Editor’s note: Today’s blog post comes from Alex Olivier, product manager at Qubit. He’ll be taking us through the solution Qubit provided for Ubisoft, one of the world’s largest gaming companies, to help them personalize customer experiences through data analysis.
Our platform helps brands across a range of sectors — from retail and gaming to travel and hospitality — deliver a personalized digital experience for users. To do so, we analyze thousands of data points throughout a customer’s journey, taking the processing burden away from our clients. This insight prompts our platform to make a decision — for example, including a customer in a VIP segment, or identifying a customer’s interest in a certain product — and adapts the visitor’s experience accordingly.
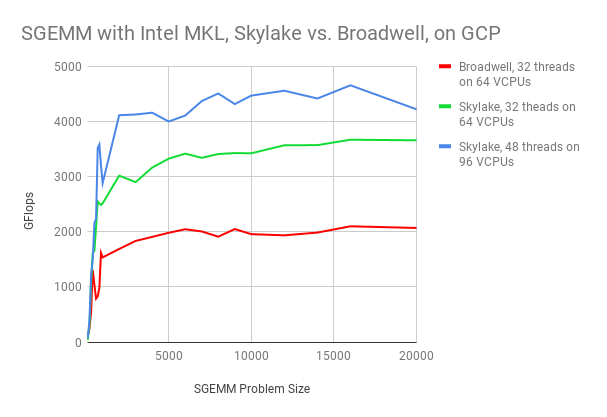
As one of the world's largest gaming companies, Ubisoft faced a problem that challenges many enterprises: a data store so big it was difficult and time-consuming to analyze. “Data took between fifteen and thirty minutes to process,” explained Maxime Bosvieux, EMEA Ecommerce Director at Ubisoft. “This doesn’t sound like much, but the modern customer darts from website to website, and if you’re unable to provide them with the experience they’re looking for, when they’re looking for it, they’ll choose the competitor who can.” That’s when they turned to Qubit and Google Cloud Platform.
A cloud native approach.
From early on, we made the decision to be an open ecosystem so as to provide our clients and partners with flexibility across technologies. When designing our system, we saw that the rise of cloud computing could transform not only how platform companies like ours process data, but also how they interface with customers. By providing Cloud-native APIs across the stack, our clients could seamlessly use open source tools and utilities with Qubit’s systems that run on GCP. Many of these tools interface with gsutil via the command-line, call BigQuery, or even upload to Cloud Storage buckets via CyberDuck.
We provision and provide our clients access to their own GCP project. The project contains all data processed and stored from their websites, apps and back-end data sources. Clients can then access both batch and streaming data, be it a user's predicted preferred category, a real-time calculation of lifetime value, or which customer segment the user belongs to. A client can access this data within seconds, regardless of their site’s traffic volume at that moment.
Bringing it all together for Ubisoft.
One of the first things Ubisoft realized is that they needed access to all of their data, regardless of the source. Qubit Live Tap gave Ubisoft access to the full take of their data via BigQuery (and through BI tools like Google Analytics and Looker). Our system manages all data processing and schema management, and reports out actionable next steps. This helps speed up the process of understanding the customer in order to provide better personalization. Using BigQuery’s scaling abilities, Live Tap generates machine learning and AI driven insights for clients like Ubisoft. This same system also lets them access their data in other BI and analytics tools such as Google Data Studio.
We grant access to clients like Ubisoft through a series of views in their project that point back to their master data store. The BigQuery IAM model (permissions provisioning for shared datasets) allows views to be authorized across multiple projects, removing the need to do batch copies between instances, which might cause some data to become stale. As Qubit streams data into the master tables, the views have direct access to it: analysts who perform queries in their own BigQuery project get access to the latest, real-time data.
Additionally, because the project provided is a complete GCP environment, clients like Ubisoft can also provision additional resources. We have clients who create their own Dataproc clusters, or import data provided by Qubit in BigQuery or via a PubSub topic to perform additional analysis and machine learning in a single environment. This process avoids the data wrangling problems commonly encountered in closed systems.
By combining Google Cloud Dataflow, Bigtable and BigQuery, we’re able to process vast amounts of data quickly and at petabyte-scale. During a typical month, Qubit’s platform will provide personalized experiences for more than 100 million users, surface 28 billion individual visitor experiences from ML-derived conclusions on customer data and use AI to simulate more than 2.3 billion customers journeys.
All of this made a lot of sense to Ubisoft. “We’re a company famous for innovating quickly and pushing the limits of what can be done,” Maxime Bosvieux told us. “That requires stable and robust technology that leverages the latest in artificial intelligence to build our segmentation and personalization strategies.”
Helping more companies move to the cloud with effective and efficient migrations.
We’re thrilled that the infrastructure we built with GCP has helped clients like Ubisoft scale data processing far beyond previous capabilities. Our integration into the GCP ecosystem is making this scalability even more attractive to organizations switching to the cloud. While porting data to a new provider can be daunting, we’re helping our clients make a more manageable leap to GCP.

















{kind=link}