In June of last year, we published a story about a visualization techniques that helped to understand how neural networks carried out difficult visual classification tasks. In addition to helping us gain a deeper understanding of how NNs worked, these techniques also produced strange, wonderful and oddly compelling images.
Soon after, the paper A Neural Algorithm of Artistic Style by Leon Gatys in Tuebingen was released. Their technique used a convolutional neural network to factor images into their separate style and content components. This in turn allowed the creation, by using a neural network as a generic image parser, of new images that combined the style of one with the content of another. Once again it took the creative coding community by storm and immediately many artists and coders began experimenting with the new algorithm, resulting in Twitter bots and other explorations and experiments.
The open-source deep-learning community, especially projects such as GitXiv, hugely contributed to the spread, accessibility and development of these algorithms. Both DeepDream and style transfer were rapidly implemented in a plethora of different languages and deep learning packages. Immediately others took the techniques and developed them further.
“Saxophone dreams” - Mike Tyka.
With machine learning as field moving forward at a breakneck pace and rapidly becoming part of many -- if not most -- online products, the opportunities for artistic uses are as wide as they are unexplored and perhaps overlooked. However the interest is growing rapidly: the University of London is now offering a course on Machine learning and art. NYU ITP offers a similar program this year. The Tate Modern’s IK Prize 2016 topic: Artificial Intelligence.
These are exciting early days, and we want to continue to stimulate artistic interest in these emerging technologies. To that end, we are announcing a two day DeepDream event in San Francisco at the Gray Area Foundation for the Arts, aimed at showcasing some of the latest exploration of the intersection of Machine Intelligence and Art, and spurring discussion focused around future directions:
Friday Feb 26th:DeepDream: The Art of Neural Networks, an exhibit consisting of 29 neural network generated artworks, created by artists at Google and from around the world. The works will be auctioned, with all proceeds going to the Gray Area Foundation, which has been active in supporting the intersection between arts and technology for over 10 years.
On Saturday Feb 27th: Art and Machine Learning Symposium, an open one-day symposium on Machine Learning and Art, aiming to bring together the neural network and the creative coding communities to exchange ideas, learn and discuss. Videos of all the talks will be posted online after the event.
We look forward to sharing some of the interesting works of art generated by the art and machine learning community, and being part of the discussion of how art and technology can be combined.
Posted by David Silver and Demis Hassabis, Google DeepMind
Games are a great testing ground for developing smarter, more flexible algorithms that have the ability to tackle problems in ways similar to humans. Creating programs that are able to play games better than the best humans has a long history - the first classic game mastered by a computer was noughts and crosses (also known as tic-tac-toe) in 1952 as a PhD candidate’s project. Then fell checkers in 1994. Chess was tackled by Deep Blue in 1997. The success isn’t limited to board games, either - IBM's Watson won first place on Jeopardy in 2011, and in 2014 our own algorithms learned to play dozens of Atari games just from the raw pixel inputs.
But one game has thwarted A.I. research thus far: the ancient game of Go. Invented in China over 2500 years ago, Go is played by more than 40 million people worldwide. The rules are simple: players take turns to place black or white stones on a board, trying to capture the opponent's stones or surround empty space to make points of territory. Confucius wrote about the game, and its aesthetic beauty elevated it to one of the four essential arts required of any true Chinese scholar. The game is played primarily through intuition and feel, and because of its subtlety and intellectual depth it has captured the human imagination for centuries.
But as simple as the rules are, Go is a game of profound complexity. The search space in Go is vast -- more than a googol times larger than chess (a number greater than there are atoms in the universe!). As a result, traditional “brute force” AI methods -- which construct a search tree over all possible sequences of moves -- don’t have a chance in Go. To date, computers have played Go only as well as amateurs. Experts predicted it would be at least another 10 years until a computer could beat one of the world’s elite group of Go professionals.
We saw this as an irresistible challenge! We started building a system, AlphaGo, described in a paper in Nature this week, that would overcome these barriers. The key to AlphaGo is reducing the enormous search space to something more manageable. To do this, it combines a state-of-the-art tree search with two deep neural networks, each of which contains many layers with millions of neuron-like connections. One neural network, the “policy network”, predicts the next move, and is used to narrow the search to consider only the moves most likely to lead to a win. The other neural network, the “value network”, is then used to reduce the depth of the search tree -- estimating the winner in each position in place of searching all the way to the end of the game.
AlphaGo’s search algorithm is much more human-like than previous approaches. For example, when Deep Blue played chess, it searched by brute force over thousands of times more positions than AlphaGo. Instead, AlphaGo looks ahead by playing out the remainder of the game in its imagination, many times over - a technique known as Monte-Carlo tree search. But unlike previous Monte-Carlo programs, AlphaGo uses deep neural networks to guide its search. During each simulated game, the policy network suggests intelligent moves to play, while the value network astutely evaluates the position that is reached. Finally, AlphaGo chooses the move that is most successful in simulation.
We first trained the policy network on 30 million moves from games played by human experts, until it could predict the human move 57% of the time (the previous record before AlphaGo was 44%). But our goal is to beat the best human players, not just mimic them. To do this, AlphaGo learned to discover new strategies for itself, by playing thousands of games between its neural networks, and gradually improving them using a trial-and-error process known as reinforcement learning. This approach led to much better policy networks, so strong in fact that the raw neural network (immediately, without any tree search at all) can defeat state-of-the-art Go programs that build enormous search trees.
These policy networks were in turn used to train the value networks, again by reinforcement learning from games of self-play. These value networks can evaluate any Go position and estimate the eventual winner - a problem so hard it was believed to be impossible.
Of course, all of this requires a huge amount of compute power, so we made extensive use of Google Cloud Platform, which enables researchers working on AI and Machine Learning to access elastic compute, storage and networking capacity on demand. In addition, new open source libraries for numerical computation using data flow graphs, such as TensorFlow, allow researchers to efficiently deploy the computation needed for deep learning algorithms across multiple CPUs or GPUs.
So how strong is AlphaGo? To answer this question, we played a tournament between AlphaGo and the best of the rest - the top Go programs at the forefront of A.I. research. Using a single machine, AlphaGo won all but one of its 500 games against these programs. In fact, AlphaGo even beat those programs after giving them 4 free moves headstart at the beginning of each game. A high-performance version of AlphaGo, distributed across many machines, was even stronger.
This figure from the Nature article shows the Elo rating and approximate rank of AlphaGo (both single machine and distributed versions), the European champion Fan Hui (a professional 2-dan), and the strongest other Go programs, evaluated over thousands of games. Pale pink bars show the performance of other programs when given a four move headstart.
It seemed that AlphaGo was ready for a greater challenge. So we invited the reigning 3-time European Go champion Fan Hui — an elite professional player who has devoted his life to Go since the age of 12 — to our London office for a challenge match. The match was played behind closed doors between October 5-9 last year. AlphaGo won by 5 games to 0 -- the first time a computer program has ever beaten a professional Go player. AlphaGo’s next challenge will be to play the top Go player in the world over the last decade, Lee Sedol. The match will take place this March in Seoul, South Korea. Lee Sedol is excited to take on the challenge saying, "I am privileged to be the one to play, but I am confident that I can win." It should prove to be a fascinating contest!
We are thrilled to have mastered Go and thus achieved one of the grand challenges of AI. However, the most significant aspect of all this for us is that AlphaGo isn’t just an ‘expert’ system built with hand-crafted rules, but instead uses general machine learning techniques to allow it to improve itself, just by watching and playing games. While games are the perfect platform for developing and testing AI algorithms quickly and efficiently, ultimately we want to apply these techniques to important real-world problems. Because the methods we have used are general purpose, our hope is that one day they could be extended to help us address some of society’s toughest and most pressing problems, from climate modelling to complex disease analysis.
This week, Montreal hosts the 29th Annual Conference on Neural Information Processing Systems (NIPS 2015), a machine learning and computational neuroscience conference that includes invited talks, demonstrations and oral and poster presentations of some of the latest in machine learning research. Google will have a strong presence at NIPS 2015, with over 140 Googlers attending in order to contribute to and learn from the broader academic research community by presenting technical talks and posters, in addition to hosting workshops and tutorials.
Research at Google is at the forefront of innovation in Machine Intelligence, actively exploring virtually all aspects of machine learning including classical algorithms as well as cutting-edge techniques such as deep learning. Focusing on both theory as well as application, much of our work on language understanding, speech, translation, visual processing, ranking, and prediction relies on Machine Intelligence. In all of those tasks and many others, we gather large volumes of direct or indirect evidence of relationships of interest, and develop learning approaches to understand and generalize.
If you are attending NIPS 2015, we hope you’ll stop by our booth and chat with our researchers about the projects and opportunities at Google that go into solving interesting problems for billions of people. You can also learn more about our research being presented at NIPS 2015 in the list below (Googlers highlighted in blue).
Google is a Platinum Sponsor of NIPS 2015.
PROGRAM ORGANIZERS General Chairs Corinna Cortes, Neil D. Lawrence Program Committee includes: Samy Bengio, Gal Chechik, Ian Goodfellow, Shakir Mohamed, Ilya Sutskever
Deep Knowledge Tracing Chris Piech, Jonathan Bassen, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas Guibas, Jascha Sohl-Dickstein
Hidden Technical Debt in Machine Learning Systems D Sculley,Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, Dan Dennison
Deep Learning Symposium Program Committee Members include: Samy Bengio, Phil Blunsom, Nando De Freitas, Ilya Sutskever, Andrew Zisserman Invited Speakers include: Max Jaderberg, Sergey Ioffe, Alexander Graves
Posted by Greg Corrado*, Senior Research Scientist
Machine Intelligence for You
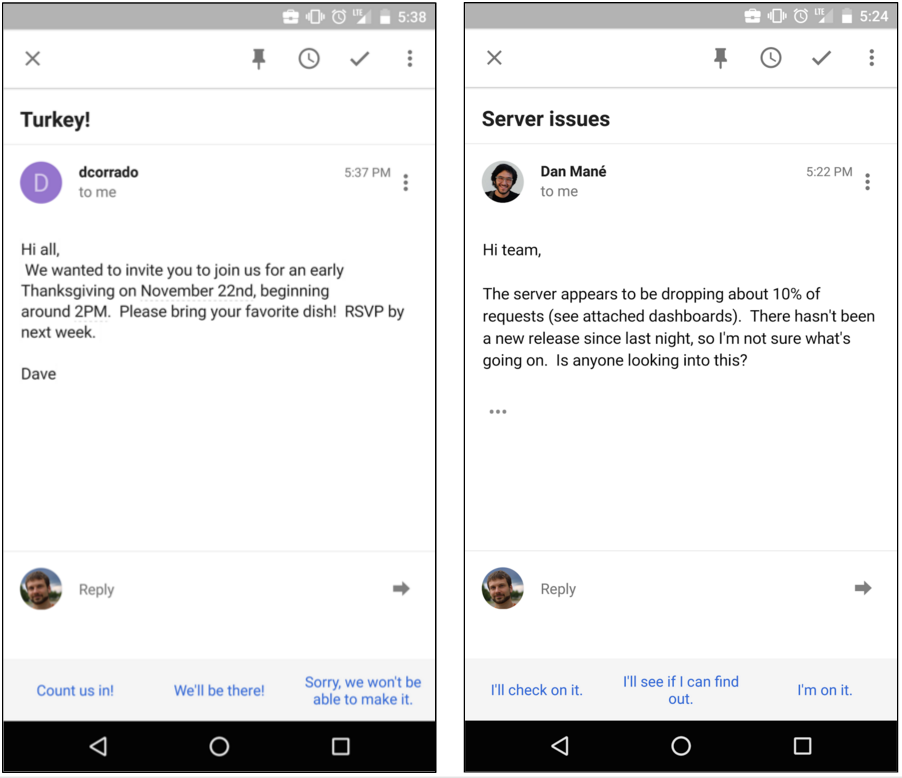
What I love about working at Google is the opportunity to harness cutting-edge machine intelligence for users’ benefit. Two recent Research Blog posts talked about how we’ve used machine learning in the form of deep neural networks to improve voice search and YouTube thumbnails. Today we can share something even wilder -- Smart Reply, a deep neural network that writes email.
I get a lot of email, and I often peek at it on the go with my phone. But replying to email on mobile is a real pain, even for short replies. What if there were a system that could automatically determine if an email was answerable with a short reply, and compose a few suitable responses that I could edit or send with just a tap?
Some months ago, Bálint Miklós from the Gmail team asked me if such a thing might be possible. I said it sounded too much like passing the Turing Test to get our hopes up... but having collaborated before on machine learning improvements to spam detection and email categorization, we thought we’d give it a try.
There’s a long history of research on both understanding and generating natural language for applications like machine translation. Last year, Google researchers Oriol Vinyals, Ilya Sutskever, and Quoc Le proposed fusing these two tasks in what they called sequence-to-sequence learning. This end-to-end approach has many possible applications, but one of the most unexpected that we’ve experimented with is conversational synthesis. Early results showed that we could use sequence-to-sequence learning to power a chatbot that was remarkably fun to play with, despite having included no explicit knowledge of language in the program.
Obviously, there’s a huge gap between a cute research chatbot and a system that I want helping me draft email. It was still an open question if we could build something that was actually useful to our users. But one engineer on our team, Anjuli Kannan, was willing to take on the challenge. Working closely with both Machine Intelligence researchers and Gmail engineers, she elaborated and experimented with the sequence-to-sequence research ideas. The result is the industrial strength neural network that runs at the core of the Smart Reply feature we’re launching this week.
How it works
A naive attempt to build a response generation system might depend on hand-crafted rules for common reply scenarios. But in practice, any engineer’s ability to invent “rules” would be quickly outstripped by the tremendous diversity with which real people communicate. A machine-learned system, by contrast, implicitly captures diverse situations, writing styles, and tones. These systems generalize better, and handle completely new inputs more gracefully than brittle, rule-based systems ever could.
Diagram by Chris Olah
Like other sequence-to-sequence models, the Smart Reply System is built on a pair of recurrent neural networks, one used to encode the incoming email and one to predict possible responses. The encoding network consumes the words of the incoming email one at a time, and produces a vector (a list of numbers). This vector, which Geoff Hinton calls a “thought vector,” captures the gist of what is being said without getting hung up on diction -- for example, the vector for "Are you free tomorrow?" should be similar to the vector for "Does tomorrow work for you?" The second network starts from this thought vector and synthesizes a grammatically correct reply one word at a time, like it’s typing it out. Amazingly, the detailed operation of each network is entirely learned, just by training the model to predict likely responses.
One challenge of working with emails is that the inputs and outputs of the model can be hundreds of words long. This is where the particular choice of recurrent neural network type really matters. We used a variant of a "long short-term-memory" network (or LSTM for short), which is particularly good at preserving long-term dependencies, and can home in on the part of the incoming email that is most useful in predicting a response, without being distracted by less relevant sentences before and after.
Of course, there's another very important factor in working with email, which is privacy. In developing Smart Reply we adhered to the same rigorous user privacy standards we’ve always held -- in other words, no humans reading your email. This means researchers have to get machine learning to work on a data set that they themselves cannot read, which is a little like trying to solve a puzzle while blindfolded -- but a challenge makes it more interesting!
Getting it right
Our first prototype of the system had a few unexpected quirks. We wanted to generate a few candidate replies, but when we asked our neural network for the three most likely responses, it’d cough up triplets like “How about tomorrow?” “Wanna get together tomorrow?” “I suggest we meet tomorrow.” That’s not really much of a choice for users. The solution was provided by Sujith Ravi, whose team developed a great machine learning system for mapping natural language responses to semantic intents. This was instrumental in several phases of the project, and was critical to solving the "response diversity problem": by knowing how semantically similar two responses are, we can suggest responses that are different not only in wording, but in their underlying meaning.
Another bizarre feature of our early prototype was its propensity to respond with “I love you” to seemingly anything. As adorable as this sounds, it wasn’t really what we were hoping for. Some analysis revealed that the system was doing exactly what we’d trained it to do, generate likely responses -- and it turns out that responses like “Thanks", "Sounds good", and “I love you” are super common -- so the system would lean on them as a safe bet if it was unsure. Normalizing the likelihood of a candidate reply by some measure of that response's prior probability forced the model to predict responses that were not just highly likely, but also had high affinity to the original message. This made for a less lovey, but far more useful, email assistant.
Give it a try
We’re actually pretty amazed at how well this works. We’ll be rolling this feature out on Inbox for Android and iOS later this week, and we hope you’ll try it for yourself! Tap on a Smart Reply suggestion to start editing it. If it’s perfect as is, just tap send. Two-tap email on the go -- just like Bálint envisioned.
* This blog post may or may not have actually been written by a neural network.↩
Making the video was eye-opening and brain-opening. It introduced us to concepts we’d never heard of – like machine learning and artificial neural networks – and ever since, we’ve been kind of fascinated by them. Machine learning, in particular, is a very active area of Computer Science research, with far-ranging applications beyond voice search – like machine translation, image recognition and description, and Google Voice transcription.
So... still curious to know more (and having just started this project) we found Google researchers Greg Corrado and Christopher Olah and ambushed them with our machine learning questions. This video is our attempt to distill what we learned from talking with them, but if anything in it piques your curiosity, or you have other questions, you’re in luck! On Friday, September 25, at 1 PM PDT / 4 PM EST Greg and Chris will be doing an Ask Me Anything on Reddit (see the calendar here) to answer your deep learning questions.
Everyone who’s curious is welcome to join, ask questions, and hopefully gain a better understanding of the world of machine learning and deep neural networks. (And we’ll be hanging out with them, too...in case you have any questions about video making or dogs.) We hope to see you this Friday!






_(cropped_to_Tyson_collar).jpg){kind=link}
{kind=link}