High profile open source vulnerabilities have made it clear that securing the supply chains underpinning modern software is an urgent, yet enormous, undertaking. As supply chains get more complicated, enterprise developers need to manage the tidal wave of vulnerabilities that propagate up through dependency trees. Open source maintainers need streamlined ways to vet proposed dependencies and protect their projects. A rise in attacks coupled with increasingly complex supply chains means that supply chain security problems need solutions on the ecosystem level.
One way developers can manage this enormous risk is by choosing a more secure language. As part of Google’s commitment to advancing cybersecurity and securing the software supply chain, Go maintainers are focused this year on hardening supply chain security, streamlining security information to our users, and making it easier than ever to make good security choices in Go.
This is the first in a series of blog posts about how developers and enterprises can secure their supply chains with Go. Today’s post covers how Go helps teams with the tricky problem of managing vulnerabilities in their open source packages.
Extensive Package Insights
Before adopting a dependency, it’s important to have high-quality information about the package. Seamless access to comprehensive information can be the difference between an informed choice and a future security incident from a vulnerability in your supply chain. Along with providing package documentation and version history, the Go package discovery site links to Open Source Insights. The Open Source Insights page includes vulnerability information, a dependency tree, and a security score provided by the OpenSSF Scorecard project. Scorecard evaluates projects on more than a dozen security metrics, each backed up with supporting information, and assigns the project an overall score out of ten to help users quickly judge its security stance (example). The Go package discovery site puts all these resources at developers’ fingertips when they need them most—before taking on a potentially risky dependency.
Curated Vulnerability Information
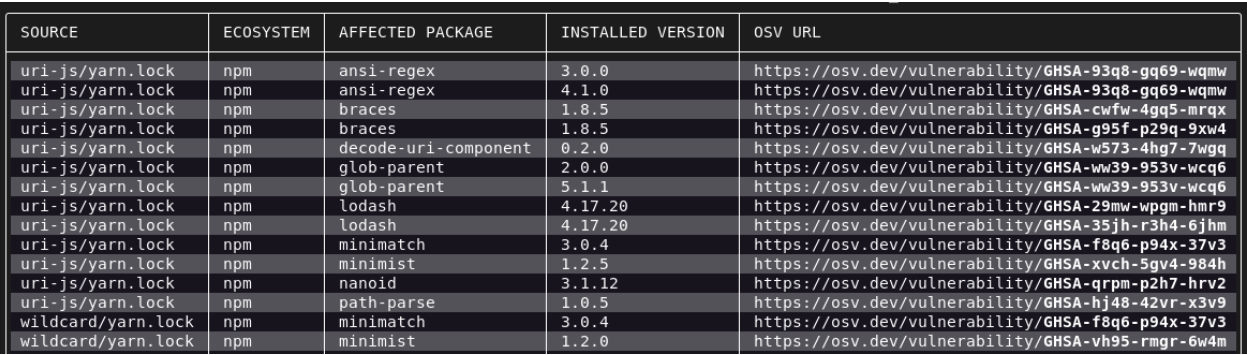
Large consumers of open source software must manage many packages and a high volume of vulnerabilities. For enterprise teams, filtering out noisy, low quality advisories and false positives from critical vulnerabilities is often the most important task in vulnerability management. If it is difficult to tell which vulnerabilities are important, it is impossible to properly prioritize their remediation. With granular advisory details, the Go vulnerability database removes barriers to vulnerability prioritization and remediation.
All vulnerability database entries are reviewed and curated by the Go security team. As a result, entries are accurate and include detailed metadata to improve the quality of vulnerability scans and to make vulnerability information more actionable. This metadata includes information on affected functions, operating systems, and architectures. With this information, vulnerability scanners can reduce the number of false positives using symbol information to filter out vulnerabilities that aren’t called by client code.
Consider the case of GO-2022-0646, which describes an unfixed vulnerability present in all versions of the package. It can only be triggered, though, if a particular, deprecated function is called. For the majority of users, this vulnerability is a false positive—but every user would need to spend time and effort to manually determine whether they’re affected if their vulnerability database doesn’t include function metadata. This amounts to enormous wasted effort that could be spent on more productive security efforts.
The Go vulnerability database streamlines this process by including accurate affected function level metadata for GO-2022-0646. Vulnerability scanners can then use static analysis to accurately determine if the project uses the affected function. Because of Go’s high quality metadata, a vulnerability such as this one can automatically be excluded with less frustration for developers, allowing them to focus on more relevant vulnerabilities. And for projects that do incorporate the affected function, Go’s metadata provides a remediation path: at the time of writing, it’s not possible to upgrade the package to fix the vulnerability, but you can stop using the vulnerable function. Whether or not the function is called, Go’s high quality metadata provides the user with the next step.
Entries in the Go vulnerability database are served as JSON files in the OSV format from vuln.go.dev. The OSV format is a minimal and precise industry-accepted reporting format for open source vulnerabilities that has coverage over 16 ecosystems. OSV treats open source as a first class citizen by including information specific to open source, like git commit hashes. The OSV format ensures that the vulnerability information is both machine readable and easy for developers to understand. That means that not only are the database entries easy to read and browse, but that the format is also compatible with automated tools like scanners. Go provides such a scanner that intelligently matches vulnerabilities to Go codebases.
Low noise, reliable vulnerability scanning
The Go team released a new command line tool, govulncheck, last September. Govulncheck does more than simply match dependencies to known vulnerabilities in the Go vulnerability database; it uses the additional metadata to analyze your project’s source code and narrow results to vulnerabilities that actually affect the application. This cuts down on false positives, reducing noise and making it easier to prioritize and fix issues.
You can run govulncheck as a command-line tool throughout your development process to see if a recent change introduced a new exploitable path. Fortunately, it’s easy to run govulncheck directly from your editor using the latest VS Code Go extension. Users have even incorporated govulncheck into their CI/CD pipeline. Finding new vulnerabilities early can help you fix them before they’re in production.
The Go team has been collaborating with the OSV team to bring source analysis capabilities to OSV-Scanner through a beta integration with govulncheck. OSV-Scanner is a general purpose, multi-ecosystem, vulnerability scanner that matches project dependencies to known vulnerabilities. Go vulnerabilities can now be marked as “unexecuted” thanks to govulncheck’s analysis.
Govulncheck is under active development, and the team appreciates feedback from users. Go package maintainers are also encouraged to contribute vulnerability reports to the Go vulnerability database.
Additionally, you can report a security bug in the Go project itself, following the Go Security Policy. These may be eligible for the Open Source Vulnerability Rewards Program, which gives financial rewards for vulnerabilities found in Google’s open source projects. These contributions improve security for all users and reports are always appreciated.
Security across the supply chain
Google is committed to helping developers use Go software securely across the end-to-end supply chain, connecting users to dependable data and tools throughout the development lifecycle. As supply chain complexities and threats continue to increase, Go’s mission is to provide the most secure development environment for software engineering at scale.
Our next installment in this series on supply chain security will cover how Go’s checksum database can help protect users from compromised dependencies. Watch for it in the coming weeks!


 On April 1, we’re welcoming the public to New York’s newest dining, cultural, and educational destination: Pier 57.
On April 1, we’re welcoming the public to New York’s newest dining, cultural, and educational destination: Pier 57.