
A key feature of human intelligence is that humans can learn to perform new tasks by reasoning using only a few examples. Scaling up language models has unlocked a range of new applications and paradigms in machine learning, including the ability to perform challenging reasoning tasks via in-context learning. Language models, however, are still sensitive to the way that prompts are given, indicating that they are not reasoning in a robust manner. For instance, language models often require heavy prompt engineering or phrasing tasks as instructions, and they exhibit unexpected behaviors such as performance on tasks being unaffected even when shown incorrect labels.
In “Symbol tuning improves in-context learning in language models”, we propose a simple fine-tuning procedure that we call symbol tuning, which can improve in-context learning by emphasizing input–label mappings. We experiment with symbol tuning across Flan-PaLM models and observe benefits across various settings.
- Symbol tuning boosts performance on unseen in-context learning tasks and is much more robust to underspecified prompts, such as those without instructions or without natural language labels.
- Symbol-tuned models are much stronger at algorithmic reasoning tasks.
- Finally, symbol-tuned models show large improvements in following flipped-labels presented in-context, meaning that they are more capable of using in-context information to override prior knowledge.
 |
| An overview of symbol tuning, where models are fine-tuned on tasks where natural language labels are replaced with arbitrary symbols. Symbol tuning relies on the intuition that when instruction and relevant labels are not available, models must use in-context examples to learn the task. |
Motivation
Instruction tuning is a common fine-tuning method that has been shown to improve performance and allow models to better follow in-context examples. One shortcoming, however, is that models are not forced to learn to use the examples because the task is redundantly defined in the evaluation example via instructions and natural language labels. For example, on the left in the figure above, although the examples can help the model understand the task (sentiment analysis), they are not strictly necessary since the model could ignore the examples and just read the instruction that indicates what the task is.
In symbol tuning, the model is fine-tuned on examples where the instructions are removed and natural language labels are replaced with semantically-unrelated labels (e.g., “Foo,” “Bar,” etc.). In this setup, the task is unclear without looking at the in-context examples. For example, on the right in the figure above, multiple in-context examples would be needed to figure out the task. Because symbol tuning teaches the model to reason over the in-context examples, symbol-tuned models should have better performance on tasks that require reasoning between in-context examples and their labels.
 |
| Datasets and task types used for symbol tuning. |
Symbol-tuning procedure
We selected 22 publicly-available natural language processing (NLP) datasets that we use for our symbol-tuning procedure. These tasks have been widely used in the past, and we only chose classification-type tasks since our method requires discrete labels. We then remap labels to a random label from a set of ~30K arbitrary labels selected from one of three categories: integers, character combinations, and words.
For our experiments, we symbol tune Flan-PaLM, the instruction-tuned variants of PaLM. We use three different sizes of Flan-PaLM models: Flan-PaLM-8B, Flan-PaLM-62B, and Flan-PaLM-540B. We also tested Flan-cont-PaLM-62B (Flan-PaLM-62B at 1.3T tokens instead of 780B tokens), which we abbreviate as 62B-c.
 |
| We use a set of ∼300K arbitrary symbols from three categories (integers, character combinations, and words). ∼30K symbols are used during tuning and the rest are held out for evaluation. |
Experimental setup
We want to evaluate a model’s ability to perform unseen tasks, so we cannot evaluate on tasks used in symbol tuning (22 datasets) or used during instruction tuning (1.8K tasks). Hence, we choose 11 NLP datasets that were not used during fine-tuning.
In-context learning
In the symbol-tuning procedure, models must learn to reason with in-context examples in order to successfully perform tasks because prompts are modified to ensure that tasks cannot simply be learned from relevant labels or instructions. Symbol-tuned models should perform better in settings where tasks are unclear and require reasoning between in-context examples and their labels. To explore these settings, we define four in-context learning settings that vary the amount of reasoning required between inputs and labels in order to learn the task (based on the availability of instructions/relevant labels)
 |
| Depending on the availability of instructions and relevant natural language labels, models may need to do varying amounts of reasoning with in-context examples. When these features are not available, models must reason with the given in-context examples to successfully perform the task. |
Symbol tuning improves performance across all settings for models 62B and larger, with small improvements in settings with relevant natural language labels (+0.8% to +4.2%) and substantial improvements in settings without relevant natural language labels (+5.5% to +15.5%). Strikingly, when relevant labels are unavailable, symbol-tuned Flan-PaLM-8B outperforms FlanPaLM-62B, and symbol-tuned Flan-PaLM-62B outperforms Flan-PaLM-540B. This performance difference suggests that symbol tuning can allow much smaller models to perform as well as large models on these tasks (effectively saving ∼10X inference compute).
 |
| Large-enough symbol-tuned models are better at in-context learning than baselines, especially in settings where relevant labels are not available. Performance is shown as average model accuracy (%) across eleven tasks. |
Algorithmic reasoning
We also experiment on algorithmic reasoning tasks from BIG-Bench. There are two main groups of tasks: 1) List functions — identify a transformation function (e.g., remove the last element in a list) between input and output lists containing non-negative integers; and 2) simple turing concepts — reason with binary strings to learn the concept that maps an input to an output (e.g., swapping 0s and 1s in a string).
On the list function and simple turing concept tasks, symbol tuning results in an average performance improvement of 18.2% and 15.3%, respectively. Additionally, Flan-cont-PaLM-62B with symbol tuning outperforms Flan-PaLM-540B on the list function tasks on average, which is equivalent to a ∼10x reduction in inference compute. These improvements suggest that symbol tuning strengthens the model’s ability to learn in-context for unseen task types, as symbol tuning did not include any algorithmic data.
 |
| Symbol-tuned models achieve higher performance on list function tasks and simple turing concept tasks. (A–E): categories of list functions tasks. (F): simple turing concepts task. |
Flipped labels
In the flipped-label experiment, labels of in-context and evaluation examples are flipped, meaning that prior knowledge and input-label mappings disagree (e.g., sentences containing positive sentiment labeled as “negative sentiment”), thereby allowing us to study whether models can override prior knowledge. Previous work has shown that while pre-trained models (without instruction tuning) can, to some extent, follow flipped labels presented in-context, instruction tuning degraded this ability.
We see that there is a similar trend across all model sizes — symbol-tuned models are much more capable of following flipped labels than instruction-tuned models. We found that after symbol tuning, Flan-PaLM-8B sees an average improvement across all datasets of 26.5%, Flan-PaLM-62B sees an improvement of 33.7%, and Flan-PaLM-540B sees an improvement of 34.0%. Additionally, symbol-tuned models achieve similar or better than average performance as pre-training–only models.
 |
| Symbol-tuned models are much better at following flipped labels presented in-context than instruction-tuned models are. |
Conclusion
We presented symbol tuning, a new method of tuning models on tasks where natural language labels are remapped to arbitrary symbols. Symbol tuning is based off of the intuition that when models cannot use instructions or relevant labels to determine a presented task, it must do so by instead learning from in-context examples. We tuned four language models using our symbol-tuning procedure, utilizing a tuning mixture of 22 datasets and approximately 30K arbitrary symbols as labels.
We first showed that symbol tuning improves performance on unseen in-context learning tasks, especially when prompts do not contain instructions or relevant labels. We also found that symbol-tuned models were much better at algorithmic reasoning tasks, despite the lack of numerical or algorithmic data in the symbol-tuning procedure. Finally, in an in-context learning setting where inputs have flipped labels, symbol tuning (for some datasets) restores the ability to follow flipped labels that was lost during instruction tuning.
Future work
Through symbol tuning, we aim to increase the degree to which models can examine and learn from input–label mappings during in-context learning. We hope that our results encourage further work towards improving language models’ ability to reason over symbols presented in-context.
Acknowledgements
The authors of this post are now part of Google DeepMind. This work was conducted by Jerry Wei, Le Hou, Andrew Lampinen, Xiangning Chen, Da Huang, Yi Tay, Xinyun Chen, Yifeng Lu, Denny Zhou, Tengyu Ma, and Quoc V. Le. We would like to thank our colleagues at Google Research and Google DeepMind for their advice and helpful discussions.
 Posted by Swathi Dharshna Subbaraj, Google Dev Library
Posted by Swathi Dharshna Subbaraj, Google Dev Library








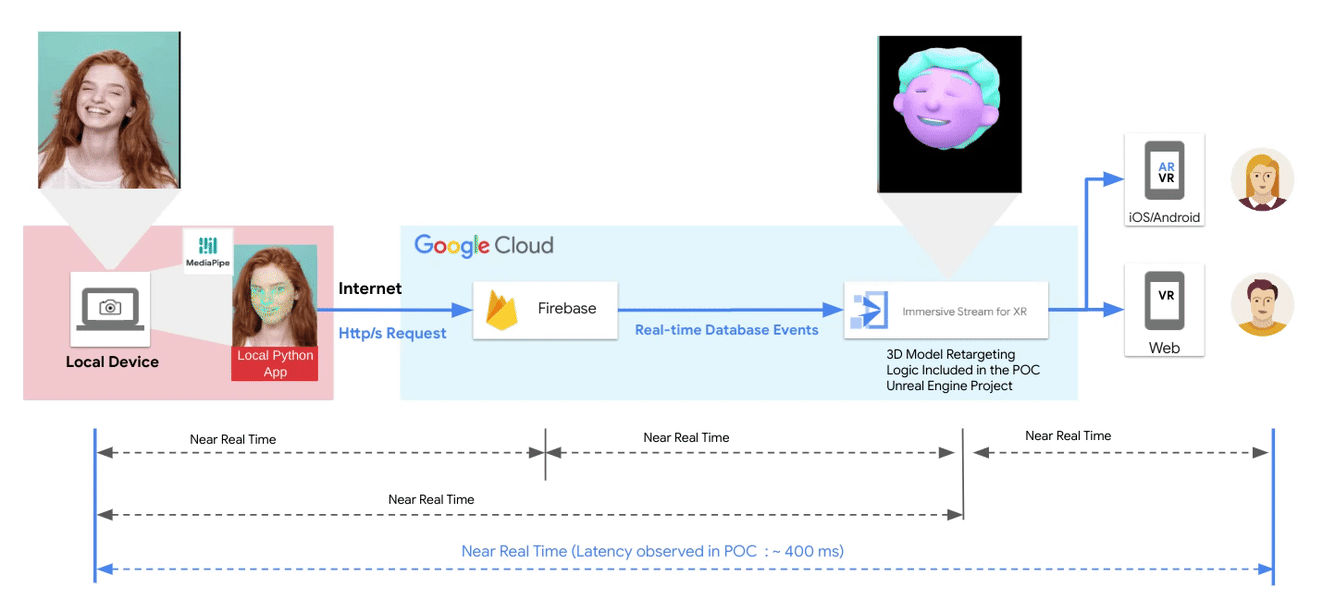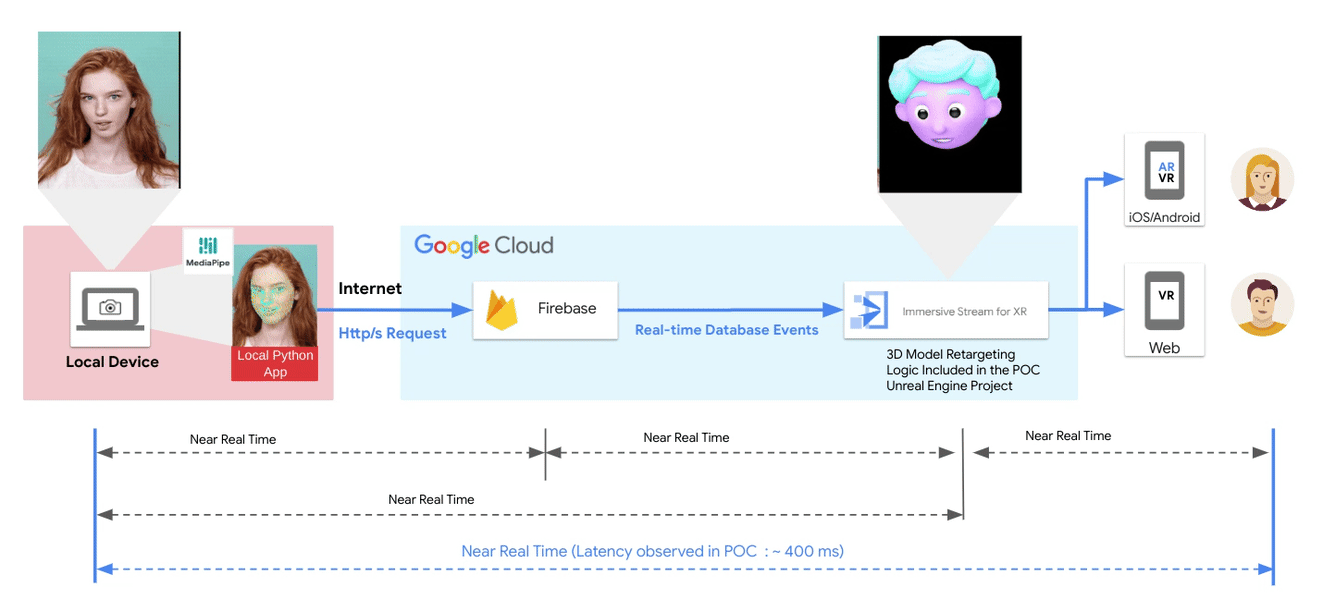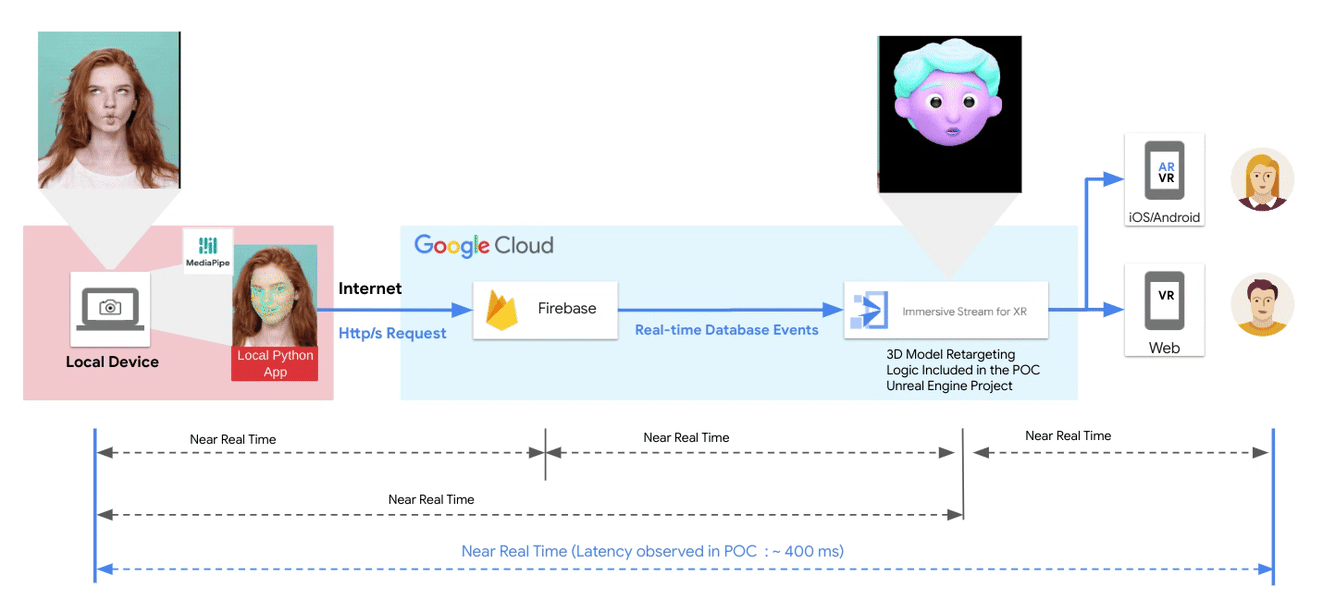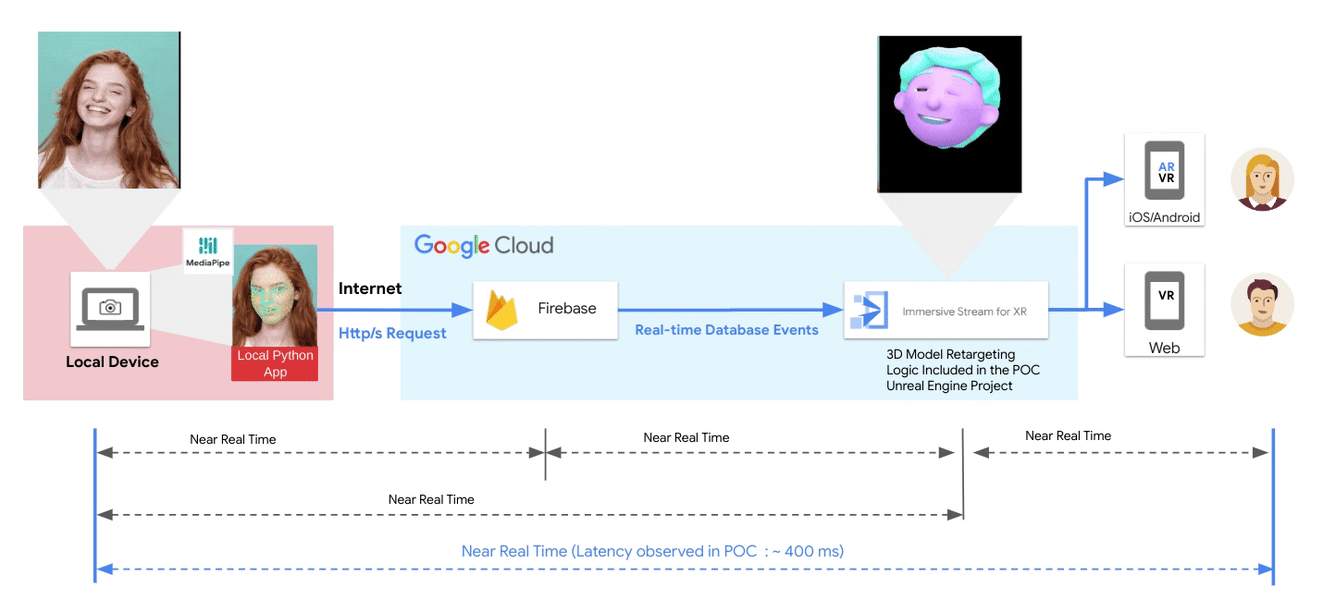
 A guest post by the XR Development team at
A guest post by the XR Development team at 
































{kind=link}