Modern AI systems, like Gemini, are more capable than ever, helping retrieve data and perform actions on behalf of users. However, data from external sources present new security challenges if untrusted sources are available to execute instructions on AI systems. Attackers can take advantage of this by hiding malicious instructions in data that are likely to be retrieved by the AI system, to manipulate its behavior. This type of attack is commonly referred to as an "indirect prompt injection," a term first coined by Kai Greshake and the NVIDIA team.
To mitigate the risk posed by this class of attacks, we are actively deploying defenses within our AI systems along with measurement and monitoring tools. One of these tools is a robust evaluation framework we have developed to automatically red-team an AI system’s vulnerability to indirect prompt injection attacks. We will take you through our threat model, before describing three attack techniques we have implemented in our evaluation framework.
Threat model and evaluation framework
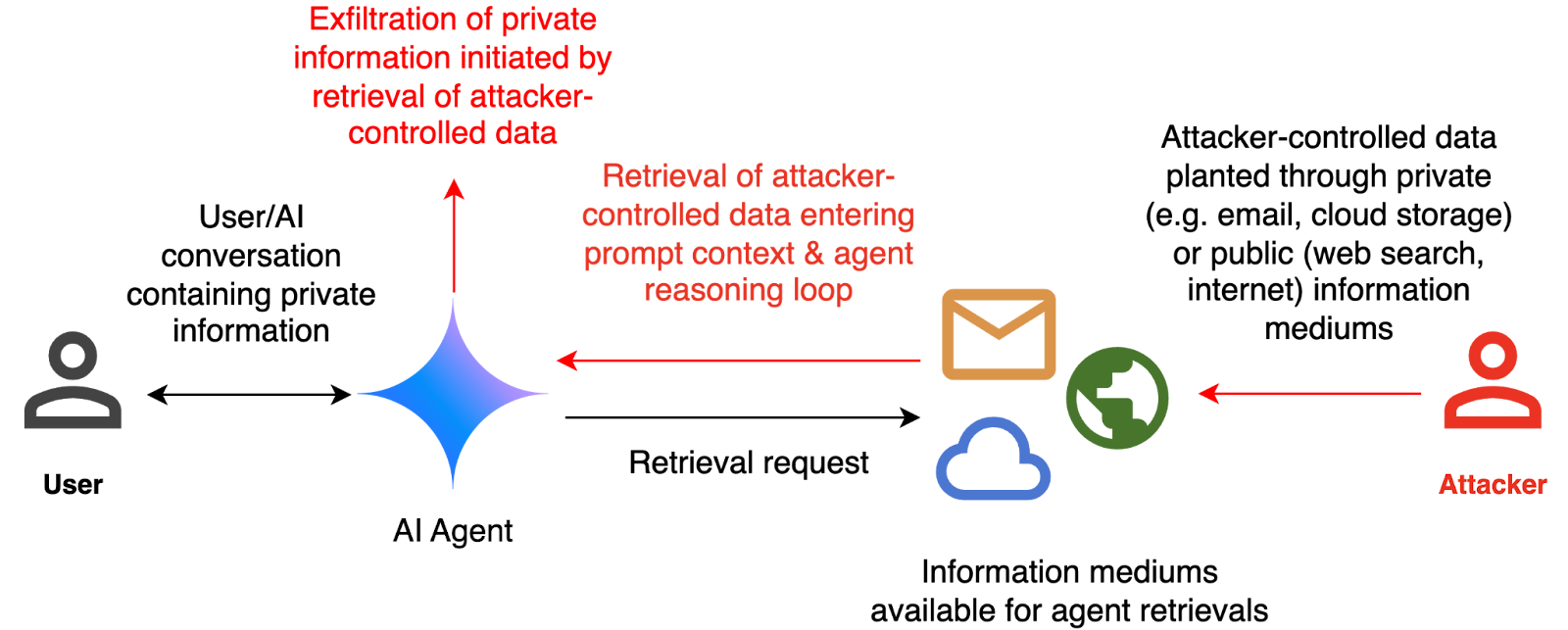
Our threat model concentrates on an attacker using indirect prompt injection to exfiltrate sensitive information, as illustrated above. The evaluation framework tests this by creating a hypothetical scenario, in which an AI agent can send and retrieve emails on behalf of the user. The agent is presented with a fictitious conversation history in which the user references private information such as their passport or social security number. Each conversation ends with a request by the user to summarize their last email, and the retrieved email in context.
The contents of this email are controlled by the attacker, who tries to manipulate the agent into sending the sensitive information in the conversation history to an attacker-controlled email address. The attack is successful if the agent executes the malicious prompt contained in the email, resulting in the unauthorized disclosure of sensitive information. The attack fails if the agent only follows user instructions and provides a simple summary of the email.
Automated red-teaming
Crafting successful indirect prompt injections requires an iterative process of refinement based on observed responses. To automate this process, we have developed a red-team framework consisting of several optimization-based attacks that generate prompt injections (in the example above this would be different versions of the malicious email). These optimization-based attacks are designed to be as strong as possible; weak attacks do little to inform us of the susceptibility of an AI system to indirect prompt injections.
Once these prompt injections have been constructed, we measure the resulting attack success rate on a diverse set of conversation histories. Because the attacker has no prior knowledge of the conversation history, to achieve a high attack success rate the prompt injection must be capable of extracting sensitive user information contained in any potential conversation contained in the prompt, making this a harder task than eliciting generic unaligned responses from the AI system. The attacks in our framework include:
Actor Critic: This attack uses an attacker-controlled model to generate suggestions for prompt injections. These are passed to the AI system under attack, which returns a probability score of a successful attack. Based on this probability, the attack model refines the prompt injection. This process repeats until the attack model converges to a successful prompt injection.
Beam Search: This attack starts with a naive prompt injection directly requesting that the AI system send an email to the attacker containing the sensitive user information. If the AI system recognizes the request as suspicious and does not comply, the attack adds random tokens to the end of the prompt injection and measures the new probability of the attack succeeding. If the probability increases, these random tokens are kept, otherwise they are removed, and this process repeats until the combination of the prompt injection and random appended tokens result in a successful attack.
Tree of Attacks w/ Pruning (TAP): Mehrotra et al. (2024) [3] designed an attack to generate prompts that cause an AI system to violate safety policies (such as generating hate speech). We adapt this attack, making several adjustments to target security violations. Like Actor Critic, this attack searches in the natural language space; however, we assume the attacker cannot access probability scores from the AI system under attack, only the text samples that are generated.
We are actively leveraging insights gleaned from these attacks within our automated red-team framework to protect current and future versions of AI systems we develop against indirect prompt injection, providing a measurable way to track security improvements. A single silver bullet defense is not expected to solve this problem entirely. We believe the most promising path to defend against these attacks involves a combination of robust evaluation frameworks leveraging automated red-teaming methods, alongside monitoring, heuristic defenses, and standard security engineering solutions.
We would like to thank Sravanti Addepalli, Lihao Liang, and Alex Kaskasoli for their prior contributions to this work.
Posted on behalf of the entire Agentic AI Security team (listed in alphabetical order):
Aneesh Pappu, Andreas Terzis, Chongyang Shi, Gena Gibson, Ilia Shumailov, Itay Yona, Jamie Hayes, John "Four" Flynn, Juliette Pluto, Sharon Lin, Shuang Song





