much more.
This year Google researchers are recipients of three prestigious ICCV awards:
Distinguished Researcher Award — Bill Freeman, Research Scientist, Google Research
Helmholtz Prize (Test of Time Award) — ICCV 2009 paper, "Building Rome in a Day", by Sameer Agarwal, Noah Snavely, Ian Simon, Steve Seitz and Rick Szeliski
Andrew Helton, Editor, Google Research Communications
This week, Graz, Austria hosts the 20th Annual Conference of the International Speech Communication Association (Interspeech 2019), one of the world‘s most extensive conferences on the research and engineering for spoken language processing. Over 2,000 experts in speech-related research fields gather to take part in oral presentations and poster sessions and to collaborate with streamed events across the globe.
As a Gold Sponsor of Interspeech 2019, we are excited to present 30 research publications, and demonstrate some of the impact speech technology has made in our products, from accessible, automatic video captioning to a more robust, reliable Google Assistant. If you’re attending Interspeech 2019, we hope that you’ll stop by the Google booth to meet our researchers and discuss projects and opportunities at Google that go into solving interesting problems for billions of people. Our researchers will also be on hand to discuss Google Cloud Text-to-Speech and Speech-to-text, demo Parrotron, and more. You can also learn more about the Google research being presented at Interspeech 2019 below (Google affiliations in blue).
Organizing Committee includes: Michiel Bacchiani
Technical Program Committee includes: Tara Sainath
Tutorials Neural Machine Translation Organizers include: Wolfgang Macherey, Yuan Cao Accepted Publications Building Large-Vocabulary ASR Systems for Languages Without Any Audio Training Data (link to appear soon) Manasa Prasad, Daan van Esch, Sandy Ritchie, Jonas Fromseier Mortensen
Multi-Microphone Adaptive Noise Cancellation for Robust Hotword Detection (link to appear soon) Yiteng Huang, Turaj Shabestary, Alexander Gruenstein, Li Wan
Improving Keyword Spotting and Language Identification via Neural Architecture Search at Scale (link to appear soon) Hanna Mazzawi, Javier Gonzalvo, Aleks Kracun, Prashant Sridhar, Niranjan Subrahmanya, Ignacio Lopez Moreno, Hyun Jin Park, Patrick Violette
Contextual Recovery of Out-of-Lattice Named Entities in Automatic Speech Recognition (link to appear soon) Jack Serrino, Leonid Velikovich, Petar Aleksic, Cyril Allauzen
An Investigation Into On-Device Personalization of End-to-End Automatic Speech Recognition Models (link to appear soon) Khe Chai Sim, Petr Zadrazil, Francoise Beaufays
Developing Pronunciation Models in New Languages Faster by Exploiting Common Grapheme-to-Phoneme Correspondences Across Languages (link to appear soon) Harry Bleyan, Sandy Ritchie, Jonas Fromseier Mortensen, Daan van Esch
Unified Verbalization for Speech Recognition & Synthesis Across Languages (link to appear soon) Sandy Ritchie, Richard Sproat, Kyle Gorman, Daan van Esch, Christian Schallhart, Nikos Bampounis, Benoit Brard, Jonas Mortensen, Amelia Holt, Eoin Mahon
Better Morphology Prediction for Better Speech Systems (link to appear soon) Dravyansh Sharma, Melissa Wilson, Antoine Bruguier
Large-Scale Visual Speech Recognition Brendan Shillingford, Yannis Assael, Matthew Hoffman, Thomas Paine, Cían Hughes, Utsav Prabhu, Hank Liao, Hasim Sak, Kanishka Rao, Lorrayne Bennett, Marie Mulville, Ben Coppin, Ben Laurie, Andrew Senior, Nando de Freitas
Posted by Tom Kwiatkowski and Michael Collins, Research Scientists, Google AI Language
Open-domain question answering (QA) is a benchmark task in natural language understanding (NLU) that aims to emulate how people look for information, finding answers to questions by reading and understanding entire documents. Given a question expressed in natural language ("Why is the sky blue?"), a QA system should be able to read the web (such as this Wikipedia page) and return the correct answer, even if the answer is somewhat complicated and long. However, there are currently no large, publicly available sources of naturally occurring questions (i.e. questions asked by a person seeking information) and answers that can be used to train and evaluate QA models. This is because assembling a high-quality dataset for question answering requires a large source of real questions and significant human effort in finding correct answers.
To help spur research advances in QA, we are excited to announce Natural Questions (NQ), a new, large-scale corpus for training and evaluating open-domain question answering systems, and the first to replicate the end-to-end process in which people find answers to questions. NQ is large, consisting of 300,000 naturally occurring questions, along with human annotated answers from Wikipedia pages, to be used in training QA systems. We have additionally included 16,000 examples where answers (to the same questions) are provided by 5 different annotators, useful for evaluating the performance of the learned QA systems. Since answering the questions in NQ requires much deeper understanding than is needed to answer trivia questions — which are already quite easy for computers to solve — we are also announcing a challenge based on this data to help advance natural language understanding in computers.
The Data NQ is the first dataset to use naturally occurring queries and focus on finding answers by reading an entire page, rather than extracting answers from a short paragraph. To create NQ, we started with real, anonymized, aggregated queries that users have posed to Google's search engine. We then ask annotators to find answers by reading through an entire Wikipedia page as they would if the question had been theirs. Annotators look for both long answers that cover all of the information required to infer the answer, and short answers that answer the question succinctly with the names of one or more entities. The quality of the annotations in the NQ corpus has been measured at 90% accuracy.
The Challenge NQ is aimed at enabling QA systems to read and comprehend an entire Wikipedia article that may or may not contain the answer to the question. Systems will need to first decide whether the question is sufficiently well defined to be answerable — many questions make false assumptions or are just too ambiguous to be answered concisely. Then they will need to decide whether there is any part of the Wikipedia page that contains all of the information needed to infer the answer. We believe that the long answer identification task — finding all of the information required to infer an answer — requires a deeper level of language understanding than finding short answers once the long answers are known.
It is our hope that the release of NQ, and the associated challenge, will help spur the development of more effective and robust QA systems. We encourage the NLU community to participate and to help close the large gap between the performance of current state-of-the-art approaches and a human upper bound. Please visit the challenge website to view the leaderboard and learn more.
Posted by Jeff Dean, Senior Fellow and Google AI Lead, on behalf of the entire Google Research Community
2018 was an exciting year for Google's research teams, with our work advancing technology in many ways, including fundamental computer science research results and publications, the application of our research to emerging areas new to Google (such as healthcare and robotics), open source software contributions and strong collaborations with Google product teams, all aimed at providing useful tools and services. Below, we highlight just some of our efforts from 2018, and we look forward to what will come in the new year. For a more comprehensive look, please see our publications in 2018.
Ethical Principles and AI Over the past few years, we have observed major advances in AI and the positive impact it can have on our products and the everyday lives of our billions of users. For those of us working in this field, we care deeply that AI is a force for good in the world, and that it is applied ethically, and to problems that are beneficial to society. This year we published the Google AI Principles, supported with a set of responsible AI practices outlining technical recommendations for implementation. In combination they provide a framework for us to evaluate our own development of AI, and we hope that other organizations can also use these principles to help shape their own thinking. It's important to note that because this field is evolving quite rapidly, best practices in some of the principles noted, such as "Avoid creating or reinforcing unfair bias" or "Be accountable to people", are also changing and improving as we and others conduct new research in areas like ML fairness and model interpretability. This research in turn leads to advances in our products to make them more inclusive and less biased, such as our work on reducing gender biases in Google Translate, and allows the exploration and release of more inclusive image datasets and models that enable computer vision to work for the diversity of global cultures. Furthermore, this work allows us to share best practices with the broader research community with the Fairness Module in the Machine Learning Crash Course.
AI for Social Good The potential of AI to make dramatic impacts on many areas of social and societal importance is clear. One example of how AI can be applied to real-world problems is our work on flood prediction. In collaboration with many teams across Google, this research aims to provide accurate and timely fine-grained information about the likely extent and scope of flooding, enabling those in flood-prone regions to make better decisions about how best to protect themselves and their property. A second example is our work on earthquake aftershock prediction, where we showed that a machine learning (ML) model can predict aftershock locations much more accurately than traditional physics-based models. Perhaps more importantly, because the ML model was designed to be interpretable, scientists have been able to make new discoveries about the behavior of aftershocks, leading to not only more accurate predictions, but also new levels of understanding.
We have also seen a huge number of external parties, sometimes in collaboration with Google researchers and engineers, using open source software like TensorFlow to tackle a wide range of scientific and social problems, such as using convolutional neural networks to identify humpback whale calls, detecting new exoplanets, identifying diseased cassava plants and more. To spur creative activity in this area, we announced the Google AI for Social Impact Challenge in collaboration with Google.org, whereby individuals and organizations can receive grants from a total of $25M of funding, along with mentorship and advice from Google research scientists, engineers and other experts as they work to take a project with large potential social impact from idea to reality.
Assistive Technology Much of our research centered on using ML and computer science to help our users accomplish things faster and more effectively. Often, these results in collaborations with various product teams to release the fruits of this research in various product features and settings. One example is Google Duplex, a system that requires research in natural language and dialogue understanding, speech recognition, text-to-speech, user understanding and effective UI design to all come together to enable an experience whereby a user can say "Can you book me a haircut at 4 PM today?", and a virtual agent will interact on your behalf over the telephone to handle the necessary details.
Other examples include Smart Compose, a tool that uses predictive models to give relevant suggestions about how to compose emails, making the process of email composition faster and easier, and Sound Search, a technology built on the Now Playing feature that enables you to discover what song is playing fast and accurately. Additionally, Smart Linkify in Android shows how we can use an on-device ML model to make many different kinds of text that appear on the screen of your phone more useful by understanding the kind of text you're selecting (e.g. knowing that something is an address, so we can offer a shortcut to a maps or direction link).
Quantum computing Quantum computing is an emerging paradigm for computing that promises the ability to solve challenging problems that no classical computer can solve. We have been actively pursuing research in this area for the past several years, and we believe the field is on the cusp of demonstrating this capability for at least one problem (so-called quantum supremacy), which will be a watershed event for the field. Over the last year we produced a number of exciting new results, including the development of Bristlecone, a new 72-qubit quantum computing device, which scales the size of problems that can be tackled in quantum computers in the run-up towards quantum supremacy.
A Bristlecone chip being installed by Research Scientist Marissa Giustina at the Quantum AI Lab in Santa Barbara.
Natural Language Understanding Natural language research at Google had an exciting 2018, with a mix of basic research as well as product-focused collaborations. We developed improvements to our Transformer work from 2017, resulting in a new parallel-in-time version of the model called the Universal Transformer that shows strong gains across a number of natural language tasks including translation and linguistic reasoning. We also developed BERT, the first deeply bidirectional, unsupervised language representation, pre-trained using only a plain text corpus, that can then be fine-tuned on a wide variety of natural language tasks using transfer learning. BERT shows significant improvements over previous state-of-the-art results on 11 natural language tasks.
BERT also improves the state-of-the-art by 7.6% absolute on the very challenging GLUE benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks.
In addition to collaborating with various research teams to enable Smart Compose and Duplex (discussed previously), we worked to make the Google Assistant handle multilingual use cases better, with the goal of making the Assistant naturally conversational for all users.
Perception Our perception research tackles the hard problems of allowing computers to understand images, sounds, music and video, as well as providing more powerful tools for image capture, compression, processing, creative expression, and augmented reality. In 2018, our technology improved Google Photos' ability to organize the content that users most care about, such as people and pets. Google Lens and the Assistant enabled users to learn about the natural world, answer questions in real-time, and do more with Lens in Google Images. A key aspect of the Google AI mission is to empower others to benefit from our technology, and we've made a lot of progress this year in improving capabilities and building blocks that are parts of Google APIs. Examples include improved and new capabilities in vision and video in Cloud ML APIs and face-related on-device building blocks through ML Kit.
Google Lens can help you learn more about the world around you. Here, Lens identifies the breed of this dog. Learn more in this blog post.
In 2018, our contributions to academic research included advances in deep learning for 3D scene understanding, such as stereo magnification, which enables synthesizing novel photorealistic views of a scene. Our ongoing research on better understanding images and video enables users to find, organize, enhance and improve images and video in Google products such as Photos, YouTube, Search and more. In 2018, notable advances included a fast bottom-up model for joint pose estimation and person instance segmentation, a system for visualizing complex motion, a system which models spatio-temporal relations between people and objects and improvements in video action recognition based on distillation and 3D convolutions.
In the audio domain, we proposed a method for unsupervised learning of semantic audio representations as well as significant improvements to expressive and human-like speech synthesis. Multimodal perception is an increasingly important research topic. Looking to Listen combines visual and auditory cues in an input video to isolate and enhance the speech of desired speakers in a video. This technology could support a range of applications, from speech enhancement and recognition in videos, through video conferencing, to improved hearing aids, especially in situations where multiple people are speaking.
Enabling perception on resource-constrained platforms has becoming increasingly important. MobileNetV2 is Google's next-generation mobile computer vision model and our MobileNets are used widely across academia and industry. MorphNet proposes an efficient method for learning the structure of deep networks that results in across-the-board performance improvements on image and audio models while respecting computational resource constraints, and more recent work on automatic generation of mobile network architectures demonstrates that even higher performance is possible.
Computational Photography The improvements in quality and versatility of cell phone cameras over the last few years has been nothing short of remarkable. A modest part of this is improvements in the actual physical sensors used in phones, but a much greater part of it is due to advances in the scientific field of computational photography. Our research teams publish their new research techniques, and work closely with the Android and Consumer Hardware teams at Google to deliver this research into your hands in the latest Pixel and Android phones and other devices. In 2014, we introduced HDR+, a technique whereby the camera captures a burst of frames, aligns the frames in software, and merges them together with computational software. Originally in the HDR+ work, this was to enable pictures to have higher dynamic range than was possible with a single exposure. However, capturing a burst of frames and then performing computational analysis of these frames is a general approach that has enabled many advances in cameras in 2018. For example, it allowed the development of Motion Photos in Pixel 2 and the Augmented Reality mode in Motion Stills.
Motion photos on the Pixel 2 in Google Photos. For more examples, check out this Google Photos album.
Augmented chicken family with Motion Stills AR mode.
This year, one of our primary efforts in computational photography research was to create a new capability called Night Sight, which enables Pixel phone cameras to "see in the dark", earning praise by both press and users. Of course, Night Sight is just one of the new software-enabled camera features our teams have developed to help you take the perfect photo, including using ML to provide better portrait mode shots, seeing better and further with Super Res Zoom and capturing special moments with Top Shot and Google Clips.
Performance comparison of ADAM and AMSGRAD on a synthetic example of a simple one dimensional convex problem inspired by our examples of non-convergence. The first two plots (left and center) are for the online setting and the the last one (right) is for the stochastic setting.
Software Systems A large part of our research on software systems continues to relate to building machine-learning models and to TensorFlow in particular. For example, we published on the design and implementation of dynamic control flow for TensorFlow 1.0. Some of our newer research introduces a system that we call Mesh TensorFlow, which makes it easy to specify large-scale distributed computations with model parallelism, sometimes with billions of parameters. As another example, we released a library for scalable deep neural ranking using TensorFlow.
The TF-Ranking library supports multi-item scoring architecture, an extension of traditional single-item scoring.
We also released JAX, an accelerator-backed variant of NumPy that supports automatic differentiation of Python functions to arbitrary order. While JAX is not part of TensorFlow, it leverages some of the same underlying software infrastructure (e.g. XLA), and some of its ideas and algorithms have been helpful to our TensorFlow projects. Finally, we continued our research on the security and privacy of machine learning, and our development of open source frameworks for safety and privacy in AI systems, such as CleverHans and TensorFlow Privacy.
Another important research direction for us is the application of ML to software systems, at many levels of the stack. For instance, we continued work on placement of computations onto devices, with a hierarchical model, and we contributed to learning memory access patterns. We also continued to explore how learned indices could be used to replace traditional index structures in database systems and storage systems. As I wrote last year, we believe that we are just scratching the surface in terms of the use of machine learning in computer systems.
The Hierarchical Planner's placement of a NMT (4-layer) model. White denotes CPU and the four colors each represent one of the GPUs. Note that every step of every layer is allocated across multiple GPUs. This placement is 53.7% faster than that generated by a human expert.
In 2018 we learned about Spectre and Meltdown, new classes of serious security vulnerabilities in modern computer processors, thanks to Google's Project Zero team in collaboration with others. These and related vulnerabilities will keep computer architecture researchers quite busy. In our continuing efforts to model CPU behavior, our Compiler Research team integrated their tool for measuring machine instruction latency and port pressure into LLVM, making possible better compilation decisions.
Google products, our Cloud offerings and inference for machine learning models depend critically on the ability to provide large-scale, reliable, efficient technical infrastructure for computing, storage and networking. A few research highlights from the past year include the evolution of Google's Software Defined Networking WAN, a stand-alone, federated query processing platform that executes SQL queries against data stored in different file-based formats, in many storage systems (BigTable, Spanner, Google Spreadsheets, etc.) and a report on our extensive use of code review, investigating the motivations behind code review at Google, current practices, and developers' satisfaction and challenges.
Running a large-scale web service such as content hosting, requires load balancing with stability in a dynamic environment. We developed a consistent hashing scheme with tight provable guarantees on the maximum load of each server, and deployed it for our cloud customers in Google Cloud Pub/Sub. After making an earlier version of our paper available, engineers at Vimeo found the paper, implemented and open sourced it in haproxy, and used it for their load balancing project at Vimeo. The results were dramatic: applying these algorithmic ideas helped them decrease the cache bandwidth by a factor of almost 8, eliminating a scaling bottleneck.
AdaNet adaptively growing an ensemble of neural networks. At each iteration, it measures the ensemble loss for each candidate, and selects the best one to move onto the next iteration.
TPUs Tensor Processing Units (TPUs) are Google's internally-developed ML hardware accelerators, designed from the ground up to power both training and inference at scale. TPUs have enabled Google research breakthroughs such as BERT (discussed previously), and they also allow researchers around the world to build on Google research via open source and to pursue new breakthroughs of their own. For example, anyone can fine-tune BERT on TPUs for free via Colab, and the TensorFlow Research Cloud has given thousands of researchers the opportunity to benefit from even larger amounts of free Cloud TPU computing power. We've also made multiple generations of TPU hardware commercially available as Cloud TPUs, including ML supercomputers called Cloud TPU Pods that make large-scale ML training much more accessible. Internally, in addition to enabling faster advances in ML research, TPUs have driven major improvements across Google's core products, including Search, YouTube, Gmail, Google Assistant, Google Translate, and many others. We look forward to seeing ML teams both here at Google and elsewhere achieve even more with ML via the unprecedented computing scale that TPUs provide.
An individual TPU v3 device (left) and a portion of a TPU v3 Pod (right). TPU v3 is the latest generation of Google's Tensor Processing Unit (TPU) hardware. Available to external customers as Cloud TPU v3, these systems are liquid-cooled for maximum performance (computer chips + liquid = exciting!), and a full TPU v3 Pod can apply more than 100 petaflops of computational power to the world's largest ML problems.
Open Source Software and Datasets Releasing open source software and the creation of new public datasets are two major ways that we contribute to the research and software engineering communities. One of our largest efforts in this space is TensorFlow, a widely popular system for ML computations that we released in November 2015. We celebrated TensorFlow's third birthday in 2018, and during this time, TensorFlow has been downloaded more than 30M times, with over 1700 contributors adding 45,000 commits. In 2018, TensorFlow had eight major releases and added major capabilities such as eager execution and distribution strategies. We launched public design reviews engaging the community in the development process, and we engaged contributors via special interest groups. With the launches of associated products such as TensorFlow Lite, TensorFlow.js and TensorFlow Probability, the TensorFlow ecosystem grew dramatically in 2018.
We are happy that TensorFlow has the strongest Github user retention of the top machine learning and deep learning frameworks. The TensorFlow team is also working to address Github issues faster and provide a smooth path for external contributors. In research, we continue to power much of the world's machine learning and deep learning research on a published paper basis according to Google Scholar data. TensorFlow Lite is now on more than 1.5B devices globally after being available for just one year. Additionally, TensorFlow.js is the number one ML framework for JavaScript; in the nine months since launch, it had over 2M Content Delivery Network (CDN) hits, 250K downloads and more than 10,000 stars on Github.
Real-time evolution of the tSNE embedding for the complete MNIST dataset. The dataset contains images of 60,000 handwritten digits. You can find a live demo here.
Public datasets are often a great source of inspiration that lead to great progress across many fields, since they give the broader community both access to interesting data and problems as well as a healthy competitive drive to achieve better results on a variety of tasks. This year we were happy to release Google Dataset Search, a new tool for finding public datasets from all of the web. Over the years we have also curated and released many new, novel datasets, including everything from millions of general annotated images or videos, to a crowd-source Bengali dataset for speech recognition to robot arm grasping datasets and more. In 2018, we added even more datasets to that list.
Pictures from India & Singapore added to Open Images Extended using the Crowdsource app.
Visualization of the fluid annotation interface in action on image from COCO dataset. Image credit: gamene, original image.
From time-to-time, we also help establish new kinds of challenges for the research community, so that we can all work together on solving difficult research problems. Often these are done with the release of a new dataset, but not always. This year, we established new challenges around the Inclusive Images Challenge, to work towards making more robust models that are free from many kinds of biases, the iNaturalist 2018 Challenge which aims to enable computers' fine-grained discrimination of visual categories (such as species of plants in an image), a Kaggle "Quick, Draw!" Doodle Recognition Challenge to create a better classifier for the QuickDraw challenge game, and Conceptual Captions, a larger-scale image captioning dataset and challenge aimed at enabling better image captioning model research.
Applications of AI to Other Fields In 2018, we have applied ML to a wide variety of problems in the physical and biological sciences. Using ML, we can supply scientists with the equivalent of hundreds or thousands of research assistants digging through data, which then frees the scientists to become more creative and productive.
A pre-trained TensorFlow model rates focus quality for a montage of microscope image patches of cells in Fiji (ImageJ). Hue and lightness of the borders denote predicted focus quality and prediction uncertainty, respectively.
Health For the past several years, we have been applying ML to health, an area that affects every one of us, and is also one where we believe ML can make a tremendous difference by augmenting the intuitions and experience of healthcare professionals. Our general approach in this space is to collaborate with healthcare organizations to tackle basic research problems (using feedback from clinical experts to make our results more robust), and then publish the results in well-respected, peer-reviewed scientific and clinical journals. Once the research has been clinically and scientifically validated, we then conduct user and HCI research to understand how we can deploy this in real-world clinical settings. In 2018, we expanded our efforts across the broad space of computer-aided diagnostics to clinical task predictions as well.
At the end of 2016, we published work showing that a model trained to assess retinal fundus images for signs of diabetic retinopathy was able to perform on-par to slightly-better than U.S. medical-board-certified ophthalmologists at this task in a retrospective study. In 2018, we were able to show that by having the training images labeled by retinal specialists and by using an adjudicated protocol (where multiple retinal specialists convene and have to arrive at a single collective assessment for each fundus image), we could arrive at a model that is on-par with retinal specialists. Later, we published an evaluation that showed how pairing ophthalmologists and this ML model allow them to make more accurate decisions than either alone. We have deployed this diabetic retinopathy detection system in partnership with our Alphabet colleagues at Verily at over 10 sites including Aravind Eye Hospitals in India and at Rajavithi Hospital affiliated with the Ministry of Health in Thailand.
On the left is a retinal fundus image graded as having moderate DR ("Mo") by an adjudication panel of ophthalmologists (ground truth). On the top right is an illustration of the predicted scores ("N" = no DR, "Mi" = Mild DR, "Mo" = Moderate DR) from the model. On the bottom right is the set of scores given by physicians without assistance ("Unassisted") and those who saw the model's predictions ("Grades Only").
When applying ML to historically-collected data, it's important to understand the populations that have experienced human and structural biases in the past and how those biases have been codified in the data. Machine-learning offers an opportunity to detect and address bias and to proactively advance health equity, which we are designing our systems to do.
Research Outreach We interact with the external research community in many different ways, including faculty engagement and student support. We are proud to host hundreds of undergraduate, M.S. and Ph.D. students as interns during the academic year, as well as providing multi-year Ph.D. fellowships to students throughout North America, Europe, and the Middle East. In addition to financial support, each of the fellowship recipients is assigned one or more Google researchers as a mentor, and we bring together all the fellows for an annual Google Ph.D. Fellowship Summit, where they are exposed to state-of-the-art research being pursued at Google and given the opportunity to network with Google's researchers as well as other PhD Fellows from around the world. Complementing this fellowship program is the Google AI Residency, a way of allowing people who want to learn to conduct deep learning research to spend a year working alongside and being mentored by researchers at Google. Now in its third year, residents are embedded in various teams across Google's global offices, pursuing research in areas such as machine learning, perception, algorithms and optimization, language understanding, healthcare and much more. With applications having just closed for the fourth year of this program, we are excited to see the research the new cohort of residents will pursue in 2019.
Each year, we also support a number of faculty members and students on research projects through our Google Faculty Research Awards program. In 2018, we also continued to host workshops at Google locations for faculty and graduate students in particular areas, including a workshop on AI/ML Research and Practice hosted in our Bangalore, India office, an Algorithms & Optimization Workshop hosted in our Zürich office, a workshop on healthcare applications of ML hosted in Sunnyvale and a workshop on Fairness and Bias in ML hosted in our Cambridge, MA office.
We believe that contributing openly to the broader research community is a critical part of supporting a healthy and productive research ecosystem. In addition to our open source and dataset releases, much of our research is published openly in top conference venues and journals, and we actively participate in the organization and sponsorship of conferences, all across the spectrum of different disciplines. For just a small sample, see our involvement at ICLR 2018, NAACL 2018, ICML 2018, CVPR 2018, NeurIPS 2018, ECCV 2018 and EMNLP 2018. Googlers also participated extensively in ASPLOS, HPCA, ICSE, IEEE Security & Privacy, OSDI, SIGCOMM, and many other conferences in 2018.
New Places, New Faces In 2018, we were excited to welcome many new people with a wide range of backgrounds into our research organization. We announced our first AI research office in Africa, located in Accra, Ghana. We expanded our AI research presence in Paris, Tokyo and Amsterdam, and opened a research lab in Princeton. We continue to hire talented people into our offices all over the world, and you can learn more about joining our research efforts here.
Looking Forward to 2019 This blog post summarizes just a small fraction of the research performed in 2018. As we look back on 2018, we're excited (and proud!) of the breadth and depth of what we have accomplished. In 2019, we look forward to having even more impact on Google's direction and products, as well as on the broader research and engineering community!
Posted by Jarrod McClean, Senior Research Scientist and Hartmut Neven, Director of Engineering, Google AI Quantum Team
Since its inception, the Google AI Quantum team has pushed to understand the role of quantum computing in machine learning. The existence of algorithms with provable advantages for global optimization suggest that quantum computers may be useful for training existing models within machine learning more quickly, and we are building experimental quantum computers to investigate how intricate quantum systems can carry out these computations. While this may prove invaluable, it does not yet touch on the tantalizing idea that quantum computers might be able to provide a way to learn more about complex patterns in physical systems that conventional computers cannot in any reasonable amount of time.
Today we talk about two recent papers from the Google AI Quantum team that make progress towards understanding the power of quantum computers for learning tasks. The first constructs a quantum model of neural networks to investigate how a popular classification task might be carried out on quantum processors. In the second paper, we show how peculiar features of quantum geometry change the strategies for training these networks in comparison to their classical counterparts, and offer guidance towards more robust training of these networks.
In “Classification with Quantum Neural Networks on Near Term Processors”, we construct a model of quantum neural networks (QNNs) that is specifically designed to work on quantum processors that are expected to be available in the near term. While the current work is primarily theoretical, their structure facilitates implementation and testing on quantum computers in the immediate future. These QNNs can be adapted through supervised learning of labeled data, and we show that it is possible to train a QNN to classify images in the famous MNIST dataset. Follow up work in this area with larger quantum devices may pit the ability of quantum networks to learn patterns against popular classical networks.
Quantum Neural Network for classification. Here we depict a sample quantum neural network, where in contrast to hidden layers in classical deep neural networks, the boxes represent entangling actions, or “quantum gates”, on qubits. In a superconducting qubit setup this could be enacted through a microwave control pulse corresponding to each box.
In “Barren Plateaus in Quantum Neural Network Training Landscapes”, we focus on the training of quantum neural networks, and probe questions related to a key difficulty in classical neural networks, which is the problem of vanishing or exploding gradients. In conventional neural networks, a good unbiased initial guess for the neuron weights often involves randomization, although there can be some difficulties as well. Our paper shows that peculiar features of quantum geometry unequivocally prevent this from being a good strategy in the quantum case, instead taking you to barren plateaus. The implications of this work may guide future strategies for initializing and training quantum neural networks.
QNN vanishing gradient: concentration of measure in high dimensional spaces. In very high dimensional spaces, such as those explored by quantum computers, the vast majority of states counterintuitively sit near the equator of the hypersphere (left). This means that any smooth function on this space will tend to take a value very close to its mean with overwhelming probability when selected at random (right).
This research sets the stage for improvements in both the construction and training of quantum neural networks. In particular, experimental realizations of quantum neural networks using hardware at Google will enable rapid exploration of quantum neural networks in the near term. We hope that the insights from the geometry of these states will lead to new algorithms to train these networks that will be essential to unlocking their full potential.
Posted by Anna Ukhanova, Program Manager, Google AI Zürich
Progress in machine learning (ML) is happening so rapidly, that it can sometimes feel like any idea or algorithm more than 2 years old is already outdated or superseded by something better. However, old ideas sometimes remain relevant even when a large fraction of the scientific community has turned away from them. This is often a question of context: an idea which may seem to be a dead end in a particular context may become wildly successful in a different one. In the specific case of deep learning (DL), the growth of both the availability of data and computing power renewed interest in the area and significantly influenced research directions.
The NIPS 2008 paper “The Trade-Offs of Large Scale Learning” by Léon Bottou (then at NEC Labs, now at Facebook AI Research) and Olivier Bousquet (Google AI, Zürich) is a good example of this phenomenon. As the recent recipient of the NeurIPS 2018 Test of Time Award, this seminal work investigated the interplay between data and computation in ML, showing that if one is limited by computing power but can make use of a large dataset, it is more efficient to perform a small amount of computation on many individual training examples rather than to perform extensive computation on a subset of the data. This demonstrated the power of an old algorithm, stochastic gradient descent, which is nowadays used in pretty much all applications of DL.
Optimization and the Challenge of Scale Many ML algorithms can be thought of as the combination of two main ingredients:
A model, which is a set of possible functions that will be used to fit the data.
An optimization algorithm which specifies how to find the best function in that set.
Back in the 90’s the datasets used in ML were much smaller than the ones in use today, and while artificial neural networks had already led to some successes, they were considered hard to train. In the early 2000’s, with the introduction of Kernel Machines (SVMs in particular), neural networks went out of fashion. Simultaneously, the attention shifted away from the optimization algorithms that had been used to train neural networks (stochastic gradient descent) to focus on those used for kernel machines (quadratic programming). One important difference being that in the former case, training examples are used one at a time to perform gradient steps (this is called “stochastic”), while in the latter case, all training examples are used at each iteration (this is called “batch”).
As the size of the training sets increased, the efficiency of optimization algorithms to handle large amounts of data became a bottleneck. For example, in the case of quadratic programming, running time scales at least quadratically in the number of examples. In other words, if you double your training set size, your training will take at least 4 times longer. Hence, lots of effort went into trying to make these algorithms scale to larger training sets (see for example Large Scale Kernel Machines).
People who had experience with training neural networks knew that stochastic gradient descent was comparably easier to scale to large datasets, but unfortunately its convergence is very slow (it takes lots of iterations to reach an accuracy comparable to that of a batch algorithm), so it wasn’t clear that this would be a solution to the scaling problem.
Stochastic Algorithms Scale Better In the context of ML, the number of iterations needed to optimize the cost function is actually not the main concern: there is no point in perfectly tuning your model since you will essentially “overfit” to the training data. So why not reduce the computational effort that you put into tuning the model and instead spend the effort processing more data?
The work of Léon and Olivier provided a formal study of this phenomenon: by considering access to a large amount of data and assuming the limiting factor is computation, they showed that it is better to perform a minimal amount of computation on each individual training example (thus processing more of them) rather than performing extensive computation on a smaller amount of data.
In doing so, they also demonstrated that among various possible optimization algorithms, stochastic gradient descent is the best. This was confirmed by many experiments and led to a renewed interest in online optimization algorithms which are now in extensive use in ML.
Mysteries Remain In the following years, many variants of stochastic gradient descent were developed both in the convex case and in the non-convex one (particularly relevant for DL). The most common variant now is the so-called “mini-batch” SGD where one considers a small number (~10-100) of training examples at each iteration, and performs several passes over the training set, with a couple of clever tricks to scale the gradient appropriately. Most ML libraries provide a default implementation of such an algorithm and it is arguably one of the pillars of DL.
While this analysis provided a solid foundation for understanding the properties of this algorithm, the amazing and sometimes surprising successes of DL continue to raise many more questions for the scientific community. In particular, the role of this algorithm in the generalization properties of deep networks has been repeatedly demonstrated but is still poorly understood. This means that a lot of fascinating questions are yet to be explored which could lead to a better understanding of the algorithms currently in use and the development of even more efficient algorithms in the future.
The perspective proposed by Léon and Olivier in their collaboration 10 years ago provided a significant boost to the development of the algorithm that is nowadays the workhorse of ML systems that benefit our lives daily, and we offer our sincere congratulations to both authors on this well-deserved award.





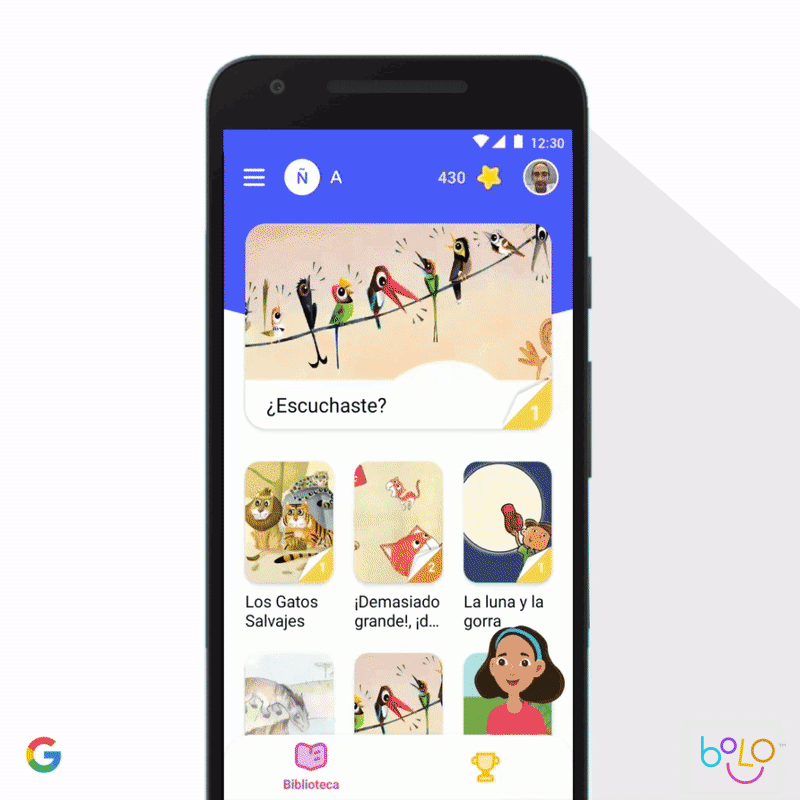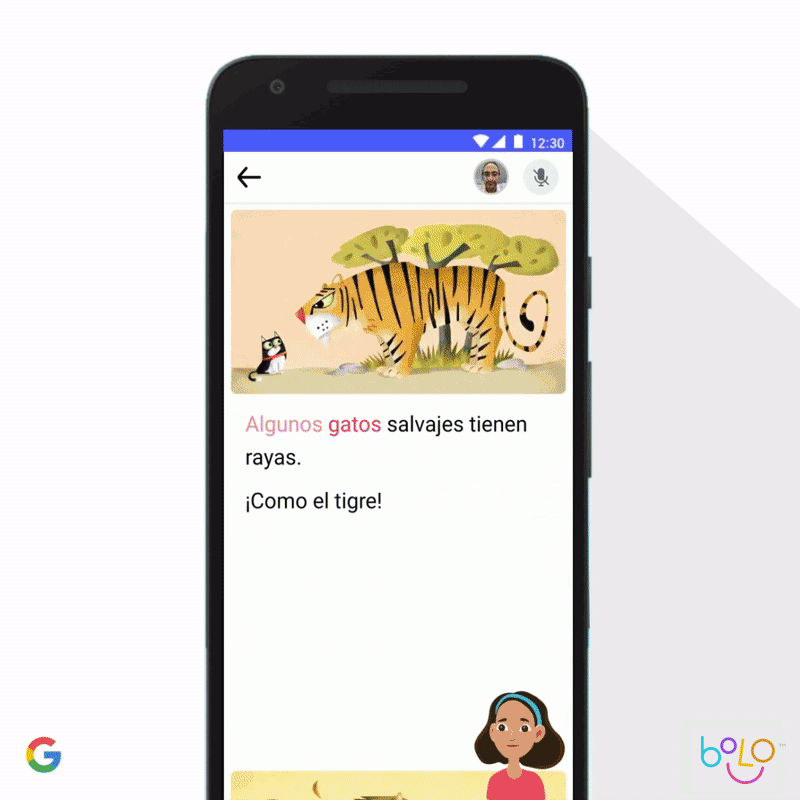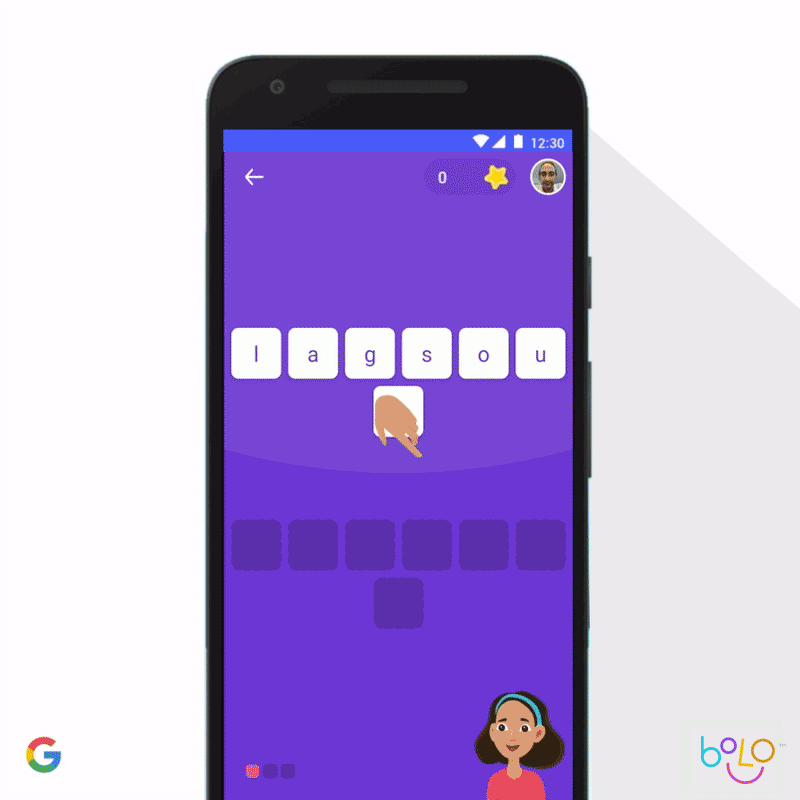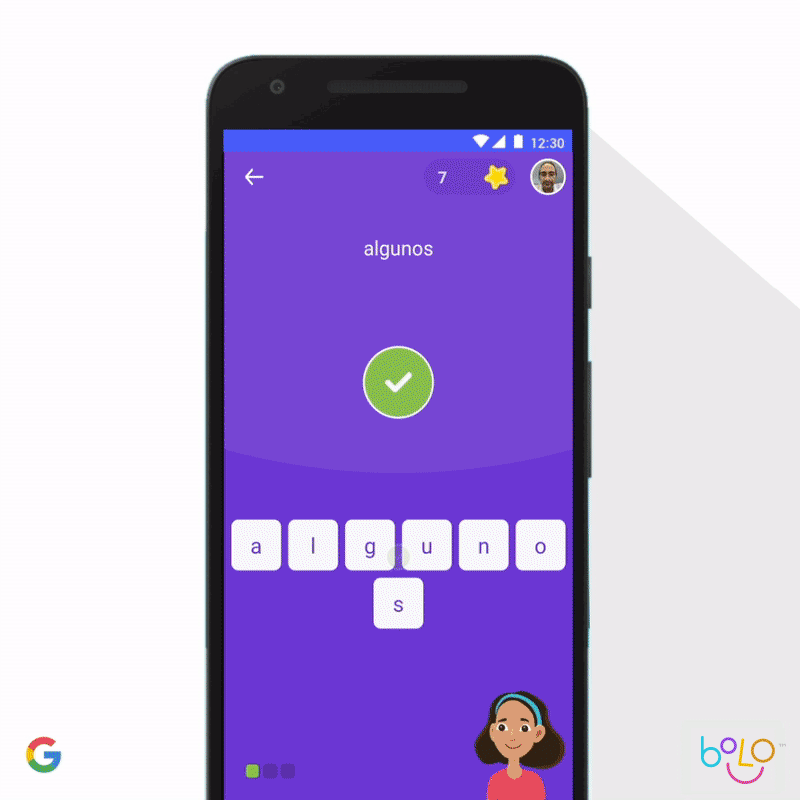























































{kind=link}
{kind=link}