Object detection is an extensively studied computer vision problem, but most of the research has focused on 2D object prediction. While 2D prediction only provides 2D bounding boxes, by extending prediction to 3D, one can capture an object’s size, position and orientation in the world, leading to a variety of applications in robotics, self-driving vehicles, image retrieval, and augmented reality. Although 2D object detection is relatively mature and has been widely used in the industry, 3D object detection from 2D imagery is a challenging problem, due to the lack of data and diversity of appearances and shapes of objects within a category.
Today, we are announcing the release of MediaPipe Objectron, a mobile real-time 3D object detection pipeline for everyday objects. This pipeline detects objects in 2D images, and estimates their poses and sizes through a machine learning (ML) model, trained on a newly created 3D dataset. Implemented in MediaPipe, an open-source cross-platform framework for building pipelines to process perceptual data of different modalities, Objectron computes oriented 3D bounding boxes of objects in real-time on mobile devices.
 |
 |  |
| 3D Object Detection from a single image. MediaPipe Objectron determines the position, orientation and size of everyday objects in real-time on mobile devices. |
While there are ample amounts of 3D data for street scenes, due to the popularity of research into self-driving cars that rely on 3D capture sensors like LIDAR, datasets with ground truth 3D annotations for more granular everyday objects are extremely limited. To overcome this problem, we developed a novel data pipeline using mobile augmented reality (AR) session data. With the arrival of ARCore and ARKit, hundreds of millions of smartphones now have AR capabilities and the ability to capture additional information during an AR session, including the camera pose, sparse 3D point clouds, estimated lighting, and planar surfaces.
In order to label ground truth data, we built a novel annotation tool for use with AR session data, which allows annotators to quickly label 3D bounding boxes for objects. This tool uses a split-screen view to display 2D video frames on which are overlaid 3D bounding boxes on the left, alongside a view showing 3D point clouds, camera positions and detected planes on the right. Annotators draw 3D bounding boxes in the 3D view, and verify its location by reviewing the projections in 2D video frames. For static objects, we only need to annotate an object in a single frame and propagate its location to all frames using the ground truth camera pose information from the AR session data, which makes the procedure highly efficient.
 |
| Real-world data annotation for 3D object detection. Right: 3D bounding boxes are annotated in the 3D world with detected surfaces and point clouds. Left: Projections of annotated 3D bounding boxes are overlaid on top of video frames making it easy to validate the annotation. |
A popular approach is to complement real-world data with synthetic data in order to increase the accuracy of prediction. However, attempts to do so often yield poor, unrealistic data or, in the case of photorealistic rendering, require significant effort and compute. Our novel approach, called AR Synthetic Data Generation, places virtual objects into scenes that have AR session data, which allows us to leverage camera poses, detected planar surfaces, and estimated lighting to generate placements that are physically probable and with lighting that matches the scene. This approach results in high-quality synthetic data with rendered objects that respect the scene geometry and fit seamlessly into real backgrounds. By combining real-world data and AR synthetic data, we are able to increase the accuracy by about 10%.
 |
| An example of AR synthetic data generation. The virtual white-brown cereal box is rendered into the real scene, next to the real blue book. |
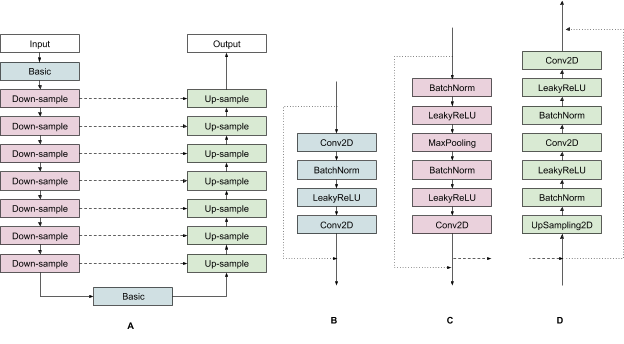
We built a single-stage model to predict the pose and physical size of an object from a single RGB image. The model backbone has an encoder-decoder architecture, built upon MobileNetv2. We employ a multi-task learning approach, jointly predicting an object's shape with detection and regression. The shape task predicts the object's shape signals depending on what ground truth annotation is available, e.g. segmentation. This is optional if there is no shape annotation in training data. For the detection task, we use the annotated bounding boxes and fit a Gaussian to the box, with center at the box centroid, and standard deviations proportional to the box size. The goal for detection is then to predict this distribution with its peak representing the object’s center location. The regression task estimates the 2D projections of the eight bounding box vertices. To obtain the final 3D coordinates for the bounding box, we leverage a well established pose estimation algorithm (EPnP). It can recover the 3D bounding box of an object, without a priori knowledge of the object dimensions. Given the 3D bounding box, we can easily compute pose and size of the object. The diagram below shows our network architecture and post-processing. The model is light enough to run real-time on mobile devices (at 26 FPS on an Adreno 650 mobile GPU).
 |
| Network architecture and post-processing for 3D object detection. |
 |
| Sample results of our network — [left] original 2D image with estimated bounding boxes, [middle] object detection by Gaussian distribution, [right] predicted segmentation mask. |
When the model is applied to every frame captured by the mobile device, it can suffer from jitter due to the ambiguity of the 3D bounding box estimated in each frame. To mitigate this, we adopt the detection+tracking framework recently released in our 2D object detection and tracking solution. This framework mitigates the need to run the network on every frame, allowing the use of heavier and therefore more accurate models, while keeping the pipeline real-time on mobile devices. It also retains object identity across frames and ensures that the prediction is temporally consistent, reducing the jitter.
For further efficiency in our mobile pipeline, we run our model inference only once every few frames. Next, we take the prediction and track it over time using the approach described in our previous blogs for instant motion tracking and Motion Stills. When a new prediction is made, we consolidate the detection result with the tracking result based on the area of overlap.
To encourage researchers and developers to experiment and prototype based on our pipeline, we are releasing our on-device ML pipeline in MediaPipe, including an end-to-end demo mobile application and our trained models for two categories: shoes and chairs. We hope that sharing our solution with the wide research and development community will stimulate new use cases, new applications, and new research efforts. In the future, we plan to scale our model to many more categories, and further improve our on-device performance.
 |  |  |
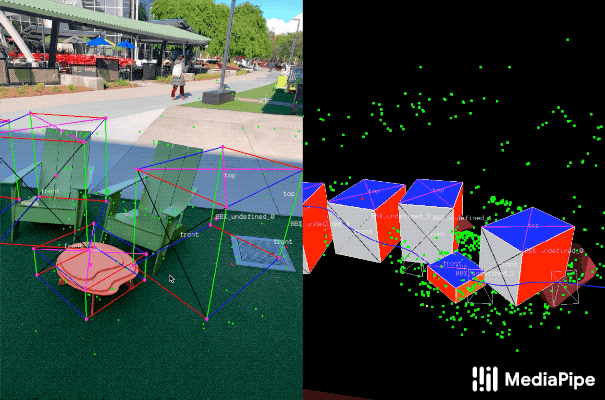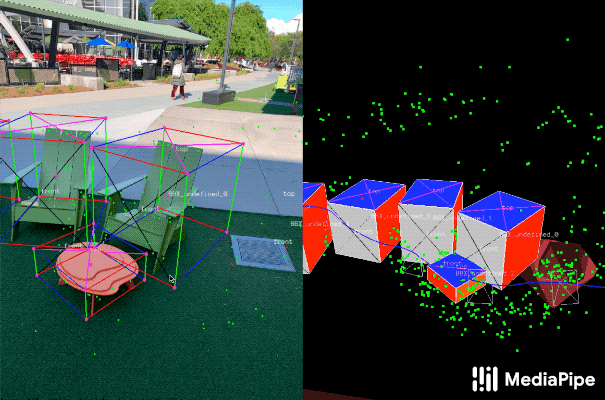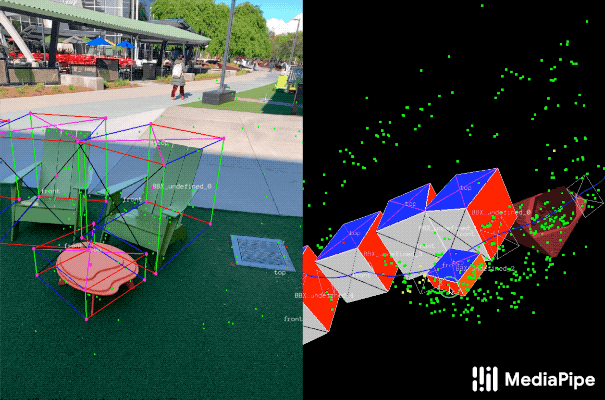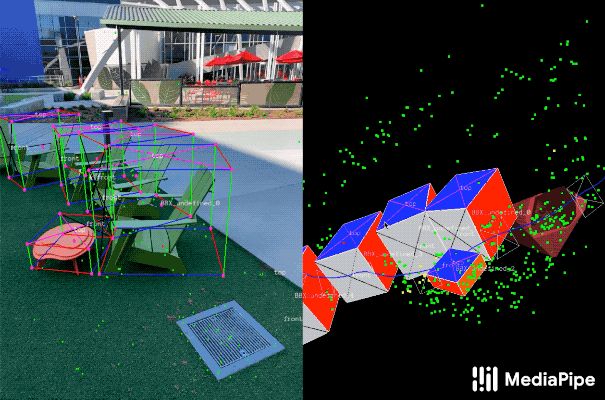
| Examples of our 3D object detection in the wild. |
The research described in this post was done by Adel Ahmadyan, Tingbo Hou, Jianing Wei, Matthias Grundmann, Liangkai Zhang, Jiuqiang Tang, Chris McClanahan, Tyler Mullen, Buck Bourdon, Esha Uboweja, Mogan Shieh, Siarhei Kazakou, Ming Guang Yong, Chuo-Ling Chang, and James Bruce. We thank Aliaksandr Shyrokau and the annotation team for their diligence to high quality annotations.