Posted by André Araujo and Tobias Weyand, Software Engineers, Google Research
Image classification technology has shown remarkable improvement over the past few years, exemplified in part by the Imagenet classification challenge, where error rates continue to drop substantially every year. In order to continue advancing the state of the art in computer vision, many researchers are now putting more focus on fine-grained and instance-level recognition problems – instead of recognizing general entities such as buildings, mountains and (of course) cats, many are designing machine learning algorithms capable of identifying the Eiffel Tower, Mount Fuji or Persian cats. However, a significant obstacle for research in this area has been the lack of large annotated datasets.
Today, we are excited to advance instance-level recognition by releasing Google-Landmarks, the largest worldwide dataset for recognition of human-made and natural landmarks. Google-Landmarks is being released as part of the Landmark Recognition and Landmark Retrieval Kaggle challenges, which will be the focus of the CVPR’18 Landmarks workshop. The dataset contains more than 2 million images depicting 30 thousand unique landmarks from across the world (their geographic distribution is presented below), a number of classes that is ~30x larger than what is available in commonly used datasets. Additionally, to spur research in this field, we are open-sourcing Deep Local Features (DELF), an attentive local feature descriptor that we believe is especially suited for this kind of task.
Geographic distribution of landmarks in our dataset.
Landmark recognition presents some noteworthy differences from other problems. For example, even within a large annotated dataset, there might not be much training data available for some of the less popular landmarks. Additionally, since landmarks are generally rigid objects which do not move, the intra-class variation is very small (in other words, a landmark’s appearance does not change that much across different images of it). As a result, variations only arise due to image capture conditions, such as occlusions, different viewpoints, weather and illumination, making this distinct from other image recognition datasets where images of a particular class (such as a dog) can vary much more. These characteristics are also shared with other instance-level recognition problems, such as artwork recognition — so we hope the new dataset can benefit research for other image recognition problems as well.
The two Kaggle challenges provide access to annotated data to help researchers address these problems. The recognition track challenge is to build models that recognize the correct landmark in a dataset of challenging test images, while the retrieval track challenges participants to retrieve images containing the same landmark.
If you plan to be at CVPR this year, we hope you’ll attend the CVPR’18 Landmarks workshop. However, everyone is able to participate in the challenge, and access to the new dataset is available via the Kaggle website. We hope this resource is valuable to your research and we can’t wait to see the ideas you will come up with for recognizing landmarks!
Acknowledgments Jack Sim, Will Cukierski, Maggie Demkin, Hartwig Adam, Bohyung Han, Shih-Fu Chang, Ondrej Chum, Torsten Sattler, Giorgos Tolias, Xu Zhang, Fernando Brucher, Marco Andreetto, Gursheesh Kour.
Posted by Jianing Wei and Tyler Mullen, Software Engineers, Google Research
Last summer, we launched Motion Stills on Android, which delivered a great video capture and viewing experience on a wide range of Android phones. Then, we refined our Motion Stills technology further to enable the new motion photos feature in Pixel 2.
Today, we are excited to announce the new Augmented Reality (AR) mode in Motion Stills for Android. With the new AR mode, a user simply touches the viewfinder to place fun, virtual 3D objects on static or moving horizontal surfaces (e.g. tables, floors, or hands), allowing them to seamlessly interact with a dynamic real-world environment. You can also record and share the clips as GIFs and videos.
Motion Stills with instant motion tracking in action
AR mode is powered by instant motion tracking, a six degree of freedom tracking system built upon the technology that powers Motion Text in Motion Stills iOS and the privacy blur on YouTube to accurately track static and moving objects. We refined and enhanced this technology to enable fun AR experiences that can run on any Android device with a gyroscope.
When you touch the viewfinder, Motion Stills AR “sticks” a 3D virtual object to that location, making it look as if it’s part of the real-world scene. By assuming that the tracked surface is parallel to the ground plane, and using the device’s accelerometer sensor to provide the initial orientation of the phone with respect to the ground plane, one can track the six degrees of freedom of the camera (3 for translation and 3 for rotation). This allows us to accurately transform and render the virtual object within the scene.
When the phone is approximately steady, the accelerometer sensor provides the acceleration due to the Earth’s gravity. For horizontal planes the gravity vector is parallel to normal of the tracked plane and can accurately provide the initial orientation of phone.
Instant Motion Tracking The core idea behind instant motion tracking is to decouple the camera’s translation and rotation estimation, treating them instead as independent optimization problems. First, we determine the 3D camera translation solely from the visual signal of the camera. To do this, we observe the target region's apparent 2D translation and relative scale across frames. A simple pinhole camera model relates both translation and scale of a box in the image plane with the final 3D translation of the camera.
The translation and the change in size (relative scale) of the box in the image plane can be used to determine 3D translation between two camera position C1 and C2. However, as our camera model doesn’t assume the focal length of the camera lens, we do not know the true distance/depth of the tracked plane.
To account for this, we added scale estimation to our existing tracker (the one used in Motion Text) as well as region tracking outside the field of view of the camera. When the camera gets closer to the tracked surface, the virtual content scales accurately, which is consistent with perception of real-world objects. When you pan outside the field of view of the target region and back the virtual object will reappear in approximately the same spot.
Independent translation (from visual signal only as shown by red box) and rotation tracking (from gyro; not shown)
After all this, we obtain the device’s 3D rotation (roll, pitch and yaw) using the phone’s built-in gyroscope. The estimated 3D translation combined with the 3D rotation provides us with the ability to render the virtual content correctly in the viewfinder. And because we treat rotation and translation separately, our instant motion tracking approach is calibration free and works on any Android device with a gyroscope.
Augmented chicken family with Motion Stills AR mode
We are excited to bring this new mode to Motion Stills for Android, and we hope you’ll enjoy it. Please download the new release of Motion Stills and keep sending us feedback with #motionstills on your favorite social media.
Acknowledgements For rendering, we are thankful we were able to leverage Google’s Lullaby engine using animated Poly models. A thank you to our team members who worked on the tech and this launch with us: John Nack, Suril Shah, Igor Kibalchich, Siarhei Kazakou, and Matthias Grundmann.
Posted by Michele Covell, Research Scientist, Google Research
Image compression is critical to digital photography — without it, a 12 megapixel image would take 36 megabytes of storage, making most websites prohibitively large. While the signal-processing community has significantly improved image compression beyond JPEG (which was introduced in the 1980’s) with modern image codecs (e.g., BPG, WebP), many of the techniques used in these modern codecs still use the same family of pixel transforms as are used in JPEG. Multiple recent Google projects improve the field of image compression with end-to-end with machine learning, compression through superresolution and creating perceptually improved JPEG images, but we believe that even greater improvements to image compression can be obtained by bringing this research challenge to the attention of the larger machine learning community.
To encourage progress in this field, Google, in collaboration with ETH and Twitter, is sponsoring the Workshop and Challenge on Learned Image Compression (CLIC) at the upcoming 2018 Computer Vision and Pattern Recognition conference (CVPR 2018). The workshop will bring together established contributors to traditional image compression with early contributors to the emerging field of learning-based image compression systems. Our invited speakers include image and video compression experts Jim Bankoski (Google) and Jens Ohm (RWTH Aachen University), as well as computer vision and machine learning experts with experience in video and image compression, Oren Rippel (WaveOne) and Ramin Zabih (Google, on leave from Cornell).
Training set of 1,633 uncompressed images from both the Mobile and Professional datasets, available on compression.cc
A database of copyright-free, high-quality images will be made available both for this challenge and in an effort to accelerate research in this area: Dataset P (“professional”) and Dataset M (“mobile”). The datasets are collected to be representative for images commonly used in the wild, containing thousands of images. While the challenge will allow participants to train neural networks or other methods on any amount of data (but we expect participants to have access to additional data, such as ImageNet and the Open Images Dataset), it should be possible to train on the datasets provided.
The first large-image compression systems using neural networks were published in 2016 [Toderici2016, Ballé2016] and were only just matching JPEG performance. More recent systems have made rapid advances, to the point that they match or exceed the performance of modern industry-standard image compression [Ballé2017, Theis2017, Agustsson2017, Santurkar2017, Rippel2017]. This rapid advance in the quality of neural-network-based compression systems, based on the work of a comparatively small number of research labs, leads us to expect even more impressive results when the area is explored by a larger portion of the machine-learning community.
We hope to get your help advancing the state-of-the-art in this important application area, and we encourage you to participate if you are planning to attend CVPR this year! Please see compression.cc for more details about the new datasets and important workshop deadlines. Training data is already available on that site. The test set will be released on February 15 and the deadline for submitting the compressed versions of the test set is February 22.
Posted by Hossein Talebi, Software Engineer and Peyman Milanfar Research Scientist, Machine Perception
Quantification of image quality and aesthetics has been a long-standing problem in image processing and computer vision. While technical quality assessment deals with measuring pixel-level degradations such as noise, blur, compression artifacts, etc., aesthetic assessment captures semantic level characteristics associated with emotions and beauty in images. Recently, deep convolutional neural networks (CNNs) trained with human-labelled data have been used to address the subjective nature of image quality for specific classes of images, such as landscapes. However, these approaches can be limited in their scope, as they typically categorize images to two classes of low and high quality. Our proposed method predicts the distribution of ratings. This leads to a more accurate quality prediction with higher correlation to the ground truth ratings, and is applicable to general images.
In “NIMA: Neural Image Assessment” we introduce a deep CNN that is trained to predict which images a typical user would rate as looking good (technically) or attractive (aesthetically). NIMA relies on the success of state-of-the-art deep object recognition networks, building on their ability to understand general categories of objects despite many variations. Our proposed network can be used to not only score images reliably and with high correlation to human perception, but also it is useful for a variety of labor intensive and subjective tasks such as intelligent photo editing, optimizing visual quality for increased user engagement, or minimizing perceived visual errors in an imaging pipeline.
Background In general, image quality assessment can be categorized into full-reference and no-reference approaches. If a reference “ideal” image is available, image quality metrics such as PSNR, SSIM, etc. have been developed. When a reference image is not available, “blind” (or no-reference) approaches rely on statistical models to predict image quality. The main goal of both approaches is to predict a quality score that correlates well with human perception. In a deep CNN approach to image quality assessment, weights are initialized by training on object classification related datasets (e.g. ImageNet), and then fine-tuned on annotated data for perceptual quality assessment tasks.
NIMA Typical aesthetic prediction methods categorize images as low/high quality. This is despite the fact that each image in the training data is associated to a histogram of human ratings, rather than a single binary score. A histogram of ratings is an indicator of overall quality of an image, as well as agreements among raters. In our approach, instead of classifying images a low/high score or regressing to the mean score, the NIMA model produces a distribution of ratings for any given image — on a scale of 1 to 10, NIMA assigns likelihoods to each of the possible scores. This is more directly in line with how training data is typically captured, and it turns out to be a better predictor of human preferences when measured against other approaches (more details are available in our paper).
Various functions of the NIMA vector score (such as the mean) can then be used to rank photos aesthetically. Some test photos from the large-scale database for Aesthetic Visual Analysis (AVA) dataset, as ranked by NIMA, are shown below. Each AVA photo is scored by an average of 200 people in response to photography contests. After training, the aesthetic ranking of these photos by NIMA closely matches the mean scores given by human raters. We find that NIMA performs equally well on other datasets, with predicted quality scores close to human ratings.
Ranking some examples labelled with the “landscape” tag from AVA dataset using NIMA. Predicted NIMA (and ground truth) scores are shown below each image.
NIMA scores can also be used to compare the quality of images of the same subject which may have been distorted in various ways. Images shown in the following example are part of the TID2013 test set, which contain various types and levels of distortions.
Ranking some examples from TID2013 dataset using NIMA. Predicted NIMA scores are shown below each image.
Perceptual Image Enhancement As we’ve shown in another recent paper, quality and aesthetic scores can also be used to perceptually tune image enhancement operators. In other words, maximizing NIMA score as part of a loss function can increase the likelihood of enhancing perceptual quality of an image. The following example shows that NIMA can be used as a training loss to tune a tone enhancement algorithm. We observed that the baseline aesthetic ratings can be improved by contrast adjustments directed by the NIMA score. Consequently, our model is able to guide a deep CNN filter to find aesthetically near-optimal settings of its parameters, such as brightness, highlights and shadows.
NIMA can be used as a training loss to enhance images. In this example, local tone and contrast of images is enhanced by training a deep CNN with NIMA as its loss. Test images are obtained from the MIT-Adobe FiveK dataset.
Looking Ahead Our work on NIMA suggests that quality assessment models based on machine learning may be capable of a wide range of useful functions. For instance, we may enable users to easily find the best pictures among many; or to even enable improved picture-taking with real-time feedback to the user. On the post-processing side, these models may be used to guide enhancement operators to produce perceptually superior results. In a direct sense, the NIMA network (and others like it) can act as reasonable, though imperfect, proxies for human taste in photos and possibly videos. We’re excited to share these results, though we know that the quest to do better in understanding what quality and aesthetics mean is an ongoing challenge — one that will involve continuing retraining and testing of our models.
Since we released AIY Voice Kit, we've been inspired by the thousands of amazing builds coming in from the maker community. Today, the AIY Team is excited to announce our next project: the AIY Vision Kit — an affordable, hackable, intelligent camera.
Much like the Voice Kit, our Vision Kit is easy to assemble and connects to a Raspberry Pi computer. Based on user feedback, this new kit is designed to work with the smaller Raspberry Pi Zero W computer and runs its vision algorithms on-device so there's no cloud connection required.
Build intelligent devices that can perceive, not just see
The kit materials list includes a VisionBonnet, a cardboard outer shell, an RGB arcade-style button, a piezo speaker, a macro/wide lens kit, flex cables, standoffs, a tripod mounting nut and connecting components.
The VisionBonnet is an accessory board for Raspberry Pi Zero W that features the Intel® Movidius™ MA2450, a low-power vision processing unit capable of running neural networks. This will give makers visual perception instead of image sensing. It can run at speeds of up to 30 frames per second, providing near real-time performance.
Bundled with the software image are three neural network models:
A model based on MobileNetsthat can recognize a thousand common objects.
A model for face detection capable of not only detecting faces in the image, but also scoring facial expressions on a "joy scale" that ranges from "sad" to "laughing."
A model for the important task of discerning between cats, dogs and people.
For those of you who have your own models in mind, we've included the original TensorFlow code and a compiler. Take a new model you have (or train) and run it on the the Intel® Movidius™ MA2450.
Extend the kit to solve your real-world problems
The AIY Vision Kit is completely hackable:
Want to prototype your own product? The Vision Kit and the Raspberry Pi Zero W can fit into any number of tiny enclosures.
Want to change the way the camera reacts? Use the Python API to write new software to customize the RGB button colors, piezo element sounds and GPIO pins.
Want to add more lights, buttons, or servos? Use the 4 GPIO expansion pins to connect your own hardware.
We hope you'll use it to solve interesting challenges, such as:
Build "hotdog/not hotdog" (or any other food recognizer)
Turn music on when someone walks through the door
Send a text when your car leaves the driveway
Open the dog door when she wants to get back in the house
*** Please note that AIY Vision Kit requires Raspberry Pi Zero W, Raspberry Pi Camera V2 and a micro SD card, which must be purchased separately.
Tell us what you think!
We're listening — let us know how we can improve our kits and share what you're making using the #AIYProjects hashtag on social media. We hope AIY Vision Kit inspires you to build all kinds of creative devices.
Looking at a landmark and not sure what it is? Interested in learning more about a movie as you stroll by the poster? With Google Lens and your Google Assistant, you now have a helpful sidekick to tell you more about what’s around you, right on your Pixel.
When we introduced the new Pixel 2 last month, we talked about how Google Lens builds on Google’s advancements in computer vision and machine learning. When you combine that with the Google Assistant, which is built on many of the same technologies, you can get quick help with what you see. That means that you can learn more about what’s in front of you—in real time—by selecting the Google Lens icon and tapping on what you’re interested in.
Here are the key ways your Assistant and Google Lens can help you today:
Text: Save information from business cards, follow URLs, call phone numbers and navigate to addresses.
Landmarks: Explore a new city like a pro with your Assistant to help you recognize landmarks and learn about their history.
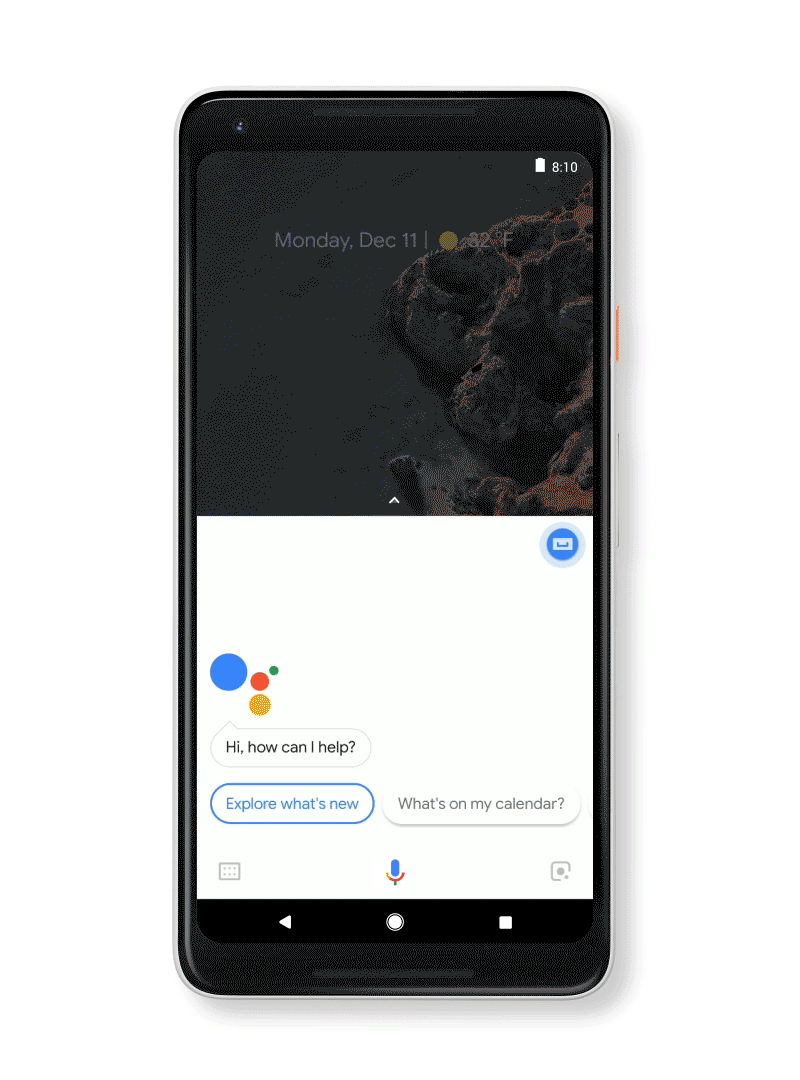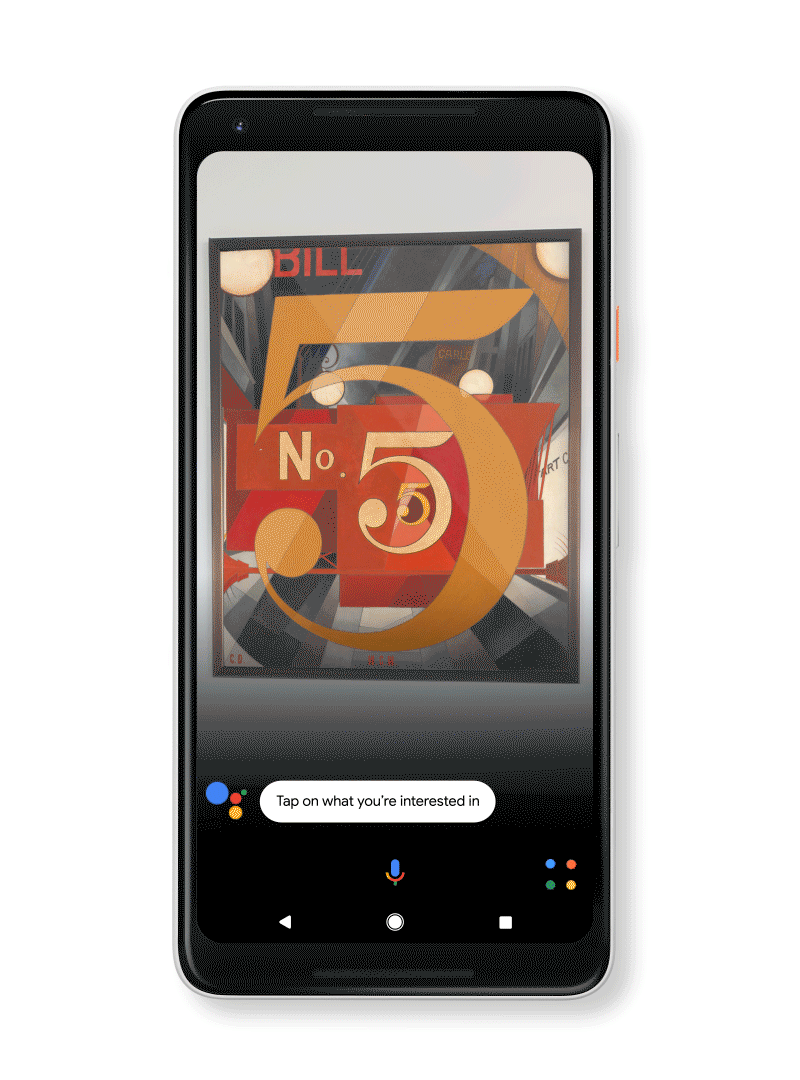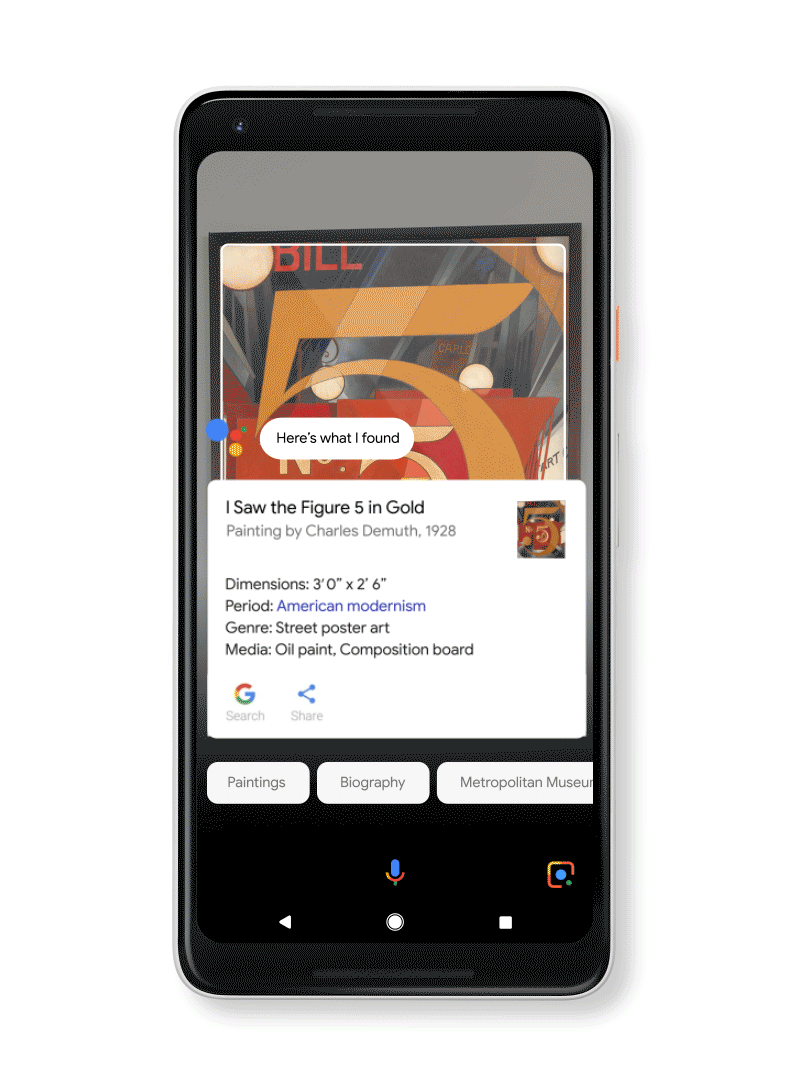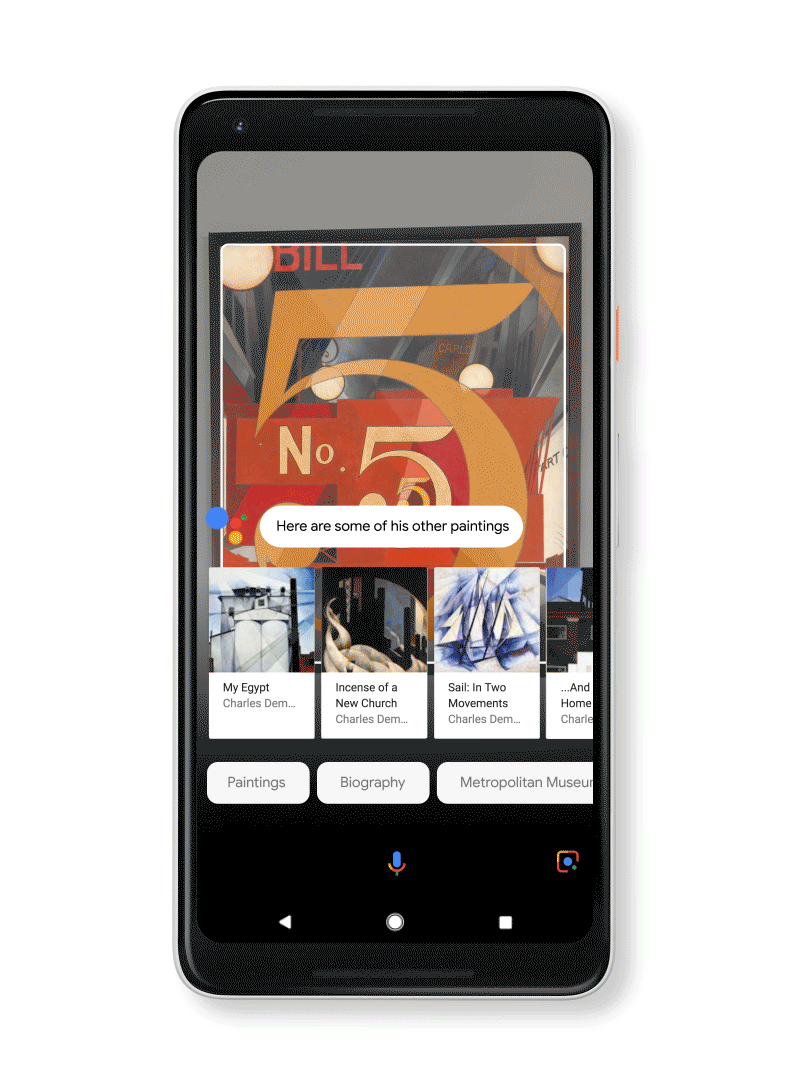
Art, books and movies: Learn more about a movie, from the trailer to reviews, right from the poster. Look up a book to see the rating and a short synopsis. Become a museum guru by quickly looking up an artist’s info and more. You can even add events, like the movie release date or gallery opening, to your calendar right from Google Lens.
Barcodes: Quickly look up products by barcode, or scan QR codes, all with your Assistant.
Google Lens in the Assistant will be rolling out to all Pixel phones set to English in the U.S., U.K., Australia, Canada, India and Singapore over the coming weeks. Once you get the update, go to your Google Assistant on your phone and tap the Google Lens icon in the bottom right corner.
We can’t wait to see how Google Lens helps you explore the world around you, with the help of your Google Assistant. And don’t forget, Google Lens is also available in Google Photos, so even after you take a picture, you can continue to explore and get more information about what’s in your photo.
Posted by Ibrahim Badr, Associate Product Manager, Google Assistant
Posted by Chia-Kai Liang, Senior Staff Software Engineer and Fuhao Shi, Android Camera Team
One of the most important aspects of current smartphones is easily capturing and sharing videos. With the Pixel 2 and Pixel 2 XL smartphones, the videos you capture are smoother and clearer than ever before, thanks to our Fused Video Stabilization technique based on both optical image stabilization (OIS) and electronic image stabilization (EIS). Fused Video Stabilization delivers highly stable footage with minimal artifacts, and the Pixel 2 is currently rated as the leader in DxO's video ranking (also earning the highest overall rating for a smartphone camera). But how does it work?
A key principle in videography is keeping the camera motion smooth and steady. A stable video is free of the distraction, so the viewer can focus on the subject of interest. But, videos taken with smartphones are subject to many conditions that make taking a high-quality video a significant challenge:
Camera Shake Most people hold their mobile phones in their hands to record videos - you pull the phone from your pocket, record the video, and the video is ready to share right after recording. However, that means your videos shake as much as your hands do -- and they shake a lot! Moreover, if you are walking or running while recording, the camera motion can make videos almost unwatchable: Motion Blur If the camera or the subject moves during exposure, the resulting photo or video will appear blurry. Even if we stabilize the motion in between consecutive frames, the motion blur in each individual frame cannot be easily restored in practice, especially on a mobile device. One typical video artifact due to motion blur is sharpness inconsistency: the video may rapidly alternate between blurry and sharp, which is very distracting even after the video is stabilized: Rolling Shutter The CMOS image sensor collects one row of pixels, or “scanline”, at a time, and it takes tens of milliseconds to goes from the top scanline to the bottom. Therefore, anything moving during this period can appear distorted. This is called the rolling shutter distortion. Even if you have a steady hand, the rolling shutter distortion will appear when you move quickly:
A simulated rendering of a video with global (left) and rolling (right) shutter.
Focus Breathing When there are objects of varying distance in a video, the angle of view can change significantly due to objects “jumping” in and out of the foreground. As result, everything shrinks or expands like the video below, which professionals call “breathing”: A good stabilization system should address all of these issues: the video should look sharp, the motion should be smooth, and the rolling shutter and focus breathing should be corrected.
Many professionals mount the camera on a mechanical stabilizer to entirely isolate hand motion. These devices actively sense and compensate for the camera’s movement to remove all unwanted motions. However, they are usually expensive and cumbersome; you wouldn’t want to carry one every day. There are also handheld gimbal mounts available for mobile phones. However, they are usually larger than the phone itself, and you have to put the phone on it before start recording. You’d need to do it fast before the interesting moment vanishes.
Optical Image Stabilization (OIS) is the most well-known method for suppression of handshake artifacts. Typically, in mobile camera modules with OIS, the lens is suspended in the middle of the module by a number of springs and electromagnets are used to move the lens within its enclosure. The lens module actively senses and compensates for handshake motion at very high speeds. Because OIS responds to motion rapidly, it can greatly suppress the handshake blur. However, the range of correctable motion is fairly limited (usually around 1-2 degrees), which is not enough to correct the unwanted motions between consecutive video frames, or to correct excessive motion blur during walking. Moveover, OIS cannot correct some kinds of motions, such as in-plane rotation. Sometimes it can even introduce a “jello” artifact:
The video is taken by Pixel 2 with only OIS enabled. You can see the frame center is stabilized, but the boundaries have some jello-like artifacts.
Electronic Image Stabilization (EIS) analyzes the camera motion, filters out the unwanted parts, and synthesizes a new video by transforming each frame. The final stabilization quality depends on the algorithm design and implementation optimization of these stages. In general, software-based EIS is more flexible than OIS so it can correct larger and more kinds of motions. However, EIS has some common limitations. First, to prevent undefined regions in the synthesized frame, it needs to reduce the field of view or resolution. Second, compared to OIS or an external stabilizer, EIS requires more computation, which is a limited resource on mobile phones.
Making a Better Video: Fused Video Stabilization With Fused Video Stabilization, both OIS and EIS are enabled simultaneously during video recording to address all the issues mentioned above. Our solution has three processing stages as shown in the system diagram below. The first processing stage, motion analysis, extracts the gyroscope signal, the OIS motion, and other properties to estimate the camera motion precisely. Then, the motion filtering stage combines machine learning and signal processing to predict a person’s intention in moving the camera. Finally, in the frame synthesis stage, we model and remove the rolling shutter and focus breathing distortion. With Fused Video Stabilization, the videos from Pixel 2 have less motion blur and look more natural. The solution is efficient enough to run in all video modes, such as 60fps or 4K recording.
Motion Analysis In the motion analysis stage, we use the phone’s high-speed gyroscope to estimate the rotational component of the hand motion (roll, pitch, and yaw). By sensing the motion at 200 Hz, we have dense motion vectors for each scanline, enough to model the rolling shutter distortion. We also measure lens motions that are not sensed by the gyroscope, including both the focus adjustment (z) and the OIS movement (x and y) at high speed. Because we need high temporal precision to model the rolling shutter effect, we carefully optimize the system to ensure perfect timestamp alignment between the CMOS image sensor, the gyroscope, and the lens motion readouts. A misalignment of merely a few milliseconds can introduce noticeable jittering artifact:
Left: The stabilized video of a “running” motion with a 3ms timing error. Note the occasional jittering. Right: The stabilized video with correct timestamps. The bottom right corner shows the original shaky video.
Motion Filtering The motion filtering stage takes the real camera motion from motion analysis and creates the stabilized virtual camera motion. Note that we push the incoming frames into a queue to defer the processing. This enables us to lookahead at future camera motions, using machine learning to accurately predict the user’s intention. Lookahead filtering is not feasible for OIS or any mechanical stabilizers, which can only react to previous or present motions. We will discuss more about this below.
Frame Synthesis At the final stage, we derive how the frame is transformed based on the real and virtual camera motions. To handle the rolling shutter distortion, we use multiple transformations for each frame. We split the the input frame into a mesh and warp each part separately:
Left: The input video with mesh overlay. Right: The warped frame, and the red rectangle is the final stabilized output. Note how the non-rigid warping corrects the rolling shutter distortion.
Lookahead Motion Filtering One key feature in the Fused Video Stabilization is our new lookahead filtering algorithm. It analyzes future motions to recognize the user-intended motion patterns, and creates a smooth virtual camera motion. The lookahead filtering has multiple stages to incrementally improve the virtual camera motion for each frame. In the first step, a Gaussian filtering is applied on the real camera motions of both past and future to obtain a smoothed camera motion:
Left: The input unstabilized video. Right: The smoothed result after Gaussian filtering.
You’ll notice that it’s still not very stable. To further improve the quality, we trained a model to extract intentional motions from the noisy real camera motions. We then apply additional filters given the predicted motion. For example, if we predict the camera is panning horizontally, we would reject more vertical motions. The result is shown below.
Left: The Gaussian filtered result. Right: Our lookahead result. We predict that the user is panning to the right, and suppress more vertical motions.
In practice, the process above does not guarantee there is no undefined “bad” regions, which can appear when the virtual camera is too stabilized and the warped frame falls outside the original field of view. We predict the likelihood of this issue in the next couple frames and adjust the virtual camera motion to get the final result.
Left: Our lookahead result. The undefined area at the bottom-left are shown in cyan. Right: The final result with the bad region removed.
As we mentioned earlier, even with OIS enabled, sometimes the motions are too large and cause motion blur in a single frame. When EIS is further applied to further smooth the camera motion, the motion blur leads to distracting sharpness variations:
Left: Pixel 2 with OIS only. Right: Pixel 2 with the basic Fused Video Stabilization. Note that sharpness variation around the “Exit” label.
This is a very common problem in EIS solutions. To address this issue, we exploit the “masking” property in the human visual system. Motion blur usually blurs the frame along a specific direction, and if the overall frame motion follows that direction, the human eye will not notice it. Instead, our brain treats the blur as a natural part of the motion, and masks it away from our perception.
With the high-frequency gyroscope and OIS signals, we can accurately estimate the motion blur for each frame. We compute where the camera pointed to at both the beginning and end of exposure, and the movement in-between is the motion blur. After that, we apply a machine learning algorithm (trained on a set of videos with and without motion blur) to map the motion blurs in past and future frames to the amount of real camera motion we want to keep, and blend the weighted real camera motion with the virtual one. As you can see below, with the motion blur masking, the distracting sharpness variation is greatly reduced and the camera motion is still stabilized.
Left: Pixel 2 with the basic Fused Video Stabilization. Right: The full Fused Video Stabilization solution with motion blur masking.
Results We have seen many amazing videos from Pixel 2 with Fused Video Stabilization. Here are some for you to check out:
Videos taken by two Pixel 2 phones mounted on a single hand grip. Fused Video Stabilization is disabled in the left one.
Videos taken by two Pixel 2 phones mounting on a single hand grip. Fused Video Stabilization is disabled in the left one. Note that the videographer jumped together with the subject.
Fused Video Stabilization combines the best of OIS and EIS, shows great results in camera motion smoothing and motion blur reduction, and corrects both rolling shutter and focus breathing. With Fused Video Stabilization on the Pixel 2 and Pixel 2 XL, you no longer have to carefully place the phone before recording, hold it firmly over the entire recording session, or carry a gimbal mount everywhere. The recorded video will always be stable, sharp, and ready to share.
Acknowledgements Fused Video Stabilization is a large-scale effort across multiple teams in Google, including the camera algorithm team, sensor algorithm team, camera hardware team, and sensor hardware team.
Posted by Mike Krainin, Software Engineer and Ce Liu, Research Scientist, Machine Perception
In 2007, we introduced Google Street View, enabling you to explore the world through panoramas of neighborhoods, landmarks, museums and more, right from your browser or mobile device. The creation of these panoramas is a complicated process, involving capturing images from a multi-camera rig called a rosette, and then using image blending techniques to carefully stitch them all together. However, many things can thwart the creation of a "successful" panorama, such as mis-calibration of the rosette camera geometry, timing differences between adjacent cameras, and parallax. And while we attempt to address these issues by using approximate scene geometry to account for parallax and frequent camera re-calibration, visible seams in image overlap regions can still occur.
Left: A Street View car carrying a multi-camera rosette. Center: A close-up of the rosette, which is made up of 15 cameras. Right: A visualization of the spatial coverage of each camera. Overlap between adjacent cameras is shown in darker gray.
Left: The Sydney Opera House with stitching seams along its iconic shells. Right: The same Street View panorama after optical flow seam repair.
In order to provide more seamless Street View images, we’ve developed a new algorithm based on optical flow to help solve these challenges. The idea is to subtly warp each input image such that the image content lines up within regions of overlap. This needs to be done carefully to avoid introducing new types of visual artifacts. The approach must also be robust to varying scene geometry, lighting conditions, calibration quality, and many other conditions. To simplify the task of aligning the images and to satisfy computational requirements, we’ve broken it into two steps.
Optical Flow The first step is to find corresponding pixel locations for each pair of images that overlap. Using techniques described in our PhotoScan blog post, we compute optical flow from one image to the other. This provides a smooth and dense correspondence field. We then downsample the correspondences for computational efficiency. We also discard correspondences where there isn’t enough visual structure to be confident in the results of optical flow.
The boundaries of a pair of constituent images from the rosette camera rig that need to be stitched together.
An illustration of optical flow within the pair’s overlap region.
Extracted correspondences in the pair of images. For each colored dot in the overlap region of the left image, there is an equivalently-colored dot in the overlap region of the right image, indicating how the optical flow algorithm has aligned the point. These pairs of corresponding points are used as input to the global optimization stage. Notice that the overlap covers only a small portion of each image.
Global Optimization The second step is to warp the rosette’s images to simultaneously align all of the corresponding points from overlap regions (as seen in the figure above). When stitched into a panorama, the set of warped images will then properly align. This is challenging because the overlap regions cover only a small fraction of each image, resulting in an under-constrained problem. To generate visually pleasing results across the whole image, we formulate the warping as a spline-based flow field with spatial regularization. The spline parameters are solved for in a non-linear optimization using Google’s open source Ceres Solver.
A visualization of the final warping process. Left: A section of the panorama covering 180 degrees horizontally. Notice that the overall effect of warping is intentionally quite subtle. Right: A close-up, highlighting how warping repairs the seams.
Our approach has many similarities to previously published work by Shum & Szeliski on “deghosting” panoramas. Key differences include that our approach estimates dense, smooth correspondences (rather than patch-wise, independent correspondences), and we solve a nonlinear optimization for the final warping. The result is a more well-behaved warping that is less likely to introduce new visual artifacts than the kernel-based approach.
Left: A close-up of the un-repaired panorama. Middle: Result of kernel-based interpolation. This fixes discontinuities but at the expense of strong wobbling artifacts due to the small image overlap and limited footprint of kernels. Right: Result of our global optimization.
This is important because our algorithm needs to be robust to the enormous diversity in content in Street View’s billions of panoramas. You can see how effective the algorithm is in the following examples:
Tower Bridge, London
Christ the Redeemer, Rio de Janeiro
An SUV on the streets of Seattle
This new algorithm was recently added to the Street View stitching pipeline. It is now being used to restitch existing panoramas on an ongoing basis. Keep an eye out for improved Street View near you!
Acknowledgements Special thanks to Bryan Klingner for helping to integrate this feature with the Street View infrastructure.
Posted by Konstantinos Bousmalis, Senior Research Scientist, and Sergey Levine, Faculty Advisor, Google Brain
Each of us can learn remarkably complex skills that far exceed the proficiency and robustness of even the most sophisticated robots, when it comes to basic sensorimotor skills like grasping. However, we also draw on a lifetime of experience, learning over the course of multiple years how to interact with the world around us. Requiring such a lifetime of experience for a learning-based robot system is quite burdensome: the robot would need to operate continuously, autonomously, and initially at a low level of proficiency before it can become useful. Fortunately, robots have a powerful tool at their disposal: simulation.
Simulating many years of robotic interaction is quite feasible with modern parallel computing, physics simulation, and rendering technology. Moreover, the resulting data comes with automatically-generated annotations, which is particularly important for tasks where success is hard to infer automatically. The challenge with simulated training is that even the best available simulators do not perfectly capture reality. Models trained purely on synthetic data fail to generalize to the real world, as there is a discrepancy between simulated and real environments, in terms of both visual and physical properties. In fact, the more we increase the fidelity of our simulations, the more effort we have to expend in order to build them, both in terms of implementing complex physical phenomena and in terms of creating the content (e.g., objects, backgrounds) to populate these simulations. This difficulty is compounded by the fact that powerful optimization methods based on deep learning are exceptionally proficient at exploiting simulator flaws: the more powerful the machine learning algorithm, the more likely it is to discover how to "cheat" the simulator to succeed in ways that are infeasible in the real world. The question then becomes: how can a robot utilize simulation to enable it to perform useful tasks in the real world?
The difficulty of transferring simulated experience into the real world is often called the "reality gap." The reality gap is a subtle but important discrepancy between reality and simulation that prevents simulated robotic experience from directly enabling effective real-world performance. Visual perception often constitutes the widest part of the reality gap: while simulated images continue to improve in fidelity, the peculiar and pathological regularities of synthetic pictures, and the wide, unpredictable diversity of real-world images, makes bridging the reality gap particularly difficult when the robot must use vision to perceive the world, as is the case for example in many manipulation tasks. Recent advances in closing the reality gap with deep learning in computer vision for tasks such as object classification and pose estimation provide promising solutions. For example, Shrivastava et al. and Bousmalis et al. explored pixel-level domain adaptation. Ganin et al. and Bousmalis and Trigeorgis et al. focus on feature-level domain adaptation. These advances required a rethinking of the approaches used to solve the simulation-to-reality domain shift problem for robotic manipulation as well. Although a number of recent works have sought to address the reality gap in robotics, through techniques such as machine learning-based domain adaptation (Tzeng et al.) and randomization of simulated environments (Sadeghi and Levine), effective transfer in robotic manipulation has been limited to relatively simple tasks, such as grasping rectangular, brightly-colored objects (Tobin et al. and James et al.) and free-space motion (Christiano et al.). In this post, we describe how learning in simulation, in our case PyBullet, and using domain adaptation methods such as machine learning methods that deal with the simulation-to-reality domain shift, can accelerate learning of robotic grasping in the real world. This approach can enable real robots to grasp a large of variety physical objects, unseen during training, with a high degree of proficiency.
The performance effect of using 8 million simulated samples of procedural objects with no randomization and various amounts of real data.
Before we consider introducing simulated experience, what does it take for our robots to learn to reliably grasp such not-before-seen objects with only real-world experience? In a previous post, we discussed how the Google Brain team and X’s robotics teams teach robots how to grasp a variety of ordinary objects by just using images from a single monocular camera. It takes tens to hundreds of thousands of grasp attempts, the equivalent of thousands of robot-hours of real-world experience. Although distributing the learning across multiple robots expedites this, the realities of real-world data collection, including maintenance and wear-and-tear, mean that these kinds of data collection efforts still take a significant amount of real time. As mentioned above, an appealing alternative is to use off-the-shelf simulators and learn basic sensorimotor skills like grasping in a virtual environment. Training a robot how to grasp in simulation can be parallelized easily over any number of machines, and can provide large amounts of experience in dramatically less time (e.g., hours rather than months) and at a fraction of the cost.
If the goal is to bridge the reality gap for vision-based robotic manipulation, we must answer a few critical questions. First, how do we design simulation so that simulated experience appears realistic to a neural network? And second, how should we integrate simulated and real experience in a way that maximizes transfer to the real world? We studied these questions in the context of a particularly challenging and important robotic manipulation task: vision-based grasping of diverse objects. We extensively evaluated the effect of various simulation design decisions in combination with various techniques for integrating simulated and real experience for maximal performance.
The setup we used for collecting the simulated and real-world datasets.
Images used during training of simulated grasping experience with procedurally generated objects (left) and of real-world experience with a varied collection of everyday physical objects (right). In both cases, we see pairs of image inputs with and without the robot arm present.
When it comes to simulation, there are a number of choices we have to make: the type of objects to use for simulated grasping, whether to use appearance and/or dynamics randomization, and whether to extract any additional information from the simulator that could aid adaptation to the real world. The types of objects we use in simulation is a particularly important one, and there are a number of choices. A question that comes naturally is: how realistic do the objects used in simulation need to be? Using randomly generated procedural objects is the most desirable choice, because these objects are generated effortlessly on demand, and are easy to parameterize if we change the requirements of the task. However, they are not realistic and one could imagine they might not be useful for transferring the experience of grasping them to the real world. Using realistic 3D object models from a publicly available model library, such as the widely used ShapeNet, is another choice, which however restricts our findings to be related to the characteristics of the specific models we are using. In this work, we compared the effect of using procedurally-generated and realistic objects from the ShapeNet model repository, and found that simply using random objects generated programmatically was not just sufficient for efficient experience transfer from simulation to reality, but also generalized better to the real world than using ShapeNet ones.
Some of the procedurally-generated objects used in simulation.
Some of the ShapeNet objects used in simulation.
Some of the physical objects used to collect real grasping experience.
Another decision about our simulated environment has to do with the randomization of the simulation. Simulation randomization has shown promise in providing generalization to real-world environments in previous work. We further evaluate randomization as a way to provide generalization by separately evaluating the effect of using appearance randomization (randomly changing textures of different visual components of the virtual environment), and dynamics randomization (randomly changing object mass, and friction properties). For our task, visual randomization had a positive effect when we did not use domain adaptation methods to aid with generalization, and had no effect when we included domain adaptation. Using dynamics randomization did not show a significant improvement for this particular task, however it is possible that dynamics randomization might be more relevant in other tasks. These results suggest that, although randomization can be an important part of simulation-to-real-world transfer, the inclusion of effective domain adaptation can have a substantially more pronounced impact for vision-based manipulation tasks.
Appearance randomization in simulation.
Finally, the information we choose to extract and use for our domain adaptation methods has a significant impact on performance. In one of our proposed methods, we utilize the extracted semantic map of the simulated image, ie the description of each pixel in the simulated image, and use it to ground our proposed domain adaptation approach to produce semantically-meaningful realistic samples, as we discuss below.
Our main proposed approach to integrating simulated and real experience, which we call GraspGAN, takes as input synthetic images generated by a simulator, along with their semantic maps, and produces adapted images that look similar to real-world ones. This is possible with adversarial training, a powerful idea proposed by Goodfellow et al. In our framework, a convolutional neural network, the generator, takes as input synthetic images and generates images that another neural network, the discriminator, cannot distinguish from actual real images. The generator and discriminator networks are trained simultaneously and improve together, resulting in a generator that can produce images that are both realistic and useful for learning a grasping model that will generalize to the real world. One way to make sure that these images are useful is the use of the semantic maps of the synthetic images to ground the generator. By using the prediction of these masks as an auxiliary task, the generator is encouraged to produce meaningful adapted images that correspond to the original label attributed to the simulated experience. We train a deep vision-based grasping model with both visually-adapted simulated and real images, and attempt to account for the domain shift further by using a feature-level domain adaptation technique which helps produce a domain-invariant model. See below the GraspGAN adapting simulated images to realistic ones and a semantic map it infers.
By using synthetic data and domain adaptation we are able to reduce the number of real-world samples required to achieve a given level of performance by up to 50 times, using only randomly generated objects in simulation. This means that we have no prior information about the objects in the real world, other than pre-specified size limits for the graspable objects. We have shown that we are able to increase performance with various amounts of real-world data, and also that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with hundreds of thousands of labeled real-world samples. This suggests that, instead of collecting labeled experience, it may be sufficient in the future to simply record raw unlabeled images, use them to train a GraspGAN model, and then learn the skills themselves in simulation.
Although this work has not addressed all the issues around closing the reality gap, we believe that our results show that using simulation and domain adaptation to integrate simulated and real robotic experience is an attractive choice for training robots. Most importantly, we have extensively evaluated the performance gains for different available amounts of labeled real-world samples, and for the different design choices for both the simulator and the domain adaptation methods used. This evaluation can hopefully serve as a guide for practitioners to use for their own design decisions and for weighing the advantages and disadvantages of incorporating such an approach in their experimental design.
This research was conducted by K. Bousmalis, A. Irpan, P. Wohlhart, Y. Bai, M, Kelcey, M. Kalakrishnan, L. Downs, J. Ibarz, P. Pastor, K. Konolige, S. Levine, V. Vanhoucke, with special thanks to colleagues at Google Research and X who've contributed their expertise and time to this research. An early preprint is available on arXiv. The collection of procedurally-generated objects we used in simulation was made publicly available here by Laura Downs.
Posted by Chunhui Gu & David Ross, Software Engineers
Teaching machines to understand human actions in videos is a fundamental research problem in Computer Vision, essential to applications such as personal video search and discovery, sports analysis, and gesture interfaces. Despite exciting breakthroughs made over the past years in classifying and finding objects in images, recognizing human actions still remains a big challenge. This is due to the fact that actions are, by nature, less well-defined than objects in videos, making it difficult to construct a finely labeled action video dataset. And while many benchmarking datasets, e.g., UCF101, ActivityNet and DeepMind’s Kinetics, adopt the labeling scheme of image classification and assign one label to each video or video clip in the dataset, no dataset exists for complex scenes containing multiple people who could be performing different actions.
In order to facilitate further research into human action recognition, we have released AVA, coined from “atomic visual actions”, a new dataset that provides multiple action labels for each person in extended video sequences. AVA consists of URLs for publicly available videos from YouTube, annotated with a set of 80 atomic actions (e.g. “walk”, “kick (an object)”, “shake hands”) that are spatial-temporally localized, resulting in 57.6k video segments, 96k labeled humans performing actions, and a total of 210k action labels. You can browse the website to explore the dataset and download annotations, and read our arXiv paper that describes the design and development of the dataset.
Compared with other action datasets, AVA possesses the following key characteristics:
Person-centric annotation. Each action label is associated with a person rather than a video or clip. Hence, we are able to assign different labels to multiple people performing different actions in the same scene, which is quite common.
Atomic visual actions. We limit our action labels to fine temporal scales (3 seconds), where actions are physical in nature and have clear visual signatures.
Realistic video material. We use movies as the source of AVA, drawing from a variety of genres and countries of origin. As a result, a wide range of human behaviors appear in the data.
Examples of 3-second video segments (from Video Source) with their bounding box annotations in the middle frame of each segment. (For clarity, only one bounding box is shown for each example.)
To create AVA, we first collected a diverse set of long form content from YouTube, focusing on the “film” and “television” categories, featuring professional actors of many different nationalities. We analyzed a 15 minute clip from each video, and uniformly partitioned it into 300 non-overlapping 3-second segments. The sampling strategy preserved sequences of actions in a coherent temporal context.
Next, we manually labeled all bounding boxes of persons in the middle frame of each 3-second segment. For each person in the bounding box, annotators selected a variable number of labels from a pre-defined atomic action vocabulary (with 80 classes) that describe the person’s actions within the segment. These actions were divided into three groups: pose/movement actions, person-object interactions, and person-person interactions. Because we exhaustively labeled all people performing all actions, the frequencies of AVA’s labels followed a long-tail distribution, as summarized below.
Distribution of AVA’s atomic action labels. Labels displayed in the x-axis are only a partial set of our vocabulary.
The unique design of AVA allows us to derive some interesting statistics that are not available in other existing datasets. For example, given the large number of persons with at least two labels, we can measure the co-occurrence patterns of action labels. The figure below shows the top co-occurring action pairs in AVA with their co-occurrence scores. We confirm expected patterns such as people frequently play instruments while singing, lift a person while playing with kids, and hug while kissing.
Top co-occurring action pairs in AVA.
To evaluate the effectiveness of human action recognition systems on the AVA dataset, we implemented an existing baseline deep learning model that obtains highly competitive performance on the much smaller JHMDB dataset. Due to challenging variations in zoom, background clutter, cinematography, and appearance variation, this model achieves a relatively modest performance when correctly identifying actions on AVA (18.4% mAP). This suggests that AVA will be a useful testbed for developing and evaluating new action recognition architectures and algorithms for years to come.
We hope that the release of AVA will help improve the development of human action recognition systems, and provide opportunities to model complex activities based on labels with fine spatio-temporal granularity at the level of individual person’s actions. We will continue to expand and improve AVA, and are eager to hear feedback from the community to help us guide future directions. Please join the AVA users mailing list to receive dataset updates as well as to send us emails for feedback.
Acknowledgements The core team behind AVA includes Chunhui Gu, Chen Sun, David Ross, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, and Jitendra Malik. We thank many Google colleagues and annotators for their dedicated support on this project.