Posted by Zhicheng Wang and Genzhi Ye, MediaPipe team
Image Feature Correspondence with KNIFT
In many computer vision applications, a crucial building block is to establish reliable correspondences between different views of an object or scene, forming the foundation for approaches like template matching, image retrieval and structure from motion. Correspondences are usually computed by extracting distinctive view-invariant features such as SIFT or ORB from images. The ability to reliably establish such correspondences enables applications like image stitching to create panoramas or template matching for object recognition in videos (see Figure 1).
Today, we are announcing KNIFT (Keypoint Neural Invariant Feature Transform), a general purpose local feature descriptor similar to SIFT or ORB. Likewise, KNIFT is also a compact vector representation of local image patches that is invariant to uniform scaling, orientation, and illumination changes. However unlike SIFT or ORB, which were engineered with heuristics, KNIFT is an embedding learned directly from a large number of corresponding local patches extracted from nearby video frames. This data driven approach implicitly encodes complex, real-world spatial transformations and lighting changes in the embedding. As a result, the KNIFT feature descriptor appears to be more robust, not only to affine distortions, but to some degree of perspective distortions as well. We are releasing an implementation of KNIFT in MediaPipe and a KNIFT-based template matching demo in the next section to get you started.

Figure 1: Matching a real Stop Sign with a Stop Sign template using KNIFT.
Training Method
In Machine Learning, loosely speaking, training an embedding means finding a mapping that can translate a high dimensional vector, such as an image patch, to a relatively lower dimensional vector, such as a feature descriptor. Ideally, this mapping should have the following property: image patches around a real-world point should have the same or very similar descriptors across different views or illumination changes. We have found real world videos a good source of such corresponding image patches as training data (See Figure 3 and 4) and we use the well-established Triplet Loss (see Figure 2) to train such an embedding. Each triplet consists of an anchor (denoted by a), a positive (p), and a negative (n) feature vector extracted from the corresponding image patches, and d() denotes the Euclidean distance in the feature space.

Figure 2: Triplet Loss Function.
Training Data
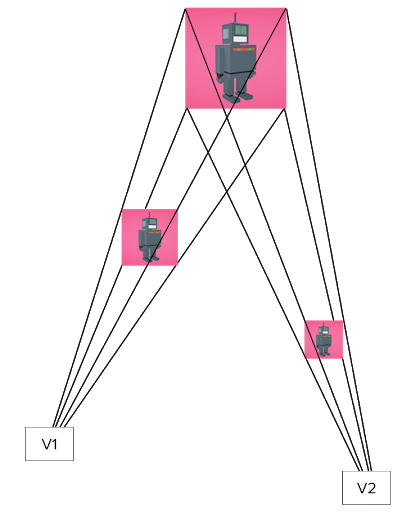
The training triplets are extracted from all ~1500 video clips in the publicly available YouTube UGC Dataset. We first use an existing heuristically-engineered local feature detector to detect keypoints and compute the affine transform between two frames with a high accuracy (see Figure 4). Then we use this correspondence to find keypoint pairs and extract the patches around these keypoints. Note that the newly identified keypoints may include those that were detected but rejected by geometric verification in the first step. For each pair of matched patches, we randomly apply some form of data augmentation (e.g. random rotation or brightness adjustment) to construct the anchor-positive pair. Finally, we randomly pick an arbitrary patch from another video as the negative to finish the construction of this triplet (see Figure 5).

Figure 3: An example video clip from which we extract training triplets.

Figure 4: Finding frame correspondence using existing local features.

Figure 5: (Top to bottom) Anchor, positive and negative patches.
Hard-negative Triplet Mining
To improve model quality, we use the same hard-negative triplet mining method used by FaceNet training. We first train a base model with randomly selected triplets. Then we implement a pipeline that uses the base model to find semi-hard-negative samples (d(a,p) < d(a,n) < d(a,p)+margin) for each anchor-positive pair (Figure 6). After mixing the randomly selected triplets and hard-negative triplets, we re-train the model with this improved data.

Figure 6: (Top to bottom) Anchor, positive and semi-hard negative patches.
Model Architecture
From model architecture exploration, we have found that a relatively small architecture is sufficient to achieve decent quality, so we use a lightweight version of the Inception architecture as the KNIFT model backbone. The resulting KNIFT descriptor is a 40-dimensional float vector. For more model details, please refer to the KNIFT model card.
Benchmark
We benchmark the KNIFT model inference speed on various devices (computing 200 features) and list them in Table 1.

Table 1: KNIFT performance benchmark.
Quality-wise, we compare the average number of keypoints matched by KNIFT and by ORB (OpenCV implementation) respectively on an in-house benchmark (Table 2). There are many publicly available image matching benchmarks, e.g. 2020 Image Matching Benchmark, but most of them focus on matching landmarks across large perspective changes in relatively high resolution images, and the tasks often require computing thousands of keypoints. In contrast, since we designed KNIFT for matching objects in large scale (i.e. billions of images) online image retrieval tasks, we devised our benchmark to focus on low cost and high precision driven use cases, i.e. 100-200 keypoints computed per image and only ~10 matching keypoints needed for reliably determining a match. In addition, to illustrate the fine-grained performance characteristics of a feature descriptor, we divide and categorize the benchmark set by object types (e.g. 2D planar surface) and image pair relations (e.g. large size difference). In table 2, we compare the average number of keypoints matched by KNIFT and by ORB respectively in each category, based on the same 200 keypoint locations detected in each image by the oFast detector that comes with the ORB implementation in OpenCV.

Table 2: KNIFT vs ORB average number of matched keypoints.
From Table 2, we can see that KNIFT consistently matches more keypoints than ORB by a large margin in every category. Here we acknowledge the fact that KNIFT (40-d float) is considerably larger than ORB (32-d char) and this can have an effort on matching quality. Nevertheless, most local feature benchmarks do not take descriptor size into account so we will follow the convention here.
To make it easy for developers to try KNIFT in MediaPIpe, we have built a local-feature-based template matching solution (see implementation details using MediaPipe in the next section). As a side effect, we can demonstrate the matching quality between KNIFT and ORB visually in side-by-side comparisons like Figure 7 and 9.
Figure 7: Example of “matching 2D planar surface”. (Left) KNIFT 183/240, (Right) ORB 133/240.
In Figure 7, we choose a typical U.S. Stop Sign image from Google Image Search as the template and attempt to match it with the Stop Sign in this video. This example falls into the “matching 2D planar surface” category in Table 2. Using the same 200 keypoint locations detected by oFast and the same RANSAC setting, we show that KNIFT is successful at matching the Stop Sign in 183 frames out of a total of 240 frames. In comparison, ORB matches 133 frames.

Figure 8: Example of “matching 3D untextured object”. Two template images from different views.

Figure 9: Example of “matching 3D untextured object”. (Left) KNIFT 89/150, (Right) ORB 37/150.
Figure 9 shows another matching performance comparison on an example from the “matching 3D untextured object” category in Table 2. Since this example involves large perspective changes of untextured surfaces, which is known to be challenging for local feature descriptors, we use template images from two different views (shown in Figure 8) to improve the matching performance. Again, using the same keypoint locations and RANSAC setting, we show that KNIFT is successful at matching 89 frames out of a total of 150 frames while ORB matches 37 frames.
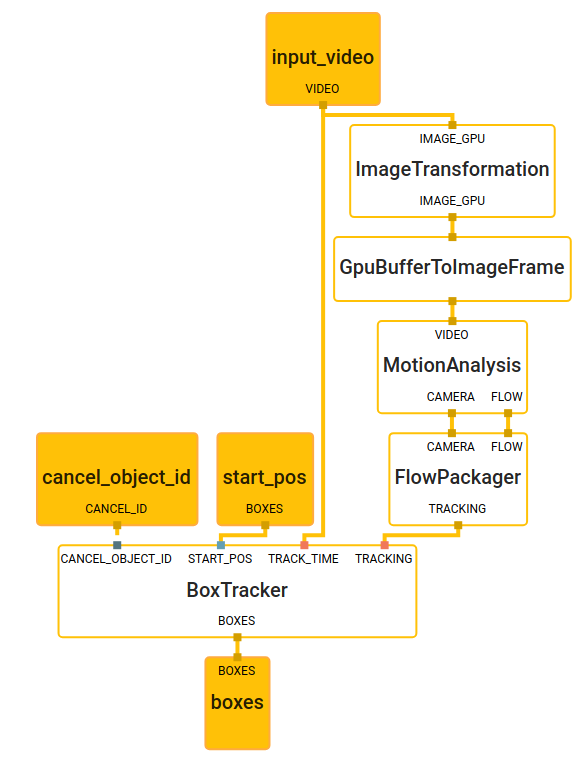
KNIFT-based Template Matching in MediaPipe
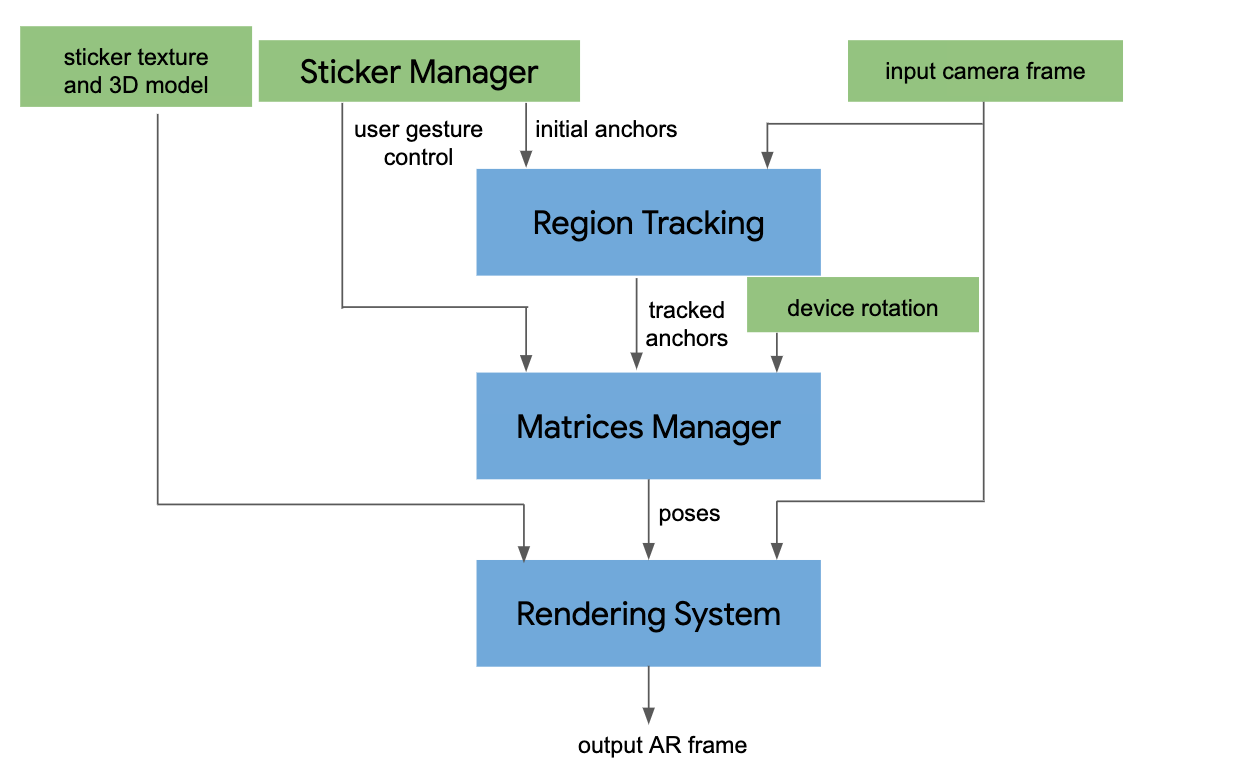
We are releasing the aforementioned template matching solution based on KNIFT in MediaPipe, which is capable of identifying pre-defined image templates and precisely localizing recognized templates on the camera image. There are 3 major components in the template-matching MediaPipe graph shown below:
- FeatureDetectorCalculator: a calculator that consumes image frames and performs OpenCV oFast detector on the input image and outputs keypoint locations. Moreover, this calculator is also responsible for cropping patches around each keypoint with rotation and scale info and stacking them into a vector for the downstream calculator to process.
- TfLiteInferenceCalculator with KNIFT model: a calculator that loads the KNIFT tflite model and performs model inference. The input tensor shape is (200, 32, 32, 1), indicating 200 32x32 local patches. The output tensor shape is (200, 40), indicating 200 40-dimensional feature descriptors. By default, the calculator runs the TFLite XNNPACK delegate, but users have the option to select the regular CPU delegate to run at a reduced speed.
- BoxDetectorCalculator: a calculator that takes pre-computed keypoint locations and KNIFT descriptors and performs feature matching between the current frame and multiple template images. The output of this calculator is a list of TimedBoxProto, which contains the unique id and location of each box as a quadrilateral on the image. Aside from the classic homography RANSAC algorithm, we also apply a perspective transform verification step to ensure that the output quadrilateral does not result in too much skew or a weird shape.

Figure 10: MediaPipe graph of the demo
Demo
In this demo, we chose three different denominations ($1, $5, $20) of U.S. dollar bills as templates and attempted to match them to various real world dollar bills in videos. We resized each input frame to 640x480 pixels, ran the oFast detector to detect 200 keypoints, and used KNIFT to extract feature descriptors from each 32x32 local image patch surrounding these keypoints. We then performed template matching between these video frames and the KNIFT features extracted from the dollar bill templates. This demo runs at 20 FPS on a Pixel 2 Phone CPU with XNNPACK.

Figure 11: Matching different U.S. dollar bills using KNIFT.
Build Your Own Templates
We have provided a set of built-in planar templates in our demo. To make it easy for users to try their own templates, we also provide a tool to build such an index with user generated templates. index_building.pbtxt is a MediaPipe graph that accepts as its input a directory path containing a set of template images. Users can use this graph to compute KNIFT descriptors for all template images (which will be stored in a single file) by 1) replacing the index_proto_filename field in the main graph and the BUILD file and 2) rebuilding the APK file. For step-by-step instructions on how we created the dollar bill demo shown above, please refer to this documentation.
Acknowledgements
We would like to thank Jiuqiang Tang, Chuo-Ling Chang, Dan Gnanapragasam, Howard Zhou, Jianing Wei and Ming Guang Yong for contributing to this blog post.
























 Posted by Michael Hays and Tyler Mullen from the MediaPipe team
Posted by Michael Hays and Tyler Mullen from the MediaPipe team 




 Posted by Billy Rutledge, Director Google Research, Coral Team
Posted by Billy Rutledge, Director Google Research, Coral Team Posted by
Posted by