By Brian Morgan, CTO, Catalant
[Editor’s Note: Today we hear from Catalant, an on-demand staffing provider that connects consultants and enterprises with a Software as a Service (SaaS) application that’s built on Google Cloud Platform (GCP). Using Jenkins, Google projects and service accounts, Catalant was able to build a single shared environment across production, development and sales that was easy to manage and that satisfied its compliance and regulatory requirements].
If your organization provides a SaaS application, you probably have multiple environments: production of course, but also demo, test, staging and integration environments to support various use cases. From a management perspective, you want to share resources across all those environments so you have the least number of moving parts. But ease of management and robust security are often at odds. For security purposes, the best practice is a separate project for each environment where nothing is shared and there's complete isolation.
Here at Catalant, we approached this problem by taking a step back and understanding the requirements from different parts of the organization:
- Compliance: Each environment and its data needs to be secure and not be shared.
- Sales: We need an environment that lets us control the data, so that we can give a consistent, predictable demo.
- Development: We need an environment where we can test things before putting them into production.
- Engineering Management: We need continuous integration and continuous deployment (CI/CD). Also, developers should not be required to use GCP-specific tools.
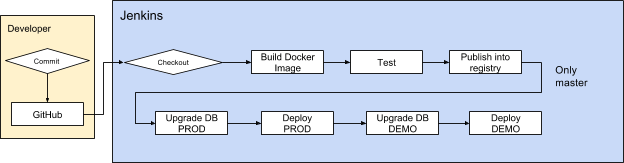
Based on these requirements, we elected to go with a single shared
Jenkins project to manage CI/CD activities for all the environments (test, demo, prod) that we may bring up, which satisfied developers and engineering management. Google Cloud’s concept of
projects, meanwhile, addressed the compliance team’s concerns with fortified boundaries that by default do not allow unauthorized traffic into the environment. Finally, we used
service accounts to allow projects to communicate with one another.
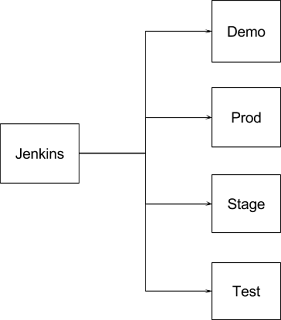 |
| Figure 2. Projects Layout |
We built this environment on
Google Compute Engine. And while it’s out of the scope of this article to show how to build this out on
Google Kubernetes Engine (formerly Container Engine), these resources can show you how to do it yourself:
Creating a service account
By default, when a developer creates a project, GCP also creates a default Compute Engine service account that you can use to access any of its own project resources as well as that of another project’s resources. We took advantage of this service account to access the Jenkins project resources.
We store all the images that we build with the Jenkins project in
Container Registry. We provided
“Storage Object Viewer” access for each project’s default service account so that the images can be deployed (via pull access) into an environment-specific project. In addition, to deploy the containers, we created a Jenkins service account that can authenticate into projects’ Kubernetes clusters for a specific namespace.
Here’s how to create a service account based on a
namespace:
Step1 - Create a service account:
kubectl create serviceaccount <sa-name> --namespace <ns-name></ns-name></sa-name>
This command creates a service account on the destination project. This service account will be used by Jenkins in order to authenticate into the destination cluster.
Step 2 - Verify the new service account:
kubectl get serviceaccount <sa-name> --namespace <ns-name> -o yaml</ns-name></sa-name>
This checks that the service account was successfully created, and outputs the service account details in a yaml format.
Step 3 - Get the secret name:
kubectl get sa <sa-name> -o json --namespace <ns-name> | jq -r .secrets[].name</ns-name></sa-name>
This retrieves the secret name associated with the service account created in Step 1.
Step 4 - Get the certificate:
kubectl get secret -o json --namespace <ns-name> | jq -r '.data["ca.crt"]' | base64 -d > ca.crt</ns-name></secret-name>
This gets the certificate details from the secret, decodes the certificate data and stores it into a file
ca.crt. The certificate
ca.crt will be used in order to authenticate into a cluster.
Step 5 - Get the token:
kubectl get secret <secret-name> -o json --namespace <ns-name> | jq -r '.data["token"]' | base64 -d</ns-name></secret-name>
This command gets the token from the secret and decodes the token to plain text. The token will be used in order to authenticate into the cluster.
Step 6 - Get the IP address of the cluster:
kubectl config view -o yaml | grep server
Allowing cross-project access
When Jenkins does a deploy, it needs to authenticate into each project's Kubernetes cluster. In the Jenkins application, we created the service account’s token and certificate as credentials. The steps below show how to authenticate into a different project, known as cross-project access.
Again, let’s explain what each step does:
Step 1 - Set a cluster entry in kubeconfig:
kubectl config set-cluster <cluster-name> --embed-certs=true --server=<cluster-ip> --certificate-authority=<path/to/certificate>
where
<cluster-name>can be any name --embed-certs=true embeds certs for the cluster entry in kubeconfig --server=<cluster-ip> is the cluster ip where we’re trying to authenticate, namely, the IP generated in Step 6 of the service account creation process --certificate-authority=<path certificate> is the certificate path and the certificate is the certificate file we generated in Step 4 of service account creation section above
Step 2 - Set the user entry in kubeconfig:
kubectl config set-credentials --token=
where
<credentials-name> can be any name --token=<token-value> is the token value that was decoded during Step 5 of the previous section
Step 3- Set the context entry in kubeconfig:
kubectl config set-context <context-name> --cluster=<cluster-name> --user=<credentials-name> --namespace=<ns-name></ns-name></credentials-name></cluster-name></context-name>
where
<context-name>can be any name --cluster=<cluster-name> is the cluster name set up in Step 1 above--user=<credentials-name> is the credentials name set up in Step 2 above --namespace=<ns-name> - the namespace name we like to interact with.
Step 4 - Set the current-context in a kubeconfig file:
kubectl config use-context <context-name>
Where
<context-name> is the context name that we created in
Step 3 above.
After setting up the context, we’re ready to access the destination project cluster. All the kubectl commands will be executed against the destination project cluster. A simple test to verify that we're accessing the destination project cluster successfully is to check for pods.
kubectl get pods -n <ns-name>
If the output pods’ list shown is the list of the destination project pods, then you set up the configuration correctly. All the Kubernetes commands are associated to the destination project.
In this setup, bringing up new environments is quick and easy since the Jenkins environment doesn’t have to be re-created or copied for each Google project. Of course, it does create a single point of failure and a shared resource. It’s important to configure Jenkins correctly, so that work from a single environment can’t starve out the rest. Make sure you have enough resources for the workers and limit the number of builds per branch to one
— that way multiple commits in quick succession to a branch can’t overload the infrastructure.
All told, the combination of Jenkins for CI/CD plus Google Cloud projects and service accounts give us the best of both worlds: a single shared environment that uses resources efficiently and is easy to manage, plus the security and isolation that our compliance and sales teams demanded. If you have questions or comments about this environment, reach out to us. And for more information, visit
GoCatalant.com.