Many customers of Kubernetes Engine, especially enterprises, need to autoscale their environments based on more than just CPU usage—for example queue length or concurrent persistent connections. In Kubernetes Engine 1.9 we started adding features to address this and today, with the latest beta release of Horizontal Pod Autoscaler (HPA) on Kubernetes Engine 1.10, you can configure your deployments to scale horizontally in a variety of ways.
To walk you through your different horizontal scaling options, meet Barbara, a DevOps engineer working at a global video-streaming company. Barbara runs her environment on Kubernetes Engine, including the following microservices:
- A video transcoding service that processes newly uploaded videos
- A Google Cloud Pub/Sub queue for the list of videos that the transcoding service needs to process
- A video-serving frontend that streams videos to users
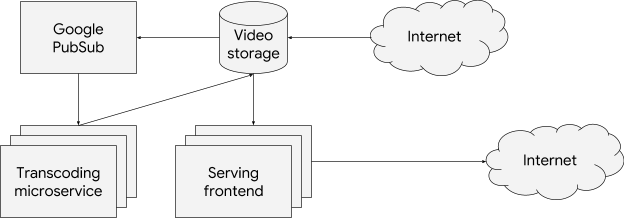 |
| A high-level diagram of Barbara’s application. |
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: transcoding-worker
namespace: video
spec:
minReplicas: 1
maxReplicas: 20
metrics:
- external:
metricName: pubsub.googleapis.com|subscription|num_undelivered_messages
metricSelector:
matchLabels:
resource.labels.subscription_id: transcoder_subscription
targetAverageValue: "10"
type: External
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: transcoding-worker |
| A high-level diagram of Barbara’s application showing the scaling bottleneck. |
Once the videos are transcoded, Barbara needs to ensure great viewing experience for her users. She identifies the bottleneck for the serving frontend: the number of concurrent persistent connections that a single replica can handle. Each of her pods already exposes its current number of open connections, so she configures the HPA object to maintain the average value of open connections per pod at a comfortable level. She does that using the Pods custom metric type.
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: frontend
namespace: video
spec:
minReplicas: 4
maxReplicas: 40
metrics:
- type: Pods
pods:
metricName: open_connections
targetAverageValue: 100
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontendIt is worth noting here that her pods expose the open_connections metric as an endpoint for Prometheus to monitor. Barbara uses the prometheus-to-sd sidecar to make those metrics available in Stackdriver. To do that, she adds the following YAML to her frontend deployment config. You can read more about different ways to export metrics and use them for autoscaling here.
containers:
...
- name: prometheus-to-sd
image: gcr.io/google-containers/prometheus-to-sd:v0.2.6
command:
- /monitor
- --source=:http://localhost:8080
- --stackdriver-prefix=custom.googleapis.com
- --pod-id=$(POD_ID)
- --namespace-id=$(POD_NAMESPACE)
env:
- name: POD_ID
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.uid
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace| A high-level diagram of Barbara’s application showing the new bottleneck due to CPU intensive live transcoding. |
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: frontend
namespace: video
spec:
minReplicas: 4
maxReplicas: 40
metrics:
- type: Pods
pods:
metricName: open_connections
targetAverageValue: 100
- type: Resource
resource:
name: cpu
targetAverageUtilization: 60
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontendTake it for a spin
Try Kubernetes Engine today with our generous 12-month free trial of $300 credits. Spin up a cluster (or a dozen) and experience the difference of running Kubernetes on Google Cloud, the cloud built for containers. And watch this space for future posts about how to use Cluster Autoscaler and Horizontal Pod Autoscaler together to make the most out of Kubernetes Engine.