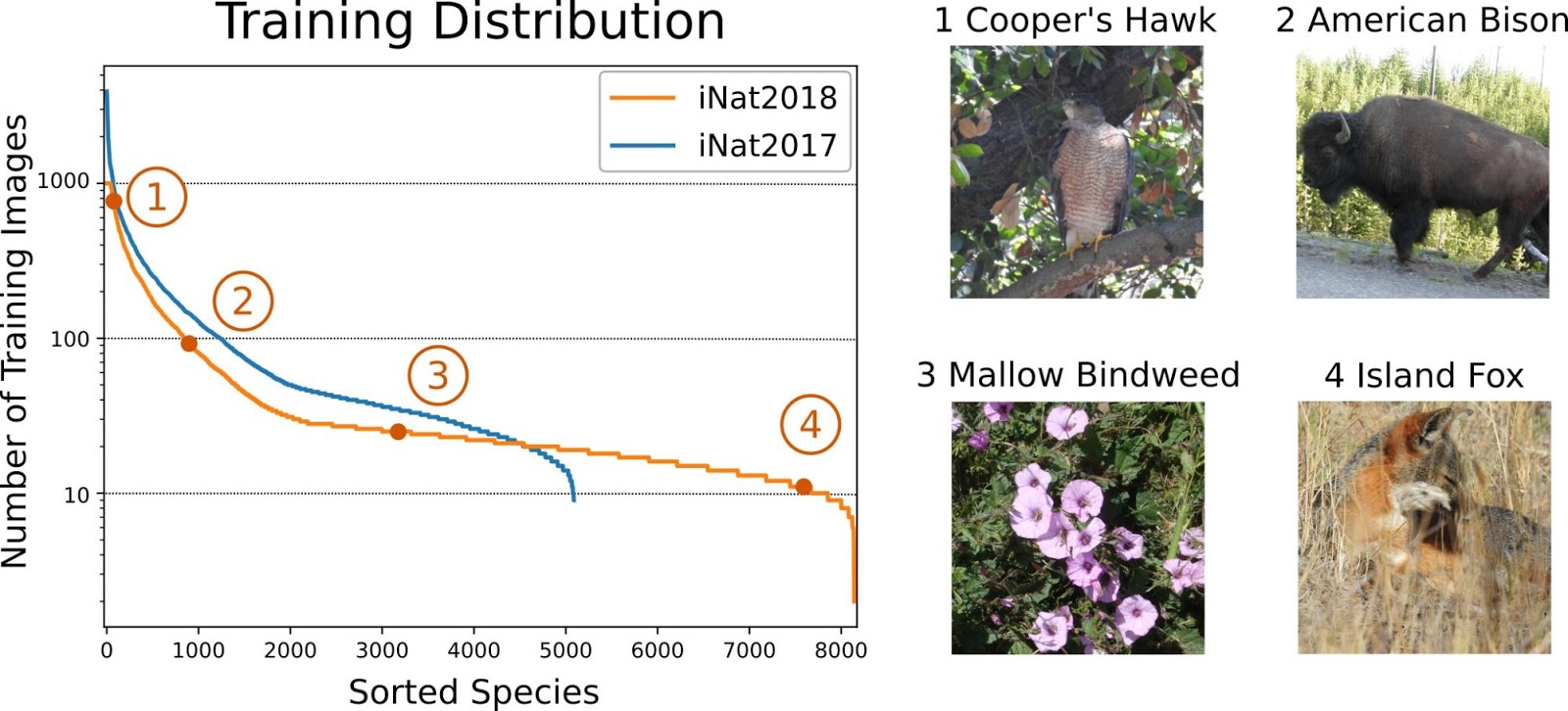
In recent years, fine-grained visual recognition competitions (FGVCs), such as the iNaturalist species classification challenge and the iMaterialist product attribute recognition challenge, have spurred progress in the development of image classification models focused on detection of fine-grained visual details in both natural and man-made objects. Whereas traditional image classification competitions focus on distinguishing generic categories (e.g., car vs. butterfly), the FGVCs go beyond entry level categories to focus on subtle differences in object parts and attributes. For example, rather than pursuing methods that can distinguish categories, such as “bird”, we are interested in identifying subcategories such as “indigo bunting” or “lazuli bunting.”
Previous challenges attracted a large number of talented participants who developed innovative new models for image recognition, with more than 500 teams competing at FGVC5 at CVPR 2018. FGVC challenges have also inspired new methods such as domain-specific transfer learning and estimating test-time priors, which have helped fine-grained recognition tasks reach state-of-the-art performance on several benchmarking datasets.
In order to further spur progress in FGVC research, we are proud to sponsor and co-organize the 6th annual workshop on Fine-Grained Visual Categorization (FGVC6), to be held on June 17th in Long Beach, CA at CVPR 2019. This workshop brings together experts in computer vision with specialists focusing on biodiversity, botany, fashion, and the arts, to address the challenges of applying fine-grained visual categorization to real-life settings.
This Year’s Challenges
This year there will be a wide variety of competition topics, each highlighting unique challenges of fine-grained visual categorization, including an updated iNaturalist challenge, fashion & products, wildlife camera traps, food, butterflies & moths, fashion design, and cassava leaf disease. We are also delighted to introduce two new partnerships with world class institutions—The Metropolitan Museum of Art for the iMet Collection challenge and the New York Botanical Garden for the Herbarium challenge.
 |
| The FGVC workshop at CVPR focuses on subordinate categories, including (from left to right, top to bottom) animal species from wildlife camera traps, retail products, fashion attributes, cassava leaf disease, Melastomataceae species from herbarium sheets, animal species from citizen science photos, butterfly and moth species, cuisine of dishes, and fine-grained attributes for museum art objects. |
 |
| A diverse sample of images included in the iMet Collection challenge dataset. Images were taken from the Metropolitan Museum of Art’s public domain dataset. |
In the Herbarium challenge, researchers are invited to tackle the problem of classifying species from the flowering plant family Melastomataceae. This challenge is distinguished from the iNaturalist competition, since the included images depict dried specimens preserved on herbarium sheets, exclusively. Herbarium sheets are essential to plant science, as they not only preserve the key details of the plants for identification and DNA analysis, but also provide a rare perspective into plant ecology in a historical context. As the world’s second largest herbarium, NYBG’s Steere Herbarium collection contributed a dataset of over 46,000 specimens for this year’s challenge.
 |
| In the Herbarium challenge, participants will identify species from the flowering plant family Melastomataceae. The New York Botanical Garden (NYBG) provided a dataset of over 46,000 herbarium specimens including over 680 species. Images used with permission of the NYBG. |
Invitation to Participate
We invite teams to participate in these competitions to help advance the state-of-the-art in fine-grained image recognition. Deadlines for entry into the competitions range from May 26 to June 3, depending on the challenge. The results of these competitions will be presented at the FGVC6 workshop at CVPR 2019, and will provide broad exposure to the top performing teams. We are excited to encourage the community's development of more accurate and broadly impactful algorithms in the field of fine-grained visual categorization!
Acknowledgements
We’d like to thank our colleagues and friends on the FGVC6 organizing committee for working together to advance this important area. At Google we would like to thank Hartwig Adam, Chenyang Zhang, Yulong Liu, Kiat Chuan Tan, Mikhail Sirotenko, Denis Brulé, Cédric Deltheil, Timnit Gebru, Ernest Mwebaze, Weijun Wang, Grace Chu, Jack Sim, Andrew Howard, R.V. Guha, Srikanth Belwadi, Tanya Birch, Katherine Chou, Maggie Demkin, Elizabeth Park, and Will Cukierski.