
Posted by Wesley Chun (@wescpy), Developer Advocate, Google Cloud
Introduction and background
The previous Module 12 episode of the Serverless Migration Station video series demonstrated how to add App Engine Memcache usage to an existing app that has transitioned from the webapp2 framework to Flask. Today's Module 13 episode continues its modernization by demonstrating how to migrate that app from Memcache to Cloud Memorystore. Moving from legacy APIs to standalone Cloud services makes apps more portable and provides an easier transition from Python 2 to 3. It also makes it possible to shift to other Cloud compute platforms should that be desired or advantageous. Developers benefit from upgrading to modern language releases and gain added flexibility in application-hosting options.
While App Engine Memcache provides a basic, low-overhead, serverless caching service, Cloud Memorystore "takes it to the next level" as a standalone product. Rather than a proprietary caching engine, Cloud Memorystore gives users the option to select from a pair of open source engines, Memcached or Redis, each of which provides additional features unavailable from App Engine Memcache. Cloud Memorystore is typically more cost efficient at-scale, offers high availability, provides automatic backups, etc. On top of this, one Memorystore instance can be used across many applications as well as incorporates improvements to memory handling, configuration tuning, etc., gained from experience managing a huge fleet of Redis and Memcached instances.
While Memcached is more similar to Memcache in usage/features, Redis has a much richer set of data structures that enable powerful application functionality if utilized. Redis has also been recognized as the most loved database by developers in StackOverflow's annual developers survey, and it's a great skill to pick up. For these reasons, we chose Redis as the caching engine for our sample app. However, if your apps' usage of App Engine Memcache is deeper or more complex, a migration to Cloud Memorystore for Memcached may be a better option as a closer analog to Memcache.
Performing the migration
The sample application registers individual web page "visits," storing visitor information such as IP address and user agent. In the original app, the most recent visits are cached into Memcache for an hour and used for display if the same user continuously refreshes their browser during this period; caching is a one way to counter this abuse. New visitors or cache expiration results new visits as well as updating the cache with the most recent visits. Such functionality must be preserved when migrating to Cloud Memorystore for Redis.
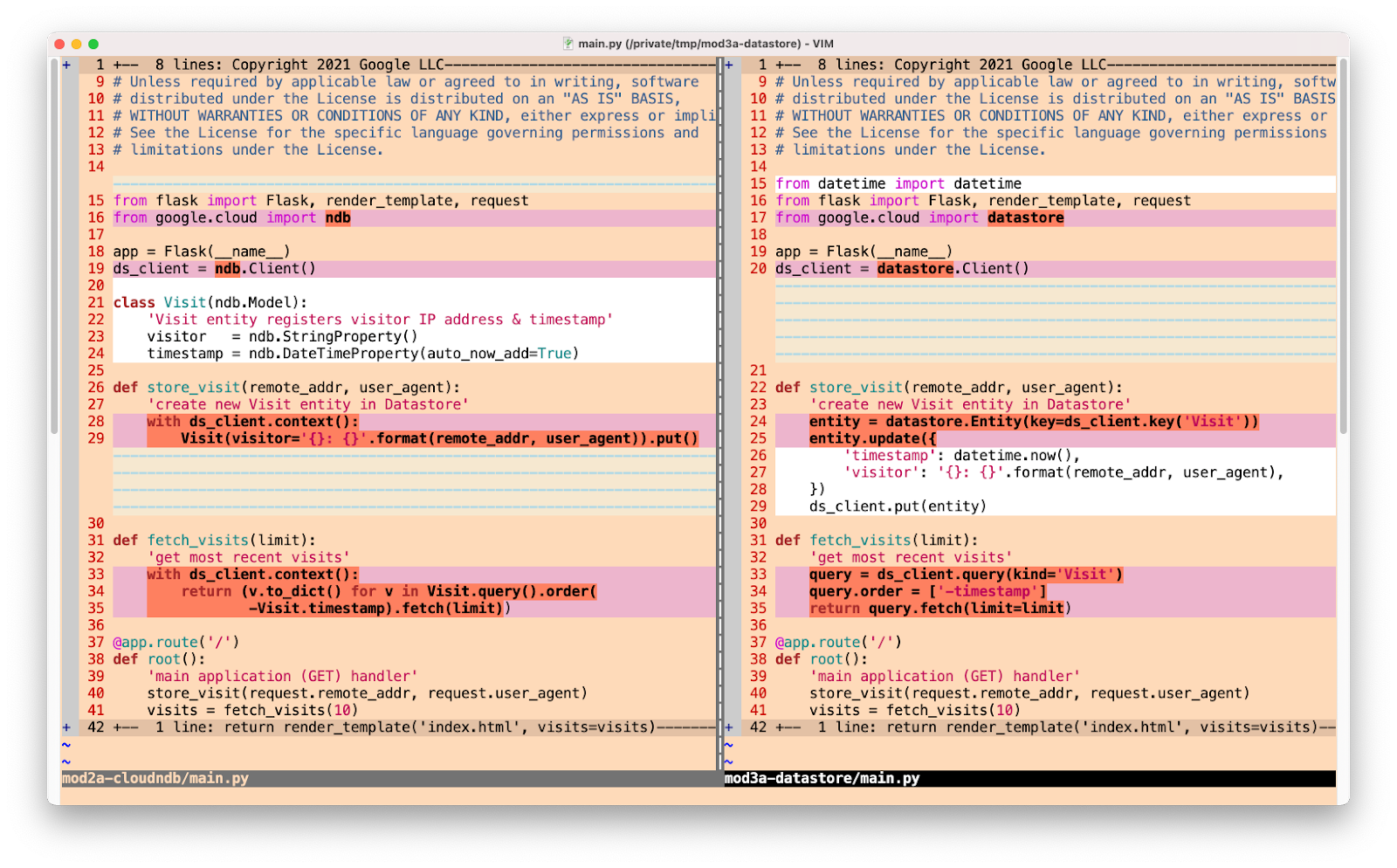
Below is pseudocode representing the core part of the app that saves new visits and queries for the most recent visits. Before, you can see how the most recent visits are cached into Memcache. After completing the migration, the underlying caching infrastructure has been swapped out in favor of Memorystore (via language-specific Redis client libraries). In this migration, we chose Redis version 5.0, and we recommend the latest versions, 5.0 and 6.x at the time of this writing, as the newest releases feature additional performance benefits, fixes to improve availability, and so on. In the code snippets below, notice how the calls between both caching systems are nearly identical. The bolded lines represent the migration-affected code managing the cached data.
 Switching from App Engine Memcache to Cloud Memorystore for Redis
Switching from App Engine Memcache to Cloud Memorystore for RedisWrap-up
The migration covered begins with the Module 12 sample app ("START"). Migrating the caching system to Cloud Memorystore and other requisite updates results in the Module 13 sample app ("FINISH") along with an optional port to Python 3. To practice this migration on your own to help prepare for your own migrations, follow the codelab to do it by-hand while following along in the video.
While the code migration demonstrated seems straightforward, the most critical change is that Cloud Memorystore requires dedicated server instances. For this reason, a Serverless VPC connector is also needed to connect your App Engine app to those Memorystore instances, requiring more dedicated servers. Furthermore, neither Cloud Memorystore nor Cloud VPC are free services, and neither has an "Always free" tier quota. Before moving forward this migration, check the pricing documentation for Cloud Memorystore for Redis and Serverless VPC access to determine cost considerations before making a commitment.
One key development that may affect your decision: In Fall 2021, the App Engine team extended support of many of the legacy bundled services like Memcache to next-generation runtimes, meaning you are no longer required to migrate to Cloud Memorystore when porting your app to Python 3. You can continue using Memcache even when upgrading to 3.x so long as you retrofit your code to access bundled services from next-generation runtimes.
A move to Cloud Memorystore and today's migration techniques will be here if and when you decide this is the direction you want to take for your App Engine apps. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, we plan to cover other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.