Over the past decade, neural networks have achieved state-of-the-art results in a wide variety of prediction tasks, including image classification, machine translation, and speech recognition. These successes have been driven, at least in part, by hardware and software improvements that have significantly accelerated neural network training. Faster training has directly resulted in dramatic improvements to model quality, both by allowing more training data to be processed and by allowing researchers to try new ideas and configurations more rapidly. Today, hardware developments like Cloud TPU Pods are rapidly increasing the amount of computation available for neural network training, which raises the possibility of harnessing additional computation to make neural networks train even faster and facilitate even greater improvements to model quality. But how exactly should we harness this unprecedented amount of computation, and should we always expect more computation to facilitate faster training?
The most common way to utilize massive compute power is to distribute computations between different processors and perform those computations simultaneously. When training neural networks, the primary ways to achieve this are model parallelism, which involves distributing the neural network across different processors, and data parallelism, which involves distributing training examples across different processors and computing updates to the neural network in parallel. While model parallelism makes it possible to train neural networks that are larger than a single processor can support, it usually requires tailoring the model architecture to the available hardware. In contrast, data parallelism is model agnostic and applicable to any neural network architecture – it is the simplest and most widely used technique for parallelizing neural network training. For the most common neural network training algorithms (synchronous stochastic gradient descent and its variants), the scale of data parallelism corresponds to the batch size, the number of training examples used to compute each update to the neural network. But what are the limits of this type of parallelization, and when should we expect to see large speedups?
In "Measuring the Effects of Data Parallelism in Neural Network Training", we investigate the relationship between batch size and training time by running experiments on six different types of neural networks across seven different datasets using three different optimization algorithms ("optimizers"). In total, we trained over 100K individual models across ~450 workloads, and observed a seemingly universal relationship between batch size and training time across all workloads we tested. We also study how this relationship varies with the dataset, neural network architecture, and optimizer, and found extremely large variation between workloads. Additionally, we are excited to share our raw data for further analysis by the research community. The data includes over 71M model evaluations to make up the training curves of all 100K+ individual models we trained, and can be used to reproduce all 24 plots in our paper.
Universal Relationship Between Batch Size and Training Time
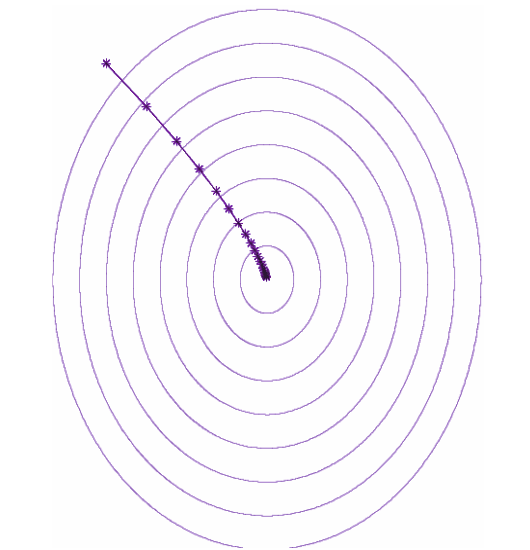
In an idealized data parallel system that spends negligible time synchronizing between processors, training time can be measured in the number of training steps (updates to the neural network's parameters). Under this assumption, we observed three distinct scaling regimes in the relationship between batch size and training time: a "perfect scaling" regime where doubling the batch size halves the number of training steps required to reach a target out-of-sample error, followed by a regime of "diminishing returns", and finally a "maximal data parallelism" regime where further increasing the batch size does not reduce training time, even assuming idealized hardware.
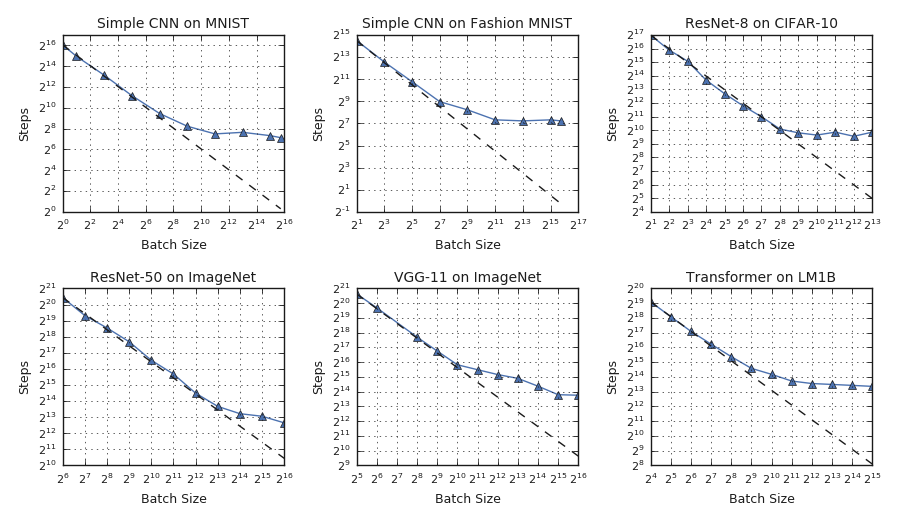 |
| For all workloads we tested, we observed a universal relationship between batch size and training speed with three distinct regimes: perfect scaling (following the dashed line), diminishing returns (diverging from the dashed line), and maximal data parallelism (where the trend plateaus). The transition points between the regimes vary dramatically between different workloads. |
Optimizing Workloads
If one could predict which workloads benefit most from data parallel training, then one could tailor their workloads to make maximal use of the available hardware. However, our results suggest that this will often not be straightforward, because the maximum useful batch size depends, at least somewhat, on every aspect of the workload: the neural network architecture, the dataset, and the optimizer. For example, some neural network architectures can benefit from much larger batch sizes than others, even when trained on the same dataset with the same optimizer. Although this effect sometimes depends on the width and depth of the network, it is inconsistent between different types of network and some networks do not even have obvious notions of "width" and "depth". And while we found that some datasets can benefit from much larger batch sizes than others, these differences are not always explained by the size of the dataset—sometimes smaller datasets benefit more from larger batch sizes than larger datasets.
 |
| Left: A transformer neural network scales to much larger batch sizes than an LSTM neural network on the LM1B dataset. Right: The Common Crawl dataset does not benefit from larger batch sizes than the LM1B dataset, even though it is 1,000 times the size. |
Future Work
Utilizing additional data parallelism by increasing the batch size is a simple way to produce valuable speedups across a range of workloads, but, for all the workloads we tried, the benefits diminished within the limits of state-of-the-art hardware. However, our results suggest that some optimization algorithms may be able to consistently extend the perfect scaling regime across many models and data sets. Future work could perform the same measurements with other optimizers, beyond the few closely-related ones we tried, to see if any existing optimizer extends perfect scaling across many problems.
Acknowledgements
The authors of this study were Chris Shallue, Jaehoon Lee, Joe Antognini, Jascha Sohl-Dickstein, Roy Frostig and George Dahl (Chris and Jaehoon contributed equally). Many researchers have done work in this area that we have built on, so please see our paper for a full discussion of related work.