Posted by Wesley Chun (@wescpy), Developer Advocate, Google Cloud
Background
App Engine initially launched in 2008, providing a suite of bundled services making it convenient for applications to access a database (Datastore), caching service (Memcache), independent task execution (Task Queue), Google Sign-In authentication (Users), or large "blob" storage (Blobstore), or other companion services. However, apps leveraging those services can only run their apps on App Engine.
To increase app portability and help Google move towards its goal of having the most open cloud on the market, App Engine launched its 2nd-generation service in 2018, initially removing those legacy services. The newer platform allows developers to upgrade apps to the latest language runtimes, such as moving from Python 2 to 3 or Java 8 to 11 (and today, Java 17). One of the major drawbacks to the 1st-generation runtimes is that they're customized, proprietary, and restrictive in what you can use or can't.
Instead, the 2nd-generation platform uses open source runtimes, meaning ability to follow standard development practices, use common/known idioms, and have fewer restrictions of 3rd-party libraries, and obviating the need to copy or "vendor" them with your code. Unfortunately, to use these newer runtimes, migrating away from App Engine services were required because while you could upgrade language releases, there was no access to bundled services, breaking apps or requiring complete rewrites, making it a showstopper for many users.
Due to their popularity and the desire to ease the upgrade process for customers, the App Engine team restored access to most (but not all) of those services in Fall 2021. Today's Serverless Migration Station video demonstrates how to continue usage of bundled services available to Python 3 developers.
Performing the upgrade
- Migrate from the
webapp2framework (not available in Python 3) - Port from Python 2 to 3, preserve use of bundled services
- Optional migration to Cloud standalone or similar 3rd-party services
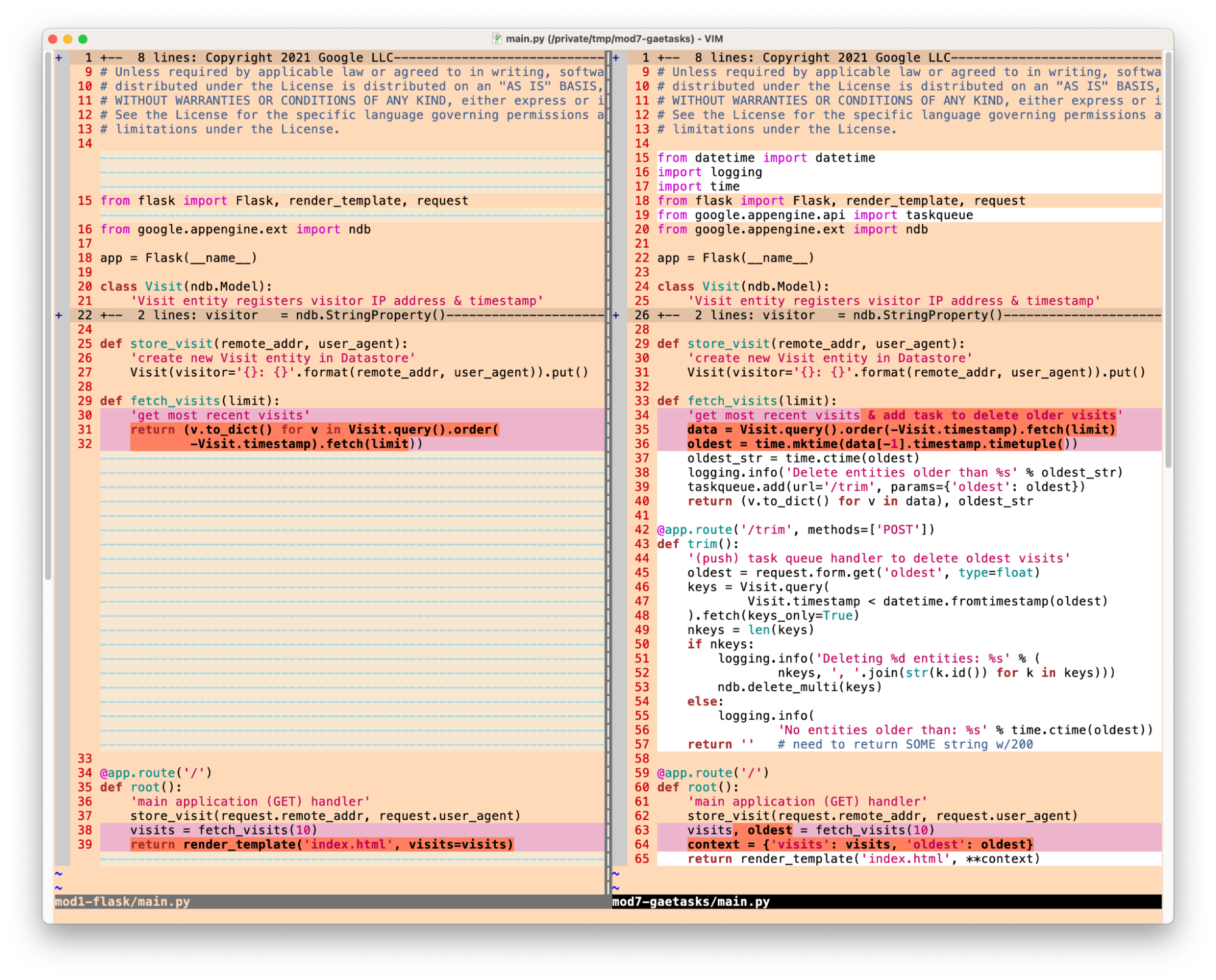
The first step is to move to a standard Python web framework like Flask, Django, Pyramid, etc. Below is some pseudocode from Migration Module 1 demonstrating how to migrate from webapp2 to Flask:
 |
| Step 1: Port Python 2 sample app from webapp2 to Flask |
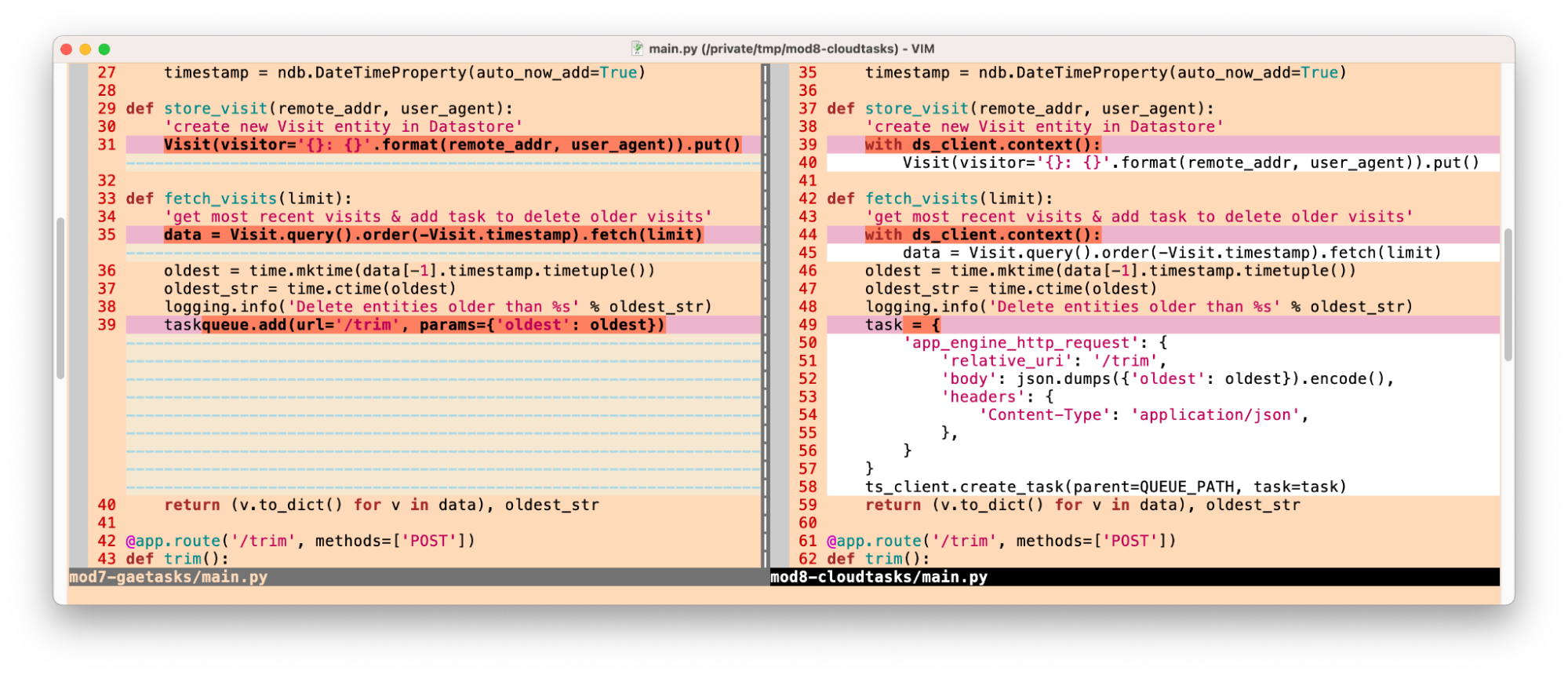
The key changes are bolded in the above code snippets. Notice how the App Engine NDB code [the Visit class definition plus store_visit() and fetch_visits() functions] are unaffected by this web framework migration. The full webapp2 code sample can be found in the Module 0 repo folder while the completed migration to Flask sample is located in the Module 1 repo folder.
After your app has ported frameworks, you're free to upgrade to Python 3 while preserving access to the bundled services if your app uses any. Below is pseudocode demonstrating how to upgrade the same sample app to Python 3 as well as the code changes needed to continue to use App Engine NDB:
 |
| Step 2: Port sample app to Python 3, preserving use of NDB bundled service |
The NDB code is also left untouched in this migration. Not all of the bundled services feature such a hands-free migration, and we hope to cover some of the more complex ones ahead in Module 22. Java, PHP, and Go users have it even better, requiring fewer or no code changes at all. The Python 2 Flask sample is located in the Module 1 repo folder, and the resulting Python 3 app can be found in the Module 1b repo folder.
The immediate benefit of step two is the ability to upgrade to a more current version of language runtime. This leaves the third step of migrating off the bundled services as optional, especially if you plan on staying on App Engine for the long-term.
Additional options
If you decide to migrate off the bundled services, you can do so on your own timeline. It should be a consideration should you ever want to move to modern serverless platforms such as Cloud Functions or Cloud Run, to lower-level platforms because you want more control, like GKE, our managed Kubernetes service, or Compute Engine VMs.
Step three is also where the rest of the Serverless Migration Station content may be useful:
- Migrate from App Engine NDB to Cloud NDB (Module 2)
- Migrate from App Engine Task Queue push tasks to Cloud Tasks (Modules 7-9)
- Migrate from App Engine Task Queue pull tasks to Cloud Pub/Sub (Modules 18-19)*
- Migrate from App Engine Memcache to Cloud Memorystore (Modules 12-13)
- Migrate from App Engine Blobstore to Cloud Storage (Modules 15-16)
- Migrate from App Engine Users to Cloud Identity Platform (Modules 20-21)*
- Migrate from App Engine webapp2 to Flask (Module 1)
- Migrate from App Engine/Cloud NDB to Cloud Datastore (Module 3)
*code samples and codelabs available; videos forthcoming
As far as moving to modern serverless platforms, if you want to break apart a large App Engine app into multiple microservices, consider Cloud Functions. If your organization has added containerization as part of your software development workflow, consider Cloud Run. It's suitable for apps if you're familiar with containers and Docker, but even if you or your team don't have that experience, Cloud Buildpacks can do the heavy lifting for you. Here are the relevant migration modules to explore:
- Migrate from App Engine to Cloud Functions (Module 11)
- Migrate from App Engine to Cloud Run with Docker (Module 4)
- Migrate from App Engine to Cloud Run without Docker via Cloud Buildpacks (Module 5)
Wrap-up
Early App Engine users appreciate the convenience of the platform's bundled services, and after listening to user feedback, adding them back to 2nd-generation runtimes is another way we can help developers modernize their apps. Whether upgrading to newer language runtimes to stay on App Engine and continue to use its bundled services, migrating to Cloud standalone products, or shifting to other serverless platforms, the Google Cloud team aims to provide the tools to help streamline your modernization efforts.All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, the Cloud team is working on covering other language runtimes, so stay tuned. Today's video features a special guest to provide a teaser of what to expect for Java. For additional video content, check out the broader Serverless Expeditions series.