By: Patrik Höglund Introduction
Software development is difficult. Projects often evolve over several years, under changing requirements and shifting market conditions, impacting developer tools and infrastructure. Technical debt, slow build systems, poor debuggability, and increasing numbers of dependencies can weigh down a project The developers get weary, and cobwebs accumulate in dusty corners of the code base.
Fighting these issues can be taxing and feel like a quixotic undertaking, but don’t worry — the Google Testing Blog is riding to the rescue! This is the first article of a series on “hackability” that identifies some of the issues that hinder software projects and outlines what Google SETIs usually do about them.
According to Wiktionary, hackable is defined as:
Adjectivehackable (comparative
more hackable, superlative
most hackable)
- (computing) That can be hacked or broken into; insecure, vulnerable.
- That lends itself to hacking (technical tinkering and modification); moddable.
Obviously, we’re not going to talk about making your product more vulnerable (by, say, rolling your own crypto or something equally unwise); instead, we will focus on the second definition, which essentially means “something that is easy to work on.” This has become the
mainfocus for SETIs at Google as the role has evolved over the years.
In Practice
In a hackable project, it’s easy to try things and hard to break things. Hackability means fast feedback cycles that offer useful information to the developer.
This is hackability:
- Developing is easy
- Fast build
- Good, fast tests
- Clean code
- Easy running + debugging
- One-click rollbacks
In contrast, what is not hackability?
- Broken HEAD (tip-of-tree)
- Slow presubmit (i.e. checks running before submit)
- Builds take hours
- Incremental build/link > 30s
- Flakytests
- Can’t attach debugger
- Logs full of uninteresting information
The Three Pillars of Hackability
There are a number of tools and practices that foster hackability. When everything is in place, it feels great to work on the product. Basically no time is spent on figuring out why things are broken, and all time is spent on what matters, which is understanding and working with the code. I believe there are three main pillars that support hackability. If one of them is absent, hackability will suffer. They are:
Pillar 1: Code Health
“I found Rome a city of bricks, and left it a city of marble.”
-- Augustus
Keeping the code in good shape is critical for hackability. It’s a lot harder to tinker and modify something if you don’t understand what it does (or if it’s full of hidden traps, for that matter).
Tests
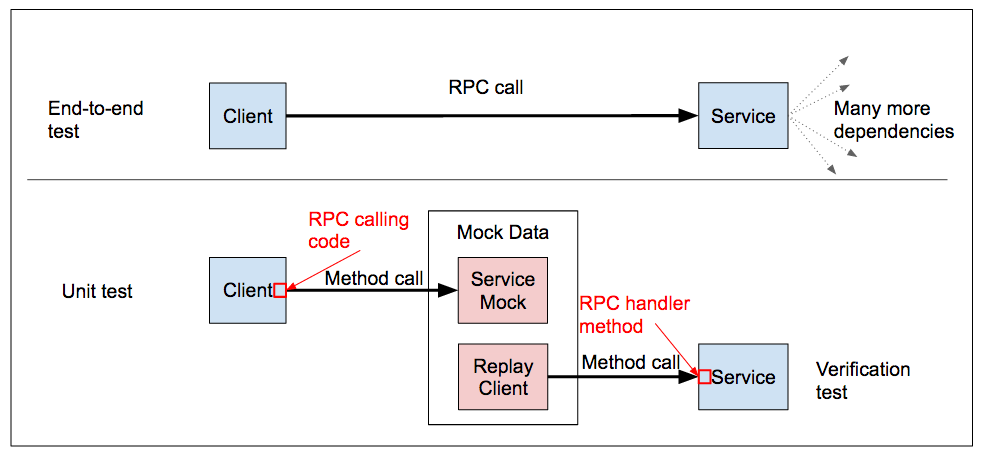
Unit and small integration tests are probably the best things you can do for hackability. They’re a support you can lean on while making your changes, and they contain lots of good information on what the code does. It isn’t hackability to boot a slow UI and click buttons on every iteration to verify your change worked - it is hackability to run a sub-second set of unit tests! In contrast, end-to-end (E2E) tests generally help hackability much less (and can
evenbe a hindrance if they, or the product, are in sufficiently bad shape).
Figure 1: the Testing Pyramid.
I’ve always been interested in how you actually make unit tests happen in a team. It’s about education. Writing a product such that it has good unit tests is actually a hard problem. It requires knowledge of dependency injection, testing/mocking frameworks, language idioms and refactoring. The difficulty varies by language as well. Writing unit tests in Go or Java is quite easy and natural, whereas in C++ it can be very difficult (and it isn’t exactly ingrained in C++ culture to write unit tests).
It’s important to educate your developers about unit tests. Sometimes, it is appropriate to lead by example and help review unit tests as well. You can have a large impact on a project by establishing a pattern of unit testing early. If tons of code gets written without unit tests, it will be much harder to add unit tests later.
What if you already have tons of poorly tested legacy code? The answer is refactoring and adding tests as you go. It’s hard work, but each line you add a test for is one more line that is easier to hack on.
Readable Code and Code Review
At Google, “readability” is a special committer status that is granted per language (C++, Go, Java and so on). It means that a person not only knows the language and its culture and idioms well, but also can write clean, well tested and well structured code. Readability literally means that you’re a guardian of Google’s code base and should push back on hacky and ugly code. The use of a
style guide enforces consistency, and
code review (where at least one person with readability must approve) ensures the code upholds high quality. Engineers must take care to not depend too much on “review buddies” here but really make sure to pull in the person that can give the best feedback.
Requiring code reviews naturally results in small changes, as reviewers often get grumpy if you dump huge changelists in their lap (at least if reviewers are somewhat fast to respond, which they should be). This is a good thing, since small changes are less risky and are easy to roll back. Furthermore, code review is good for knowledge sharing. You can also do pair programming if your team prefers that (a pair-programmed change is considered reviewed and can be submitted when both engineers are happy). There are multiple open-source review tools out there, such as
Gerrit.
Nice, clean code is great for hackability, since you don’t need to spend time to unwind that nasty pointer hack in your head before making your changes. How do you make all this happen in practice? Put together workshops on, say, the
SOLID principles, unit testing, or concurrency to encourage developers to learn. Spread knowledge through code review, pair programming and mentoring (such as with the Readability concept). You can’t just mandate higher code quality; it takes a lot of work, effort and consistency.
Presubmit Testing and Lint
Consistently formatted source code aids hackability. You can scan code faster if its formatting is consistent. Automated tooling also aids hackability. It really doesn’t make sense to waste any time on formatting source code by hand. You should be using tools like
gofmt,
clang-format, etc. If the patch isn’t formatted properly, you should see something like this (
example from Chrome):
$ git cl upload
Error: the media/audio directory requires formatting. Please run
git cl format media/audio.
Source formatting isn’t the only thing to check. In fact, you should check pretty much anything you have as a rule in your project. Should other modules not depend on the internals of your modules?
Enforce it with a check. Are there already inappropriate dependencies in your project? Whitelist the existing ones for now, but at least block new bad dependencies from forming. Should our app work on Android 16 phones and newer?
Add linting, so we don’t use level 17+ APIs without gating at runtime. Should your project’s
VHDL code always place-and-route cleanly on a particular brand of
FPGA? Invoke the layout tool in your presubmit and and stop submit if the layout process fails.
Presubmit is the most valuable real estate for aiding hackability. You have limited space in your presubmit, but you can get tremendous value out of it if you put the right things there. You should stop all obvious errors here.
It aids hackability to have all this tooling so you don’t have to waste time going back and breaking things for other developers. Remember you need to maintain the presubmit well; it’s not hackability to have a slow, overbearing or buggy presubmit. Having a good presubmit can make it tremendously more pleasant to work on a project. We’re going to talk more in later articles on how to build infrastructure for submit queues and presubmit.
Single Branch And Reducing Risk
Having a single branch for everything, and putting risky new changes behind
feature flags, aids hackability since branches and forks often amass tremendous risk when it’s time to merge them. Single branches smooth out the risk. Furthermore, running all your tests on many branches is expensive. However, a single branch can have negative effects on hackability if Team A depends on a library from Team B and gets broken by Team B a lot. Having some kind of stabilization on Team B’s software might be a good idea there.
Thisarticle covers such situations, and how to integrate often with your dependencies to reduce the risk that one of them will break you.
Loose Coupling and Testability
Tightly coupled code is terrible for hackability. To take the most ridiculous example I know: I once heard of a computer game where a developer changed a ballistics algorithm and broke the game’s
chat. That’s hilarious, but hardly intuitive for the poor developer that made the change. A hallmark of loosely coupled code is that it’s upfront about its dependencies and behavior and is easy to modify and move around.
Loose coupling, coherence and so on is really about design and architecture and is notoriously hard to measure. It really takes experience. One of the best ways to convey such experience is through code review, which we’ve already mentioned. Education on the SOLID principles, rules of thumb such as tell-don’t-ask, discussions about anti-patterns and code smells are all good here. Again, it’s hard to build tooling for this. You could write a presubmit check that forbids methods longer than 20 lines or cyclomatic complexity over 30, but that’s probably shooting yourself in the foot. Developers would consider that overbearing rather than a helpful assist.
SETIs at Google are expected to give input on a product’s testability. A few well-placed test hooks in your product can enable tremendously powerful testing, such as serving mock content for apps (this enables you to meaningfully test app UI without contacting your real servers, for instance). Testability can also have an influence on architecture. For instance, it’s a testability problem if your servers are built like a huge monolith that is slow to build and start, or if it can’t boot on localhost without calling external services. We’ll cover this in the next article.
Aggressively Reduce Technical Debt
It’s quite easy to add a lot of code and dependencies and call it a day when the software works. New projects can do this without many problems, but as the project becomes older it becomes a “legacy” project, weighed down by dependencies and excess code. Don’t end up there. It’s bad for hackability to have a slew of bug fixes stacked on top of unwise and obsolete decisions, and understanding and untangling the software becomes more difficult.
What constitutes technical debt varies by project and is something you need to learn from experience. It simply means the software isn’t in optimal form. Some types of technical debt are easy to classify, such as dead code and barely-used dependencies. Some types are harder to identify, such as when the architecture of the project has grown unfit to the task from changing requirements. We can’t use tooling to help with the latter, but we can with the former.
I already mentioned that
dependency enforcement can go a long way toward keeping people honest. It helps make sure people are making the appropriate trade-offs instead of just slapping on a new dependency, and it requires them to explain to a fellow engineer when they want to override a dependency rule. This can prevent unhealthy dependencies like circular dependencies, abstract modules depending on concrete modules, or modules depending on the internals of other modules.
There are various tools available for visualizing dependency graphs as well. You can use these to get a grip on your current situation and start cleaning up dependencies. If you have a huge dependency you only use a small part of, maybe you can replace it with something simpler. If an old part of your app has inappropriate dependencies and other problems, maybe it’s time to rewrite that part.
The next article will be on Pillar 2: Debuggability.