Time series forecasting is critical to various real-world applications, from demand forecasting to pandemic spread prediction. In multivariate time series forecasting (forecasting multiple variants at the same time), one can split existing methods into two categories: univariate models and multivariate models. Univariate models focus on inter-series interactions or temporal patterns that encompass trends and seasonal patterns on a time series with a single variable. Examples of such trends and seasonal patterns might be the way mortgage rates increase due to inflation, and how traffic peaks during rush hour. In addition to inter-series patterns, multivariate models process intra-series features, known as cross-variate information, which is especially useful when one series is an advanced indicator of another series. For example, a rise in body weight may cause an increase in blood pressure, and increasing the price of a product may lead to a decrease in sales. Multivariate models have recently become popular solutions for multivariate forecasting as practitioners believe their capability of handling cross-variate information may lead to better performance.
In recent years, deep learning Transformer-based architectures have become a popular choice for multivariate forecasting models due to their superior performance on sequence tasks. However, advanced multivariate models perform surprisingly worse than simple univariate linear models on commonly-used long-term forecasting benchmarks, such as Electricity Transformer Temperature (ETT), Electricity, Traffic, and Weather. These results raise two questions:
- Does cross-variate information benefit time series forecasting?
- When cross-variate information is not beneficial, can multivariate models still perform as well as univariate models?
In “TSMixer: An All-MLP Architecture for Time Series Forecasting”, we analyze the advantages of univariate linear models and reveal their effectiveness. Insights from this analysis lead us to develop Time-Series Mixer (TSMixer), an advanced multivariate model that leverages linear model characteristics and performs well on long-term forecasting benchmarks. To the best of our knowledge, TSMixer is the first multivariate model that performs as well as state-of-the-art univariate models on long-term forecasting benchmarks, where we show that cross-variate information is less beneficial. To demonstrate the importance of cross-variate information, we evaluate a more challenging real-world application, M5. Finally, empirical results show that TSMixer outperforms state-of-the-art models, such as PatchTST, Fedformer, Autoformer, DeepAR and TFT.
TSMixer architecture
A key difference between linear models and Transformers is how they capture temporal patterns. On one hand, linear models apply fixed and time-step-dependent weights to capture static temporal patterns, and are unable to process cross-variate information. On the other hand, Transformers use attention mechanisms that apply dynamic and data-dependent weights at each time step, capturing dynamic temporal patterns and enabling them to process cross-variate information.
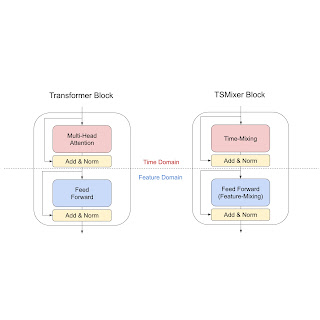
In our analysis, we show that under common assumptions of temporal patterns, linear models have naïve solutions to perfectly recover the time series or place bounds on the error, which means they are great solutions for learning static temporal patterns of univariate time series more effectively. In contrast, it is non-trivial to find similar solutions for attention mechanisms, as the weights applied to each time step are dynamic. Consequently, we develop a new architecture by replacing Transformer attention layers with linear layers. The resulting TSMixer model, which is similar to the computer vision MLP-Mixer method, alternates between applications of the multi-layer perceptron in different directions, which we call time-mixing and feature-mixing, respectively. The TSMixer architecture efficiently captures both temporal patterns and cross-variate information, as shown in the figure below. The residual designs ensure that TSMixer retains the capacity of temporal linear models while still being able to exploit cross-variate information.
 |
| Transformer block and TSMixer block architectures. TSMixer replaces the multi-head attention layer with time-mixing, a linear model applied on the time dimension. |
 |
| Comparison between data-dependent (attention mechanisms) and time-step-dependent (linear models). This is an example of forecasting the next time step by learning the weights of the previous three time steps. |
Evaluation on long-term forecasting benchmarks
We evaluate TSMixer using seven popular long-term forecasting datasets (ETTm1, ETTm2, ETTh1, ETTh2, Electricity, Traffic, and Weather), where recent research has shown that univariate linear models outperform advanced multivariate models with large margins. We compare TSMixer with state-of-the-art multivariate models (TFT, FEDformer, Autoformer, Informer), and univariate models, including linear models and PatchTST. The figure below shows the average improvement of mean squared error (MSE) by TSMixer compared with others. The average is calculated across datasets and multiple forecasting horizons. We demonstrate that TSMixer significantly outperforms other multivariate models and performs on par with state-of-the-art univariate models. These results show that multivariate models are capable of performing as well as univariate models.
 |
| The average MSE improvement of TSMixer compared with other baselines. The red bars show multivariate methods and the blue bars show univariate methods. TSMixer achieves significant improvement over other multivariate models and achieves comparable results to univariate models. |
Ablation study
We performed an ablation study to compare TSMixer with TMix-Only, a TSMixer variant that consists of time mixing layers only. The results show that TMix-Only performs almost the same as TSMixer, which means the additional feature mixing layers do not improve the performance and confirms that cross-variate information is less beneficial on popular benchmarks. The results validate the superior univariate model performance shown in previous research. However, existing long-term forecasting benchmarks are not well representative of the need for cross-variate information in some real-world applications where time series may be intermittent or sparse, hence temporal patterns may not be sufficient for forecasting. Therefore, it may be inappropriate to evaluate multivariate forecasting models solely on these benchmarks.
Evaluation on M5: Effectiveness of cross-variate information
To further demonstrate the benefit of multivariate models, we evaluate TSMixer on the challenging M5 benchmark, a large-scale retail dataset containing crucial cross-variate interactions. M5 contains the information of 30,490 products collected over 5 years. Each product description includes time series data, like daily sales, sell price, promotional event information, and static (non-time-series) features, such as store location and product category. The goal is to forecast the daily sales of each product for the next 28 days, evaluated using the weighted root mean square scaled error (WRMSSE) from the M5 competition. The complicated nature of retail makes it more challenging to forecast solely using univariate models that focus on temporal patterns, so multivariate models with cross-variate information and even auxiliary features are more essential.
First, we compare TSMixer to other methods only considering the historical data, such as daily sales and historical sell prices. The results show that multivariate models outperforms univariate models significantly, indicating the usefulness of cross-variate information. And among all compared methods, TSMixer effectively leverages the cross-variate information and achieves the best performance.
Additionally, to leverage more information, such as static features (e.g., store location, product category) and future time series (e.g., a promotional event scheduled in coming days) provided in M5, we propose a principle design to extend TSMixer. The extended TSMixer aligns different types of features into the same length, and then applies multiple mixing layers to the concatenated features to make predictions. The extended TSMixer architecture outperforms models popular in industrial applications, including DeepAR and TFT, showcasing its strong potential for real-world impact.
 |
| The architecture of the extended TSMixer. In the first stage (align stage), it aligns the different types of features into the same length before concatenating them. In the second stage (mixing stage) it applies multiple mixing layers conditioned with static features. |
 |
| The WRMSSE on M5. The first three methods (blue) are univariate models. The middle three methods (orange) are multivariate models that consider only historical features. The last three methods (red) are multivariate models that consider historical, future, and static features. |
Conclusion
We present TSMixer, an advanced multivariate model that leverages linear model characteristics and performs as well as state-of-the-art univariate models on long-term forecasting benchmarks. TSMixer creates new possibilities for the development of time series forecasting architectures by providing insights into the importance of cross-variate and auxiliary information in real-world scenarios. The empirical results highlight the need to consider more realistic benchmarks for multivariate forecasting models in future research. We hope that this work will inspire further exploration in the field of time series forecasting, and lead to the development of more powerful and effective models that can be applied to real-world applications.
Acknowledgements
This research was conducted by Si-An Chen, Chun-Liang Li, Nate Yoder, Sercan O. Arik, and Tomas Pfister.















 Posted by
Posted by 

 Posted by Nari Yoon, Bitnoori Keum, Hee Jung, DevRel Community Manager / Soonson Kwon, DevRel Program Manager
Posted by Nari Yoon, Bitnoori Keum, Hee Jung, DevRel Community Manager / Soonson Kwon, DevRel Program Manager