 Posted by Jasmin Rubinovitz, AI Researcher
Posted by Jasmin Rubinovitz, AI Researcher

Google Lab Sessions is a series of experimental collaborations with innovators. In this session, we partnered with beloved creative coding educator and YouTube creator Daniel Shiffman. Together, we explored some of the ways AI, and specifically the Gemini API, could provide value to teachers and students during the learning process.
Dan Shiffman started out teaching programming courses at NYU ITP and later created his YouTube channel The Coding Train, making his content available to a wider audience. Learning to code can be challenging, sometimes even small obstacles can be hard to overcome when you are on your own. So together with Dan we asked - could we try and complement his teaching even further by creating an AI-powered tool that can help students while they are actually coding, in their coding environment?
Dan uses the wonderful p5.js JavaScript library and its accessible editor to teach code. So we set out to create an experimental chrome extension for the editor, that brings together Dan’s teaching style as well as his various online resources into the coding environment itself.
In this post, we'll share how we used the Gemini API to craft Shiffbot with Dan. We're hoping that some of the things we learned along the way will inspire you to create and build your own ideas.
To learn more about ShiffBot visit - shiffbot.withgoogle.com
As we started defining and tinkering with what this chatbot might be, we found ourselves faced with two key questions:
- How can ShiffBot inspire curiosity, exploration, and creative expression in the same way that Dan does in his classes and videos?
- How can we surface the variety of creative-coding approaches, and surface the deep knowledge of Dan and the community?
Let’s take a look at how we approached these questions by combining Google Gemini API’s capabilities across prompt engineering for Dan’s unique teaching style, alongside embeddings and semantic retrieval with Dan’s collection of educational content.
Tone and delivery: putting the “Shiff” in “ShiffBot”
A text prompt is a thoughtfully designed textual sequence that is used to prime a Large Language Model (LLM) to generate text in a certain way. Like many AI applications, engineering the right prompt was a big part of sculpting the experience.
Whenever a user asks ShiffBot a question, a prompt is constructed in real time from a few different parts; some are static and some are dynamically generated alongside the question.
 |
| ShiffBot prompt building blocks (click to enlarge) |
The first part of the prompt is static and always the same. We worked closely with Dan to phrase it and test many texts, instructions and techniques. We used Google AI Studio, a free web-based developer tool, to rapidly test multiple prompts and potential conversations with ShiffBot.
ShiffBot’s prompt starts with setting the bot persona and defining some instructions and goals for it to follow. The hope was to both create continuity for Dan’s unique energy, as seen in his videos, and also adhere to the teaching principles that his students and fans adore.
We were hoping that ShiffBot could provide encouragement, guidance and access to relevant high-quality resources. And, specifically, do it without simply providing the answer, but rather help students discover their own answers (as there can be more than one).
The instructions draw from Dan’s teaching style by including sentences like “ask the user questions” because that’s what Dan is doing in the classroom. This is a part of the persona / instructions part of the prompt:
The next piece of the prompt utilizes another capability of LLMs called few-shot learning. It means that with just a small number of examples, the model learns patterns and can then use those in new inputs. Practically, as part of the prompt, we provide a number of demonstrations of input and expected output.
We worked with Dan to create a small set of such few-shot examples. These are pairs of <user-input><bot-response> where the <bot-response> is always in our desired ShiffBot style. It looks like this:
Our prompt includes 13 such pairs.
Another thing we noticed as we were working on the extension is that sometimes, giving more context in the prompt helps. In the case of learning creative coding in p5.js, explaining some p5.js principles in the prompt guides the model to use those principles as it answers the user’s question. So we also include those things like:
Everything we discussed up to now is static, meaning that it remains the same for every turn of the conversation between the user and ShiffBot. Now let's explore some of the parts that are constructed dynamically as the conversation evolves.
Conversation and code context
Because ShiffBot is embedded inside the p5.js editor, it can “see” the current code the user is working on, so that it can generate responses that are more personalized and relevant. We grab that information for the HTML DOM and append it to the prompt as well.
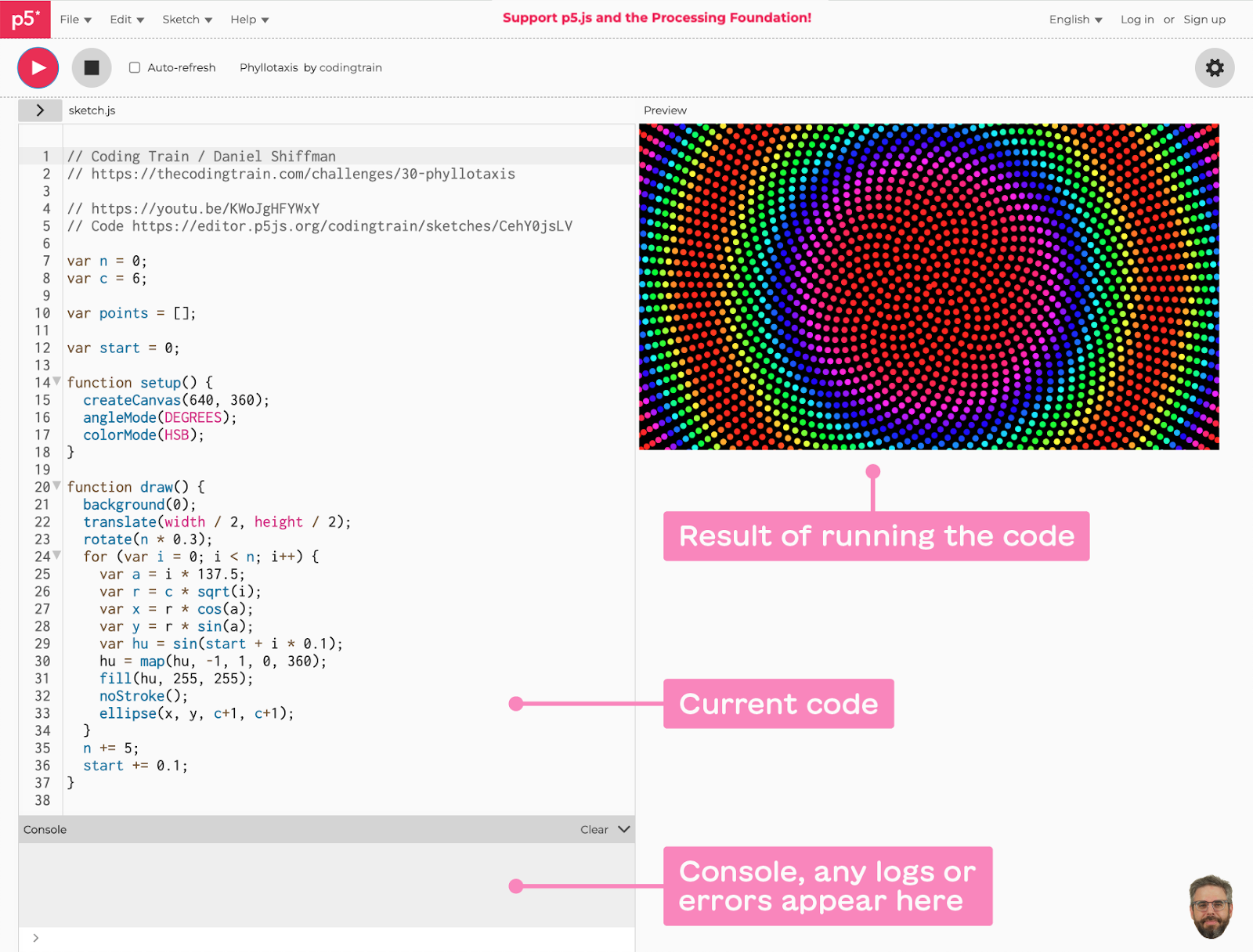 |
| the p5.js editor environment (click to enlarge) |
Then, the full conversation history is appended, e.g:
We make sure to end with
So the model understands that it now needs to complete the next piece of the conversation by ShiffBot.
Semantic Retrieval: grounding the experience in p5.js resources and Dan’s content
Dan has created a lot of material over the years, including over 1,000 YouTube videos, books and code examples. We wanted to have ShiffBot surface these wonderful materials to learners at the right time. To do so, we used the Semantic Retrieval feature in the Gemini API, which allows you to create a corpus of text pieces, and then send it a query and get the texts in your corpus that are most relevant to your query. (Behind the scenes, it uses a cool thing called text embeddings; you can read more about embeddings here.) For ShiffBot we created corpuses from Dan’s content so that we could add relevant content pieces to the prompt as needed, or show them in the conversation with ShiffBot.
Creating a Corpus of Videos
In The Coding Train videos, Dan explains many concepts, from simple to advanced, and runs through coding challenges. Ideally ShiffBot could use and present the right video at the right time.
The Semantic Retrieval in Gemini API allows users to create multiple corpuses. A corpus is built out of documents, and each document contains one or more chunks of text. Documents and chunks can also have metadata fields for filtering or storing more information.
In Dan’s video corpus, each video is a document and the video url is saved as a metadata field along with the video title. The videos are split into chapters (manually by Dan as he uploads them to YouTube). We used each chapter as a chunk, with the text for each chunk being
We use the video title, the first line of the video description and chapter title to give a bit more context for the retrieval to work.
This is an example of a chunk object that represents the R, G, B chapter in this video.
When the user asks ShiffBot a question, the question is embedded to a numerical representation, and Gemini’s Semantic Retrieval feature is used to find the texts whose embeddings are closest to the question. Those relevant video transcripts and links are added to the prompt - so the model could use that information when generating an answer (and potentially add the video itself into the conversation).
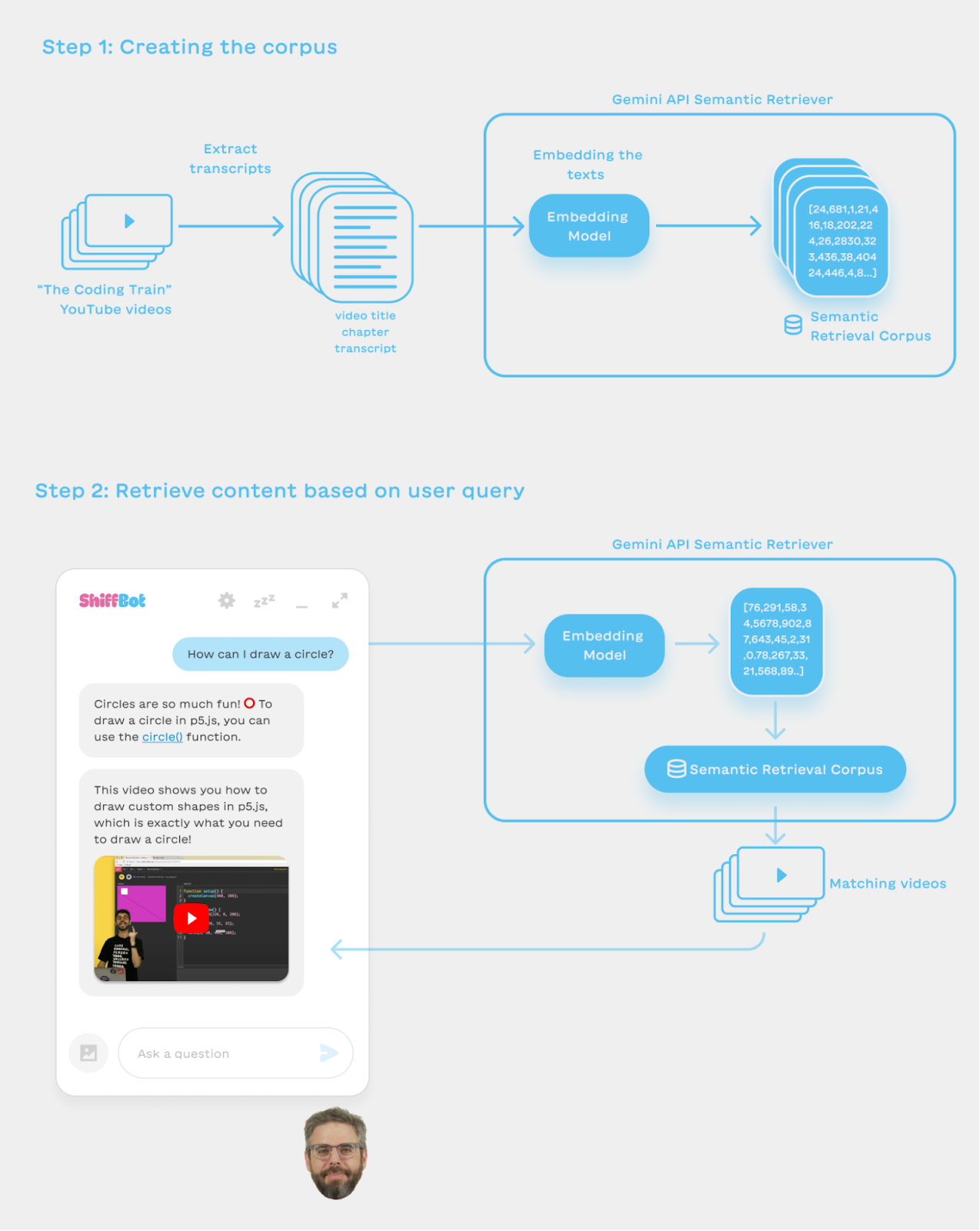 |
| Semantic Retrieval Graph (click to enlarge) |
Creating a Corpus of Code Examples
We do the same with another corpus of p5.js examples written by Dan. To create the code examples corpus, we used Gemini and asked it to explain what the code is doing. Those natural language explanations are added as chunks to the corpus, so that when the user asks a question, we try to find matching descriptions of code examples, the url to the p5.js sketch itself is saved in the metadata, so after retrieving the code itself along with the sketch url is added in the prompt.
To generate the textual description, Gemini was prompted with:
 |
| Constructing the ShiffBot prompt (click to enlarge) |
Other ShiffBot Features Implemented with Gemini
Beside the long prompt that is running the conversation, other smaller prompts are used to generate ShiffBot features.
Seeding the conversation with content pre-generated by Gemini
ShiffBot greetings should be welcoming and fun. Ideally they make the user smile, so we started by thinking with Dan what could be good greetings for ShiffBot. After phrasing a few examples, we use Gemini to generate a bunch more, so we can have a variety in the greetings. Those greetings go into the conversation history and seed it with a unique style, but make ShiffBot feel fun and new every time you start a conversation. We did the same with the initial suggestion chips that show up when you start the conversation. When there’s no conversation context yet, it’s important to have some suggestions of what the user might ask. We pre-generated those to seed the conversation in an interesting and helpful way.
Dynamically Generated Suggestion Chips
Suggestion chips during the conversation should be relevant for what the user is currently trying to do. We have a prompt and a call to Gemini that are solely dedicated to generating the suggested questions chips. In this case, the model’s only task is to suggest followup questions for a given conversation. We also use the few-shot technique here (the same technique we used in the static part of the prompt described above, where we include a few examples for the model to learn from). This time the prompt includes some examples for good suggestions, so that the model could generalize to any conversation:
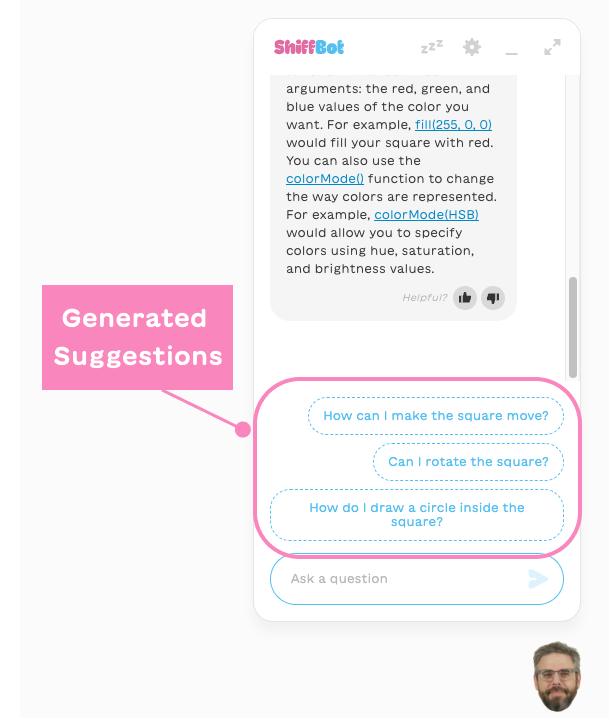 |
| suggested response chips, generated by Gemini (click to enlarge) |
Final thoughts and next steps
ShiffBot is an example of how you can experiment with the Gemini API to build applications with tailored experiences for and with a community.
We found that the techniques above helped us bring out much of the experience that Dan had in mind for his students during our co-creation process. AI is a dynamic field and we’re sure your techniques will evolve with it, but hopefully they are helpful to you as a snapshot of our explorations and towards your own. We are also excited for things to come both in terms of Gemini and API tools that broaden human curiosity and creativity.
For example, we’ve already started to explore how multimodality can help students show ShiffBot their work and the benefits that has on the learning process. We’re now learning how to weave it into the current experience and hope to share it soon.
 |
| experimental exploration of multimodality in ShiffBot (click to enlarge) |
Whether for coding, writing and even thinking, creators play a crucial role in helping us imagine what these collaborations might look like. Our hope is that this Lab Session gives you a glimpse of what’s possible using the Gemini API, and inspires you to use Google’s AI offerings to bring your own ideas to life, in whatever your craft may be.