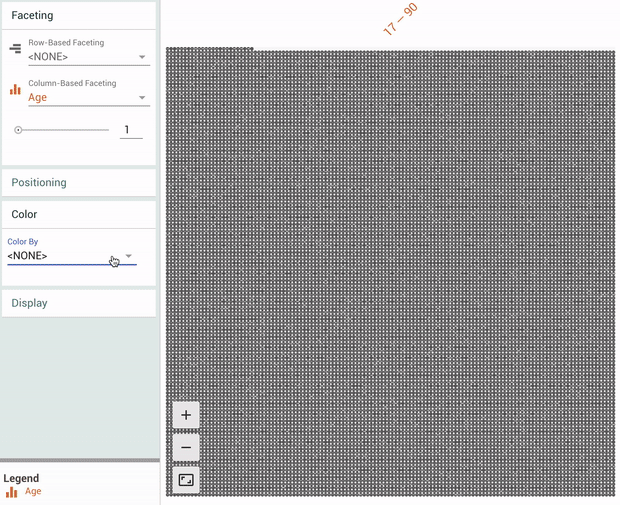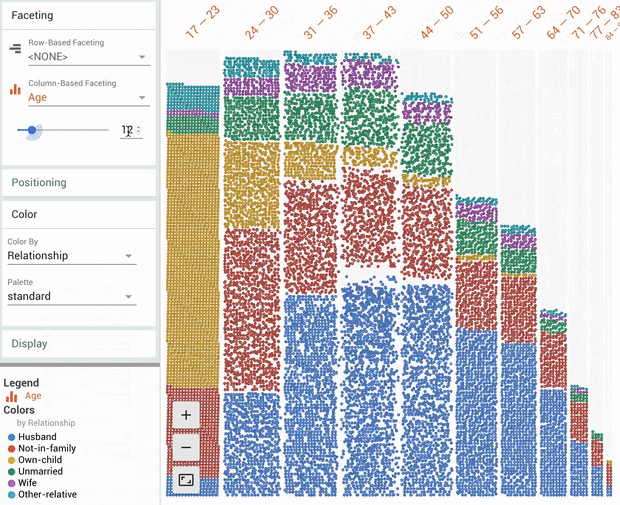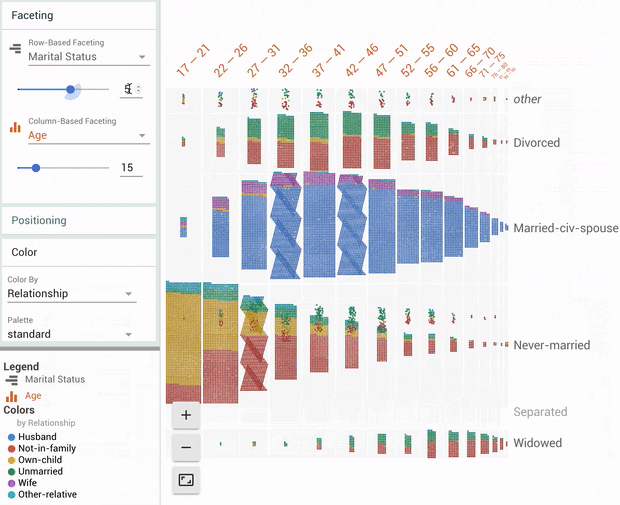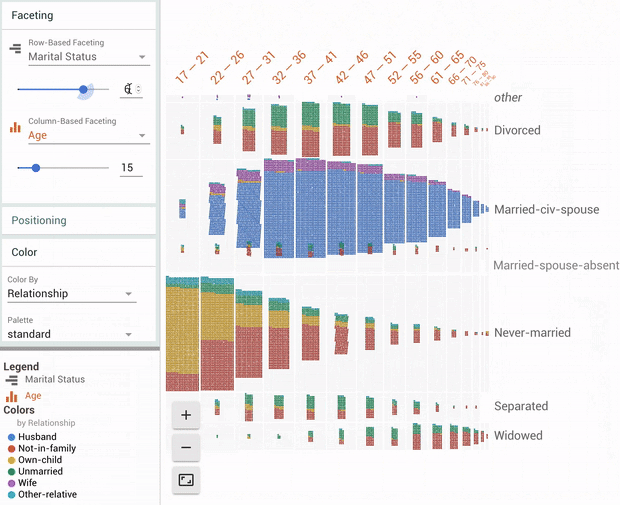
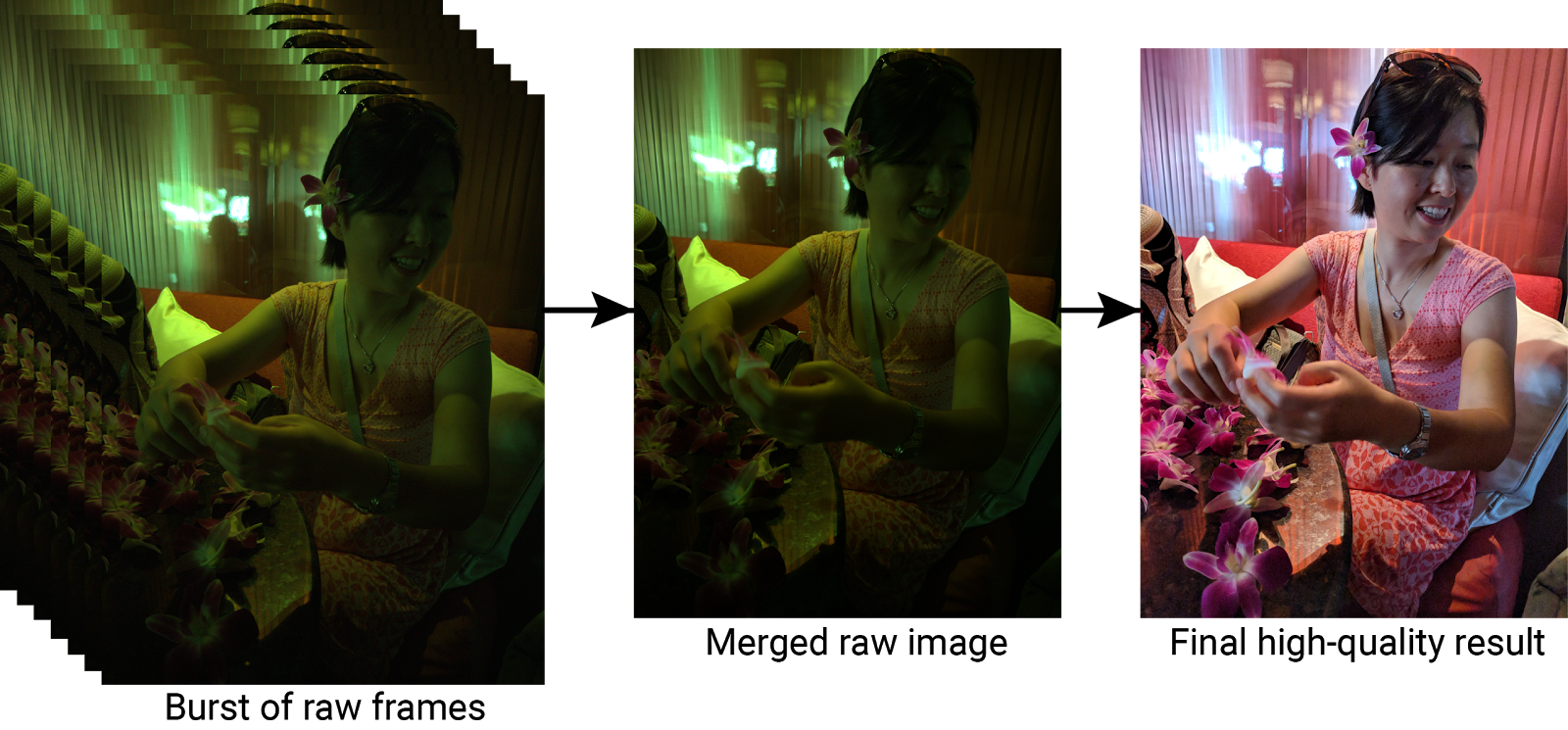Posted by Sam Hasinoff, Software Engineer, Machine Perception
Burst photography is the key idea underlying the HDR+ software on Google's recent smartphones, and a fundamental computational photography technique for improving image quality. Every photo taken with HDR+ is actually a composite, generated by capturing and merging a short burst of full-resolution photos. HDR+ has helped the Pixel and the Pixel 2 earn DxO's highest mobile camera ranking for two years in a row. The new portrait mode on the Pixel 2 also relies on HDR+, both for its basic image quality and to improve the quality of its depth estimation.
Today we're pleased to announce the public release of an archive of image bursts to the research community. This provides a way for others to compare their methods to the results of Google's HDR+ software running on the same input images. This dataset consists of 3,640 bursts of full-resolution raw images, made up of 28,461 individual images, along with HDR+ intermediate and final results for comparison. The images cover a wide range of photographic situations, including variation in subject, level of motion, brightness, and dynamic range.
Using bursts to improve image quality. HDR+ starts from a burst of full-resolution raw images (left). Depending on conditions, between 2 and 10 images are aligned and merged into an intermediate raw image (middle). This merged image has reduced noise and increased dynamic range, leading to a higher quality final result (right).
Better Images with Burst Photography Burst photography provides the benefits associated with collecting more light, including reduced noise and improved dynamic range, but it avoids the motion blur that would come from increasing exposure times. This is particularly important for small smartphone cameras, whose size otherwise limits the amount of light they can capture.
Since HDR+ was first released on Nexus 5 and 6, we've been busy improving the system. As described in our recent SIGGRAPH Asia paper, HDR+ now starts from raw images, which helps improve image quality. This also means that the image processing pipeline is fully implemented using our software. Next, we eliminated shutter lag, which makes photography feel instantaneous. The HDR+ photo you get corresponds to the moment the button was pressed. Finally, we improved processing times and power consumption, by implementing HDR+ on accelerators like the Qualcomm Hexagon DSP and the new Pixel Visual Core.
Mosaic of thumbnails illustrating the size and diversity of the HDR+ dataset. Putting a computational photography system like HDR+ into production, where users capture millions of photos per day, means that odd photographic corner cases must be handled in a robust way.
Using the Dataset The scale and diversity of the HDR+ dataset also opens up the opportunity to apply modern machine learning methods. Our dataset has already been incorporated in a recent research paper which uses a neural network to approximate part of the HDR+ pipeline, constrained to a representation suitable for fast image processing. Several more papers that apply learning to the HDR+ dataset are currently under review.
Inspired by the Middlebury archive of stereo data, our hope is that a shared dataset will enable the community to concentrate on comparing results. This approach is intrinsically more efficient than expecting researchers to configure and run competing techniques themselves, or to implement them from scratch if the code is proprietary. The HDR+ dataset is released under a Creative Commons license (CC-BY-SA). This license is largely unencumbered, however our main intention is that the dataset be used for scientific purposes. For information about how to cite the dataset, please see the detailed description. We look forward to seeing what else researchers can do with the HDR+ dataset!
Acknowledgments Special thanks to the photographers and subjects of the HDR+ dataset.
Posted by Jianing Wei and Tyler Mullen, Software Engineers, Google Research
Last summer, we launched Motion Stills on Android, which delivered a great video capture and viewing experience on a wide range of Android phones. Then, we refined our Motion Stills technology further to enable the new motion photos feature in Pixel 2.
Today, we are excited to announce the new Augmented Reality (AR) mode in Motion Stills for Android. With the new AR mode, a user simply touches the viewfinder to place fun, virtual 3D objects on static or moving horizontal surfaces (e.g. tables, floors, or hands), allowing them to seamlessly interact with a dynamic real-world environment. You can also record and share the clips as GIFs and videos.
Motion Stills with instant motion tracking in action
AR mode is powered by instant motion tracking, a six degree of freedom tracking system built upon the technology that powers Motion Text in Motion Stills iOS and the privacy blur on YouTube to accurately track static and moving objects. We refined and enhanced this technology to enable fun AR experiences that can run on any Android device with a gyroscope.
When you touch the viewfinder, Motion Stills AR “sticks” a 3D virtual object to that location, making it look as if it’s part of the real-world scene. By assuming that the tracked surface is parallel to the ground plane, and using the device’s accelerometer sensor to provide the initial orientation of the phone with respect to the ground plane, one can track the six degrees of freedom of the camera (3 for translation and 3 for rotation). This allows us to accurately transform and render the virtual object within the scene.
When the phone is approximately steady, the accelerometer sensor provides the acceleration due to the Earth’s gravity. For horizontal planes the gravity vector is parallel to normal of the tracked plane and can accurately provide the initial orientation of phone.
Instant Motion Tracking The core idea behind instant motion tracking is to decouple the camera’s translation and rotation estimation, treating them instead as independent optimization problems. First, we determine the 3D camera translation solely from the visual signal of the camera. To do this, we observe the target region's apparent 2D translation and relative scale across frames. A simple pinhole camera model relates both translation and scale of a box in the image plane with the final 3D translation of the camera.
The translation and the change in size (relative scale) of the box in the image plane can be used to determine 3D translation between two camera position C1 and C2. However, as our camera model doesn’t assume the focal length of the camera lens, we do not know the true distance/depth of the tracked plane.
To account for this, we added scale estimation to our existing tracker (the one used in Motion Text) as well as region tracking outside the field of view of the camera. When the camera gets closer to the tracked surface, the virtual content scales accurately, which is consistent with perception of real-world objects. When you pan outside the field of view of the target region and back the virtual object will reappear in approximately the same spot.
Independent translation (from visual signal only as shown by red box) and rotation tracking (from gyro; not shown)
After all this, we obtain the device’s 3D rotation (roll, pitch and yaw) using the phone’s built-in gyroscope. The estimated 3D translation combined with the 3D rotation provides us with the ability to render the virtual content correctly in the viewfinder. And because we treat rotation and translation separately, our instant motion tracking approach is calibration free and works on any Android device with a gyroscope.
Augmented chicken family with Motion Stills AR mode
We are excited to bring this new mode to Motion Stills for Android, and we hope you’ll enjoy it. Please download the new release of Motion Stills and keep sending us feedback with #motionstills on your favorite social media.
Acknowledgements For rendering, we are thankful we were able to leverage Google’s Lullaby engine using animated Poly models. A thank you to our team members who worked on the tech and this launch with us: John Nack, Suril Shah, Igor Kibalchich, Siarhei Kazakou, and Matthias Grundmann.
Posted by Jeff Dean, Google Senior Fellow, on behalf of the entire Google Brain Team
The Google Brain team works to advance the state of the art in artificial intelligence by research and systems engineering, as one part of the overall Google AI effort. In Part 1 of this blog post, we shared some of our work in 2017 related to our broader research, from designing new machine learning algorithms and techniques to understanding them, as well as sharing data, software, and hardware with the community. In this post, we’ll dive into the research we do in some specific domains such as healthcare, robotics, creativity, fairness and inclusion, as well as share a little more about us.
We have continued our work on early detection of diabetic retinopathy (DR) and macular edema, building on the research paper we published December 2016 in the Journal of the American Medical Association (JAMA). In 2017, we moved this project from research project to actual clinical impact. We partnered with Verily (a life sciences company within Alphabet) to guide this work through the regulatory process, and together we are incorporating this technology into Nikon's line of Optos ophthalmology cameras. In addition, we are working to deploy this system in India, where there is a shortage of 127,000 eye doctors and as a result, almost half of patients are diagnosed too late — after the disease has already caused vision loss. As a part of a pilot, we’ve launched this system to help graders at Aravind Eye Hospitals to better diagnose diabetic eye disease. We are also working with our partners to understand the human factors affecting diabetic eye care, from ethnographic studies of patients and healthcare providers, to investigations on how eye care clinicians interact with the AI-enabled system.
First patient screened (top) and Iniya Paramasivam, a trained grader, viewing the output of the system (bottom).
We have also teamed up with researchers at leading healthcare organizations and medical centers including Stanford, UCSF, and University of Chicago to demonstrate the effectiveness of using machine learning to predict medical outcomes from de-identified medical records (i.e. given the current state of a patient, we believe we can predict the future for a patient by learning from millions of other patients’ journeys, as a way of helping healthcare professionals make better decisions). We’re very excited about this avenue of work and we look to forward to telling you more about it in 2018.
Robotics Our long-term goal in robotics is to design learning algorithms to allow robots to operate in messy, real-world environments and to quickly acquire new skills and capabilities via learning, rather than the carefully-controlled conditions and the small set of hand-programmed tasks that characterize today’s robots. One thrust of our research is on developing techniques for physical robots to use their own experience and those of other robots to build new skills and capabilities, pooling the shared experiences in order to learn collectively. We are also exploring ways in which we can combine computer-based simulations of robotic tasks with physical robotic experience to learn new tasks more rapidly. While the physics of the simulator don’t entirely match up with the real world, we have observed that for robotics, simulated experience plus a small amount of real-world experience gives significantly better results than even large amounts of real-world experience on its own.
In addition to real-world robotic experience and simulated robotic environments, we have developed robotic learning algorithms that can learn by observing human demonstrations of desired behaviors, and believe that this imitation learning approach is a highly promising way of imparting new abilities to robots very quickly, without explicit programming or even explicit specification of the goal of an activity. For example, below is a video of a robot learning to pour from a cup in just 15 minutes of real world experience by observing humans performing this task from different viewpoints and then trying to imitate the behavior. As we might be with our own three-year-old child, we’re encouraged that it only spills a little!
We also co-organized and hosted the first occurrence of the new Conference on Robot Learning (CoRL) in November to bring together researchers working at the intersection of machine learning and robotics. The summary of the event contains more information, and we look forward to next year’s occurrence of the conference in Zürich.
Creativity We’re very interested in how to leverage machine learning as a tool to assist people in creative endeavors. This year, we created an AI piano duet tool, helped YouTube musician Andrew Huang create new music (see also the behind the scenes video with Nat & Friends), and showed how to teach machines to draw.
We also demonstrated how to control deep generative models running in the browser to create new music. This work won the NIPS 2017 Best Demo Award, making this the second year in a row that members of the Brain team’s Magenta project have won this award, following on our receipt of the NIPS 2016 Best Demo Award for Interactive musical improvisation with Magenta. In the YouTube video below, you can listen to one part of the demo, the MusicVAE variational autoencoder model morphing smoothly from one melody to another. People + AI Research (PAIR) Initiative Advances in machine learning offer entirely new possibilities for how people might interact with computers. At the same time, it’s critical to make sure that society can broadly benefit from the technology we’re building. We see these opportunities and challenges as an urgent matter, and teamed up with a number of people throughout Google to create the People + AI Research (PAIR) initiative.
PAIR’s goal is to study and design the most effective ways for people to interact with AI systems. We kicked off the initiative with a public symposium bringing together academics and practitioners across disciplines ranging from computer science, design, and even art. PAIR works on a wide range of topics, some of which we’ve already mentioned: helping researchers understand ML systems through work on interpretability and expanding the community of developers with deeplearn.js. Another example of our human-centered approach to ML engineering is the launch of Facets, a tool for visualizing and understanding training datasets.
Facets provides insights into your training datasets.
Cultural differences can surface in training data even in objects as “universal” as chairs, as observed in these doodle patterns on the left. The chart on the right shows how we uncovered geo-location biases in standard open source data sets such as ImageNet. Undetected or uncorrected, such biases may strongly influence model behavior.
We made this video in collaboration with our colleagues at Google Creative Lab as a non-technical introduction to some of the issues in this area. Our Culture One aspect of our group’s research culture is to empower researchers and engineers to tackle the basic research problems that they view as most important. In September, we posted about our general approach to conducting research. Educating and mentoring young researchers is something we do through our research efforts. Our group hosted over 100 interns last year, and roughly 25% of our research publications in 2017 have intern co-authors. In 2016, we started the Google Brain Residency, a program for mentoring people who wanted to learn to do machine learning research. In the inaugural year (June 2016 to May 2017), 27 residents joined our group, and we posted updates about the first year of the program in halfway through and just after the end highlighting the research accomplishments of the residents. Many of the residents in the first year of the program have stayed on in our group as full-time researchers and research engineers, and most of those that did not have gone on to Ph.D. programs at top machine learning graduate programs like Berkeley, CMU, Stanford, NYU and Toronto. In July, 2017, we also welcomed our second cohort of 35 residents, who will be with us until July, 2018, and they’ve already done some exciting research and published at numerous research venues. We’ve now broadened the program to include many other research groups across Google and renamed it the Google AI Residency program (the application deadline for this year's program has just passed; look for information about next year's program at g.co/airesidency/apply).
Our work in 2017 spanned more than we’ve highlighted on in this two-part blog post. We believe in publishing our work in top research venues, and last year our group published 140 papers, including more than 60 at ICLR, ICML, and NIPS. To learn more about our work, you can peruse our research papers.
The Google Brain team is becoming more spread out, with team members across North America and Europe. If the work we’re doing sounds interesting and you’d like to join us, you can see our open positions and apply for internships, the AI Residency program, visiting faculty, or full-time research or engineering roles using the links at the bottom of g.co/brain. You can also follow our work throughout 2018 here on the Google Research blog, or on Twitter at @GoogleResearch. You can also follow my personal account at @JeffDean.
Posted by Jeff Dean, Google Senior Fellow, on behalf of the entire Google Brain Team
The Google Brain team works to advance the state of the art in artificial intelligence by research and systems engineering, as one part of the overall Google AI effort. Last year we shared a summary of our work in 2016. Since then, we’ve continued to make progress on our long-term research agenda of making machines intelligent, and have collaborated with a number of teams across Google and Alphabet to use the results of our research to improve people’s lives. This first of two posts will highlight some of our work in 2017, including some of our basic research work, as well as updates on open source software, datasets, and new hardware for machine learning. In the second post we’ll dive into the research we do in specific domains where machine learning can have a large impact, such as healthcare, robotics, and some areas of basic science, as well as cover our work on creativity, fairness and inclusion and tell you a bit more about who we are.
Core Research A significant focus of our team is pursuing research that advances our understanding and improves our ability to solve new problems in the field of machine learning. Below are several themes from our research last year.
AutoML The goal of automating machine learning is to develop techniques for computers to solve new machine learning problems automatically, without the need for human machine learning experts to intervene on every new problem. If we’re ever going to have truly intelligent systems, this is a fundamental capability that we will need. We developed new approaches for designing neural network architectures using both reinforcement learning and evolutionary algorithms, scaled this work to state-of-the-art results on ImageNet classification and detection, and also showed how to learn new optimization algorithms and effective activation functions automatically. We are actively working with our Cloud AI team to bring this technology into the hands of Google customers, as well as continuing to push the research in many directions.
Speech Understanding and Generation Another theme is on developing new techniques that improve the ability of our computing systems to understand and generate human speech, including our collaboration with the speech team at Google to develop a number of improvements for an end-to-end approach to speech recognition, which reduces the relative word error rate over Google’s production speech recognition system by 16%. One nice aspect of this work is that it required many separate threads of research to come together (which you can find on Arxiv: 1, 2, 3, 4, 5, 6, 7, 8, 9).
We also collaborated with our research colleagues on Google’s Machine Perception team to develop a new approach for performing text-to-speech generation (Tacotron 2) that dramatically improves the quality of the generated speech. This model achieves a mean opinion score (MOS) of 4.53 compared to a MOS of 4.58 for professionally recorded speech like you might find in an audiobook, and 4.34 for the previous best computer-generated speech system. You can listen for yourself.
New Machine Learning Algorithms and Approaches We continued to develop novel machine learning algorithms and approaches, including work on capsules (which explicitly look for agreement in activated features as a way of evaluating many different noisy hypotheses when performing visual tasks), sparsely-gated mixtures of experts (which enable very large models that are still computational efficient), hypernetworks (which use the weights of one model to generate weights for another model), new kinds of multi-modal models (which perform multi-task learning across audio, visual, and textual inputs in the same model), attention-based mechanisms (as an alternative to convolutional and recurrent models), symbolic and non-symbolic learned optimization methods, a technique to back-propagate through discrete variables, and a few new reinforcementlearning algorithmic improvements.
Understanding Machine Learning Systems While we have seen impressive results with deep learning, it is important to understand why it works, and when it won’t. In another one of the best paper awards of ICLR 2017, we showed that current machine learning theoretical frameworks fail to explain the impressive results of deep learning approaches. We also showed that the “flatness” of minima found by optimization methods is not as closely linked to good generalization as initially thought. In order to better understand how training proceeds in deep architectures, we published a series of papers analyzing randommatrices, as they are the starting point of most training approaches. Another important avenue to understand deep learning is to better measure their performance. We showed the importance of good experimental design and statistical rigor in a recent study comparing many GAN approaches that found many popular enhancements to generative models do not actually improve performance. We hope this study will give an example for other researchers to follow in making robust experimental studies.
We are developing methods that allow better interpretability of machine learning systems. And in March, in collaboration with OpenAI, DeepMind, YC Research and others, we announced the launch of Distill, a new online open science journal dedicated to supporting human understanding of machine learning. It has gained a reputation for clear exposition of machine learning concepts and for excellent interactive visualization tools in its articles. In its first year, Distill has published manyilluminatingarticles aimed at understanding the inner working of various machine learning techniques, and we look forward to the many more sure to come in 2018.
Open Datasets for Machine Learning Research Open datasets like MNIST, CIFAR-10, ImageNet, SVHN, and WMT have pushed the field of machine learning forward tremendously. Our team and Google Research as a whole have been active in open-sourcing interesting new datasets for open machine learning research over the past year or so, by providing access to more large labeled datasets including:
YouTube-8M: >7 million YouTube videos annotated with 4,716 different classes
Examples from the YouTube-Bounding Boxes dataset: Video segments sampled at 1 frame per second, with bounding boxes successfully identified around the items of interest.
TensorFlow and Open Source Software
A map showing the broad distribution of TensorFlow users (source)
Throughout our team’s history, we have built tools that help us to conduct machine learning research and deploy machine learning systems in Google’s many products. In November 2015, we open-sourced our second-generation machine learning framework, TensorFlow, with the hope of allowing the machine learning community as a whole to benefit from our investment in machine learning software tools. In February, we released TensorFlow 1.0, and in November, we released v1.4 with these significant additions: Eager execution for interactive imperative-style programming, XLA, an optimizing compiler for TensorFlow programs, and TensorFlow Lite, a lightweight solution for mobile and embedded devices. The pre-compiled TensorFlow binaries have now been downloaded more than 10 million times in over 180 countries, and the source code on GitHub now has more than 1,200 contributors.
In February, we hosted the first ever TensorFlow Developer Summit, with over 450 people attending live in Mountain View and more than 6,500 watching on live streams around the world, including at more than 85 local viewing events in 35 countries. All talks were recorded, with topics ranging from new features, techniques for using TensorFlow, or detailed looks under the hoods at low-level TensorFlow abstractions. We’ll be hosting another TensorFlow Developer Summit on March 30, 2018 in the Bay Area. Sign up now to save the date and stay updated on the latest news.
In November, TensorFlow celebrated its second anniversary as an open-source project. It has been incredibly rewarding to see a vibrant community of TensorFlow developers and users emerge. TensorFlow is the #1 machine learning platform on GitHub and one of the top five repositories on GitHub overall, used by many companies and organizations, big and small, with more than 24,500 distinct repositories on GitHub related to TensorFlow. Many research papers are now published with open-source TensorFlow implementations to accompany the research results, enabling the community to more easily understand the exact methods used and to reproduce or extend the work.
TensorFlow has also benefited from other Google Research teams open-sourcing related work, including TF-GAN, a lightweight library for generative adversarial models in TensorFlow, TensorFlow Lattice, a set of estimators for working with lattice models, as well as the TensorFlow Object Detection API. The TensorFlow model repository continues to grow with an ever-widening set of models.
In addition to TensorFlow, we released deeplearn.js, an open-source hardware-accelerated implementation of deep learning APIs right in the browser (with no need to download or install anything). The deeplearn.js homepage has a number of great examples, including Teachable Machine, a computer vision model you train using your webcam, and Performance RNN, a real-time neural-network based piano composition and performance demonstration. We’ll be working in 2018 to make it possible to deploy TensorFlow models directly into the deeplearn.js environment.
TPUs
Cloud TPUs deliver up to 180 teraflops of machine learning acceleration
About five years ago, we recognized that deep learning would dramatically change the kinds of hardware we would need. Deep learning computations are very computationally intensive, but they have two special properties: they are largely composed of dense linear algebra operations (matrix multiples, vector operations, etc.), and they are very tolerant of reduced precision. We realized that we could take advantage of these two properties to build specialized hardware that can run neural network computations very efficiently. We provided design input to Google’s Platforms team and they designed and produced our first generation Tensor Processing Unit (TPU): a single-chip ASIC designed to accelerate inference for deep learning models (inference is the use of an already-trained neural network, and is distinct from training). This first-generation TPU has been deployed in our data centers for three years, and it has been used to power deep learning models on every Google Search query, for Google Translate, for understanding images in Google Photos, for the AlphaGo matches against Lee Sedol and Ke Jie, and for many other research and product uses. In June, we published a paper at ISCA 2017, showing that this first-generation TPU was 15X - 30X faster than its contemporary GPU or CPU counterparts, with performance/Watt about 30X - 80X better.
Cloud TPU Pods deliver up to 11.5 petaflops of machine learning acceleration
Inference is important, but accelerating the training process is an even more important problem - and also much harder. The faster researchers can try a new idea, the more breakthroughs we can make. Our second-generation TPU, announced at Google I/O in May, is a whole system (custom ASIC chips, board and interconnect) that is designed to accelerate both training and inference, and we showed a single device configuration as well as a multi-rack deep learning supercomputer configuration called a TPU Pod. We announced that these second generation devices will be offered on the Google Cloud Platform as Cloud TPUs. We also unveiled the TensorFlow Research Cloud (TFRC), a program to provide top ML researchers who are committed to sharing their work with the world to access a cluster of 1,000 Cloud TPUs for free. In December, we presented work showing that we can train a ResNet-50 ImageNet model to a high level of accuracy in 22 minutes on a TPU Pod as compared to days or longer on a typical workstation. We think lowering research turnaround times in this fashion will dramatically increase the productivity of machine learning teams here at Google and at all of the organizations that use Cloud TPUs. If you’re interested in Cloud TPUs, TPU Pods, or the TensorFlow Research Cloud, you can sign up to learn more at g.co/tpusignup. We’re excited to enable many more engineers and researchers to use TPUs in 2018!
Thanks for reading!
(In part 2 we’ll discuss our research in the application of machine learning to domains like healthcare, robotics, different fields of science, and creativity, as well as cover our work on fairness and inclusion.)
Posted by Michele Covell, Research Scientist, Google Research
Image compression is critical to digital photography — without it, a 12 megapixel image would take 36 megabytes of storage, making most websites prohibitively large. While the signal-processing community has significantly improved image compression beyond JPEG (which was introduced in the 1980’s) with modern image codecs (e.g., BPG, WebP), many of the techniques used in these modern codecs still use the same family of pixel transforms as are used in JPEG. Multiple recent Google projects improve the field of image compression with end-to-end with machine learning, compression through superresolution and creating perceptually improved JPEG images, but we believe that even greater improvements to image compression can be obtained by bringing this research challenge to the attention of the larger machine learning community.
To encourage progress in this field, Google, in collaboration with ETH and Twitter, is sponsoring the Workshop and Challenge on Learned Image Compression (CLIC) at the upcoming 2018 Computer Vision and Pattern Recognition conference (CVPR 2018). The workshop will bring together established contributors to traditional image compression with early contributors to the emerging field of learning-based image compression systems. Our invited speakers include image and video compression experts Jim Bankoski (Google) and Jens Ohm (RWTH Aachen University), as well as computer vision and machine learning experts with experience in video and image compression, Oren Rippel (WaveOne) and Ramin Zabih (Google, on leave from Cornell).
Training set of 1,633 uncompressed images from both the Mobile and Professional datasets, available on compression.cc
A database of copyright-free, high-quality images will be made available both for this challenge and in an effort to accelerate research in this area: Dataset P (“professional”) and Dataset M (“mobile”). The datasets are collected to be representative for images commonly used in the wild, containing thousands of images. While the challenge will allow participants to train neural networks or other methods on any amount of data (but we expect participants to have access to additional data, such as ImageNet and the Open Images Dataset), it should be possible to train on the datasets provided.
The first large-image compression systems using neural networks were published in 2016 [Toderici2016, Ballé2016] and were only just matching JPEG performance. More recent systems have made rapid advances, to the point that they match or exceed the performance of modern industry-standard image compression [Ballé2017, Theis2017, Agustsson2017, Santurkar2017, Rippel2017]. This rapid advance in the quality of neural-network-based compression systems, based on the work of a comparatively small number of research labs, leads us to expect even more impressive results when the area is explored by a larger portion of the machine-learning community.
We hope to get your help advancing the state-of-the-art in this important application area, and we encourage you to participate if you are planning to attend CVPR this year! Please see compression.cc for more details about the new datasets and important workshop deadlines. Training data is already available on that site. The test set will be released on February 15 and the deadline for submitting the compressed versions of the test set is February 22.
Posted by Enrique Alfonseca, Staff Research Scientist, Google Assistant
Voice interactions with technology are becoming a key part of our lives — from asking your phone for traffic conditions to work to using a smart device at home to turn on the lights or play music. The Google Assistant is designed to provide help and information across a variety of platforms, and is built to bring together a number of products — including Google Maps, Search, Google Photos, third party services, and more. For some of these products, we have released specific evaluation guidelines, like Search Quality Rating Guidelines. However, the Google Assistant needs its own guidelines in place, as many of its interactions utilize what is called “eyes-free technology,” when there is no screen as part of the experience.
In the past we have received requests to see our evaluation guidelines from academics who are researching improvements in voice interactions, question answering and voice-guided exploration. To facilitate their evaluations, we are publishing some of the first Google Assistant guidelines. It is our hope that making these guidelines public will help the research community build and evaluate their own systems. Creating the Guidelines For many queries, responses are presented on the display (like a phone) with a graph, a table, or an interactive element, like you’d see for [weather this weekend].
But spoken responses are very different from display results, as what’s on screen needs to be translated into useful speech. Furthermore, the contents of the voice response are sometimes sourced from the web, and in those cases it’s important to provide the user with a link to the original source. While users looking at their mobile device can click through to read the original web page, an eyes free solution presents unique challenges. In order to generate the optimal audio response, we use a combination of explicit linguistic knowledge and deep learning solutions that allow us to keep answers grammatical, fluent and concise.
How do we ensure that we consistently meet user expectations on quality, across all answer types and languages? One of the tools we use to measure that are human evaluations. In these, we ask raters to make sure that answers are satisfactory across several dimensions:
Information Satisfaction: the content of the answer should meet the information needs of the user.
Length: when a displayed answer is too long, users can quickly scan it visually and locate the relevant information. For voice answers, that is not possible. It is much more important to ensure that we provide a helpful amount of information, hopefully not too much or too little. Some of our previous work is currently in use for identifying the most relevant fragments of answers.
Formulation: it is much easier to understand a badly formulated written answer than an ungrammatical spoken answer, so more care has to be placed in ensuring grammatical correctness.
Elocution: spoken answers must have proper pronunciation and prosody. Improvements in text-to-speech generation, such as WaveNet and Tacotron 2, are quickly reducing the gap with human performance.
The current version of the guidelines can be found here. Of course, guidelines are often updated, and these are just a snapshot of something that is a living, changing, always-work-in-progress evaluation!
Posted by Jonathan Shen and Ruoming Pang, Software Engineers, on behalf of the Google Brain and Machine Perception Teams
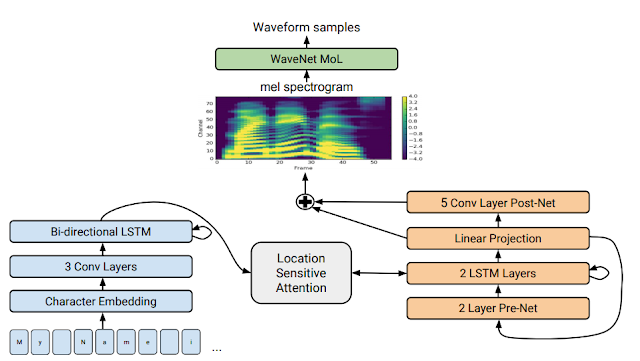
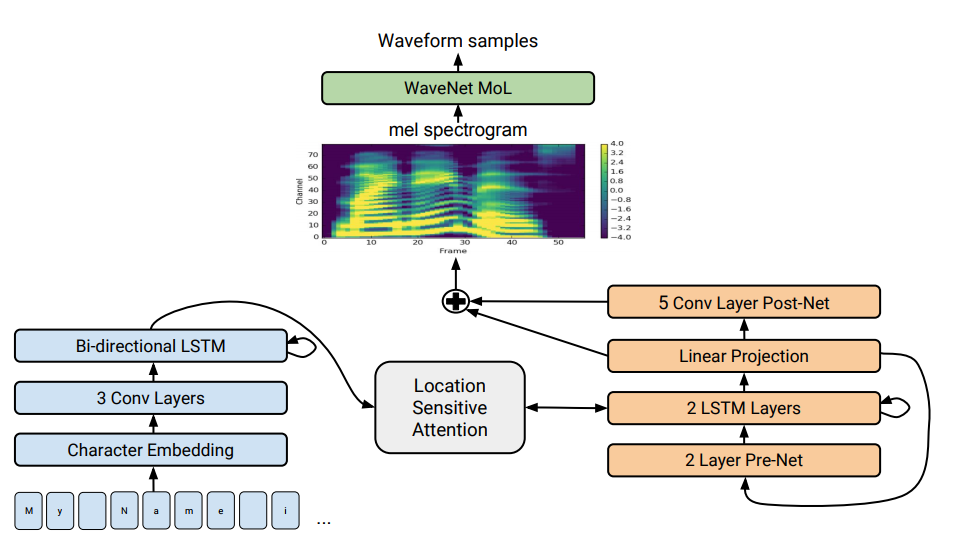
Generating very natural sounding speech from text (text-to-speech, TTS) has been a research goal for decades. There has been great progress in TTS research over the last few years and many individual pieces of a complete TTS system have greatly improved. Incorporating ideas from past work such as Tacotron and WaveNet, we added more improvements to end up with our new system, Tacotron 2. Our approach does not use complex linguistic and acoustic features as input. Instead, we generate human-like speech from text using neural networks trained using only speech examples and corresponding text transcripts.
A full description of our new system can be found in our paper “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.” In a nutshell it works like this: We use a sequence-to-sequence model optimized for TTS to map a sequence of letters to a sequence of features that encode the audio. These features, an 80-dimensional audio spectrogram with frames computed every 12.5 milliseconds, capture not only pronunciation of words, but also various subtleties of human speech, including volume, speed and intonation. Finally these features are converted to a 24 kHz waveform using a WaveNet-like architecture.
A detailed look at Tacotron 2's model architecture. The lower half of the image describes the sequence-to-sequence model that maps a sequence of letters to a spectrogram. For technical details, please refer to the paper.
You can listen to some of the Tacotron 2 audio samples that demonstrate the results of our state-of-the-art TTS system. In an evaluation where we asked human listeners to rate the naturalness of the generated speech, we obtained a score that was comparable to that of professional recordings.
While our samples sound great, there are still some difficult problems to be tackled. For example, our system has difficulties pronouncing complex words (such as “decorum” and “merlot”), and in extreme cases it can even randomly generate strange noises. Also, our system cannot yet generate audio in realtime. Furthermore, we cannot yet control the generated speech, such as directing it to sound happy or sad. Each of these is an interesting research problem on its own.
Acknowledgements Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu, Sound Understanding team, TTS Research team, and TensorFlow team.
Posted by Hossein Talebi, Software Engineer and Peyman Milanfar Research Scientist, Machine Perception
Quantification of image quality and aesthetics has been a long-standing problem in image processing and computer vision. While technical quality assessment deals with measuring pixel-level degradations such as noise, blur, compression artifacts, etc., aesthetic assessment captures semantic level characteristics associated with emotions and beauty in images. Recently, deep convolutional neural networks (CNNs) trained with human-labelled data have been used to address the subjective nature of image quality for specific classes of images, such as landscapes. However, these approaches can be limited in their scope, as they typically categorize images to two classes of low and high quality. Our proposed method predicts the distribution of ratings. This leads to a more accurate quality prediction with higher correlation to the ground truth ratings, and is applicable to general images.
In “NIMA: Neural Image Assessment” we introduce a deep CNN that is trained to predict which images a typical user would rate as looking good (technically) or attractive (aesthetically). NIMA relies on the success of state-of-the-art deep object recognition networks, building on their ability to understand general categories of objects despite many variations. Our proposed network can be used to not only score images reliably and with high correlation to human perception, but also it is useful for a variety of labor intensive and subjective tasks such as intelligent photo editing, optimizing visual quality for increased user engagement, or minimizing perceived visual errors in an imaging pipeline.
Background In general, image quality assessment can be categorized into full-reference and no-reference approaches. If a reference “ideal” image is available, image quality metrics such as PSNR, SSIM, etc. have been developed. When a reference image is not available, “blind” (or no-reference) approaches rely on statistical models to predict image quality. The main goal of both approaches is to predict a quality score that correlates well with human perception. In a deep CNN approach to image quality assessment, weights are initialized by training on object classification related datasets (e.g. ImageNet), and then fine-tuned on annotated data for perceptual quality assessment tasks.
NIMA Typical aesthetic prediction methods categorize images as low/high quality. This is despite the fact that each image in the training data is associated to a histogram of human ratings, rather than a single binary score. A histogram of ratings is an indicator of overall quality of an image, as well as agreements among raters. In our approach, instead of classifying images a low/high score or regressing to the mean score, the NIMA model produces a distribution of ratings for any given image — on a scale of 1 to 10, NIMA assigns likelihoods to each of the possible scores. This is more directly in line with how training data is typically captured, and it turns out to be a better predictor of human preferences when measured against other approaches (more details are available in our paper).
Various functions of the NIMA vector score (such as the mean) can then be used to rank photos aesthetically. Some test photos from the large-scale database for Aesthetic Visual Analysis (AVA) dataset, as ranked by NIMA, are shown below. Each AVA photo is scored by an average of 200 people in response to photography contests. After training, the aesthetic ranking of these photos by NIMA closely matches the mean scores given by human raters. We find that NIMA performs equally well on other datasets, with predicted quality scores close to human ratings.
Ranking some examples labelled with the “landscape” tag from AVA dataset using NIMA. Predicted NIMA (and ground truth) scores are shown below each image.
NIMA scores can also be used to compare the quality of images of the same subject which may have been distorted in various ways. Images shown in the following example are part of the TID2013 test set, which contain various types and levels of distortions.
Ranking some examples from TID2013 dataset using NIMA. Predicted NIMA scores are shown below each image.
Perceptual Image Enhancement As we’ve shown in another recent paper, quality and aesthetic scores can also be used to perceptually tune image enhancement operators. In other words, maximizing NIMA score as part of a loss function can increase the likelihood of enhancing perceptual quality of an image. The following example shows that NIMA can be used as a training loss to tune a tone enhancement algorithm. We observed that the baseline aesthetic ratings can be improved by contrast adjustments directed by the NIMA score. Consequently, our model is able to guide a deep CNN filter to find aesthetically near-optimal settings of its parameters, such as brightness, highlights and shadows.
NIMA can be used as a training loss to enhance images. In this example, local tone and contrast of images is enhanced by training a deep CNN with NIMA as its loss. Test images are obtained from the MIT-Adobe FiveK dataset.
Looking Ahead Our work on NIMA suggests that quality assessment models based on machine learning may be capable of a wide range of useful functions. For instance, we may enable users to easily find the best pictures among many; or to even enable improved picture-taking with real-time feedback to the user. On the post-processing side, these models may be used to guide enhancement operators to produce perceptually superior results. In a direct sense, the NIMA network (and others like it) can act as reasonable, though imperfect, proxies for human taste in photos and possibly videos. We’re excited to share these results, though we know that the quest to do better in understanding what quality and aesthetics mean is an ongoing challenge — one that will involve continuing retraining and testing of our models.
Posted by Tara N. Sainath, Research Scientist, Speech Team and Yonghui Wu, Research Scientist, Google Brain Team
Traditional automatic speech recognition (ASR) systems, used for a variety of voice search applications at Google, are comprised of an acoustic model (AM), a pronunciation model (PM) and a language model (LM), all of which are independently trained, and often manually designed, on different datasets [1]. AMs take acoustic features and predict a set of subword units, typically context-dependent or context-independent phonemes. Next, a hand-designed lexicon (the PM) maps a sequence of phonemes produced by the acoustic model to words. Finally, the LM assigns probabilities to word sequences. Training independent components creates added complexities and is suboptimal compared to training all components jointly. Over the last several years, there has been a growing popularity in developing end-to-end systems, which attempt to learn these separate components jointly as a single system. While these end-to-end models have shown promising results in the literature [2, 3], it is not yet clear if such approaches can improve on current state-of-the-art conventional systems.
Today we are excited to share “State-of-the-art Speech Recognition With Sequence-to-Sequence Models [4],” which describes a new end-to-end model that surpasses the performance of a conventional production system [1]. We show that our end-to-end system achieves a word error rate (WER) of 5.6%, which corresponds to a 16% relative improvement over a strong conventional system which achieves a 6.7% WER. Additionally, the end-to-end model used to output the initial word hypothesis, before any hypothesis rescoring, is 18 times smaller than the conventional model, as it contains no separate LM and PM.
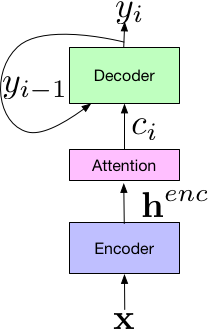
Our system builds on the Listen-Attend-Spell (LAS) end-to-end architecture, first presented in [2]. The LAS architecture consists of 3 components. The listener encoder component, which is similar to a standard AM, takes the a time-frequency representation of the input speech signal, x, and uses a set of neural network layers to map the input to a higher-level feature representation, henc. The output of the encoder is passed to an attender, which uses henc to learn an alignment between input features x and predicted subword units {yn, … y0}, where each subword is typically a grapheme or wordpiece. Finally, the output of the attention module is passed to the speller (i.e., decoder), similar to an LM, that produces a probability distribution over a set of hypothesized words.
Components of the LAS End-to-End Model.
All components of the LAS model are trained jointly as a single end-to-end neural network, instead of as separate modules like conventional systems, making it much simpler. Additionally, because the LAS model is fully neural, there is no need for external, manually designed components such as finite state transducers, a lexicon, or text normalization modules. Finally, unlike conventional models, training end-to-end models does not require bootstrapping from decision trees or time alignments generated from a separate system, and can be trained given pairs of text transcripts and the corresponding acoustics.
In [4], we introduce a variety of novel structural improvements, including improving the attention vectors passed to the decoder and training with longer subword units (i.e., wordpieces). In addition, we also introduce numerous optimization improvements for training, including the use of minimum word error rate training [5]. These structural and optimization improvements are what accounts for obtaining the 16% relative improvement over the conventional model.
Another exciting potential application for this research is multi-dialect and multi-lingual systems, where the simplicity of optimizing a single neural network makes such a model very attractive. Here data for all dialects/languages can be combined to train one network, without the need for a separate AM, PM and LM for each dialect/language. We find that these models work well on 7 english dialects [6] and 9 Indian languages [7], while outperforming a model trained separately on each individual language/dialect.
While we are excited by our results, our work is not done. Currently, these models cannot process speech in real time [8, 9], which is a strong requirement for latency-sensitive applications such as voice search. In addition, these models still compare negatively to production when evaluated on live production data. Furthermore, our end-to-end model is learned on 22,000 audio-text pair utterances compared to a conventional system that is typically trained on significantly larger corpora. In addition, our proposed model is not able to learn proper spellings for rarely used words such as proper nouns, which is normally performed with a hand-designed PM. Our ongoing efforts are focused now on addressing these challenges.
Acknowledgements This work was done as a strong collaborative effort between Google Brain and Speech teams. Contributors include Tara Sainath, Rohit Prabhavalkar, Bo Li, Kanishka Rao, Shankar Kumar, Shubham Toshniwal, Michiel Bacchiani and Johan Schalkwyk from the Speech team; as well as Yonghui Wu, Patrick Nguyen, Zhifeng Chen, Chung-cheng Chiu, Anjuli Kannan, Ron Weiss and Navdeep Jaitly from the Google Brain team. The work is described in more detail in papers [4-11]
Posted by Vincent Vanhoucke, Principal Scientist, Google Brain Team and Melanie Saldaña, Program Manager, University Relations
Whether in the form of autonomous vehicles, home assistants or disaster rescue units, robotic systems of the future will need to be able to operate safely and effectively in human-centric environments. In contrast to to their industrial counterparts, they will require a very high level of perceptual awareness of the world around them, and to adapt to continuous changes in both their goals and their environment. Machine learning is a natural answer to both the problems of perception and generalization to unseen environments, and with the recent rapid progress in computer vision and learning capabilities, applying these new technologies to the field of robotics is becoming a very central research question.
This past November, Google helped kickstart and host the first Conference on Robot Learning (CoRL) at our campus in Mountain View. The goal of CoRL was to bring machine learning and robotics experts together for the first time in a single-track conference, in order to foster new research avenues between the two disciplines. The sold-out conference attracted 350 researchers from many institutions worldwide, who collectively presented 74 original papers, along with 5 keynotes by some of the most innovative researchers in the field.
Prof. Sergey Levine, CoRL 2017 co-chair, answering audience questions.
Sayna Ebrahimi (UC Berkeley) presenting her research.